
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- How to crash your iflows and watch them failover b...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Martin-Pankraz
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-23-2020
3:35 PM
This is part 1 of a series discussing distributed scenarios for SAP Cloud Integration (CPI). Part 1: How to crash your iflows and watch them failover beautifully (DR for CPI with Azure FrontDoor) Part 2: Second round of crashing iFlows in CPI and failing over with Azure – even simpler (DR for CPI with Azure Traffic Manager) Part 3: Black Friday will take your CPI instance offline unless… (HA for CPI) |
Dear community,
Are you happy with redundant deployments in availability zones in a single cloud region? Are your iFlows down regularly due to CPI maintenance windows? Or are you striving for cross-region failovers? SAP deploys their CloudFoundry services for its multi-cloud environment (Azure, AWS, GCP and Alibaba) zone-redundantly. You can find the reference here.
There is nothing wrong with that. The approach is simple and cost efficient. But from resilient cloud architecture perspective it is often recommend to go one step further.
The scope of my post will be SCP Cloud Platform Integration but the approach is not limited to that.
Securing cloud workloads comes with many options
An even more reliable setup uses redundancy for high availability in the same region and a passive disaster recovery setup, that contains only the basic cloud landing zone, in another cloud region considerably far away. This way you keep the cost at bay but at the sacrifice of recovery time, because you need to provision services during the disaster first. An active setup profits from already running services but doubles the cost obviously.
You might even do this cross-cloud providers if you want.
A note on the side: Some of the very sophisticated customers that I saw, are even doing failovers with Azure deliberately once a year . They run the first half of the year in west- and the other in north-Europe. This way you ensure a well-understood CloudOps practice.
See down below a screenshot from the SAP on Azure reference architecture for S/4Hana for the mentioned setup.

Fig.1 Screenshot from SAP on Azure reference architecture docs
Great, due to above your precious backend can perform a failover to another region. But what happens to your connected SAP Cloud Platform services in that case? And specifically, your iFlows deployed on CPI?
Single instance CPI with S4 failover
It is likely you are in a situation depicted down below, where you configure a SAP Cloud Connector in each region and point them towards the same SCP Subaccount. For requests from SAP to SCP you are fine, but for the other way round you need to apply the Location ID concept, so that your iFlow knows which Cloud Connector to use.
Note on the side: Requests from SAP to SCP should go through a specified Internet breakout, because your SAP workload runs in a private VNet, that is only reachable via a gateway component for web traffic, VPN or ExpressRoute. For the sake of the CPI failover focus I simplified the described setup.

Fig.2 Overview of simple DR setup S4 and CPI
Congratulations, you just created a dependency in your iFlows on Cloud Connector Location ID ?Given that disaster recovery decisions are often manual human decisions, you should be fine with a simple parameter. To avoid redeploying a lot of iFlows I recommend to use a global variable instead of a String exposed as an externalized parameter.
Be aware that the global variable expires after 1 year, so you need to have a process to re-set it. Down below I detailed a possible approach to configure the Location ID dynamically from a global variable.
UPDATE: santhosh.kumarv rightfully pointed out on the comments that the Partner Directory Kit would be an even better solution than the variable to avoid data base requests. You can find additional guidance on how to set this up here.
| I created a simple iFlow that takes the location ID string that I want to activate on my CPI tenant from a header. I did that for simplicity reasons. You could also go for the payload the query string or even read from another service. |  |
| Once executed I see the global variable on the Monitoring UI |  |
| With that I can access the global variable in any iFlow in my tenant. I store it in a header again (could also be a property if you prefer that) to use it for the subsequent http call via the Cloud Connector |  |
| There you go. The Location Id is now being set dynamically from a global variable |  |
| The associated Destination for Cloud Connector looks like this. So, my authentication and Location ID come from the iFlow and the Destination just passes them on. |  |
| The Cloud Connector on the VM in my primary Azure region config contains the Location ID, that we need to match |  |
Table 1 Setup for global var on CPI tenant
In case a manual DR decision is not good enough you could start thinking to automate the process. I propose a service to check health status of your S4 backend. I have used the basic SAP Ping service for that purpose before. However, the devil is in the detail: At what point is the SAP backend considered not available anymore? 10 request failures within 5 minutes? 10 minutes? Did it failover to the DR side fully yet? Or is just something wrong with the Cloud Connector?

Fig.3 Screenshot of iFlow to automate change of dynamic Location ID

Fig.4 Overview ping-based failover with LocationID change
For above proposal you need means to determine the currently active SAP backend. This iFlow example assumes, that the active SAP system URL is stored globally like the Cloud Connector Location ID. It probes the S4 system on the ping service regularly. In case it fails it automatically changes the Location ID and active SAP URL to the secondary site on the CPI tenant. Voila, you just created a mess 😄
Obviously, you would want more checks like: how often did my probe fail in a given time frame? Maybe I should try a second time after 1 minute or so to to allow network latency issues to resolve? The Circuit-Breaker pattern is something I can recommend if you want to dig deeper in this direction.
Hey, and what about reversing this process once my primary instance becomes available again? Maybe manual failover is not so bad after all ?
That shall be it for an introduction to single instance SCP CPI with failover only on the SAP backend side. But I promised you cross region failover including CPI, right? But wait, my SAP backend configuration can only contain one target!
Reverse Proxy to the rescue
To enable dynamic failover of your integration scenarios from both S4 instances (primary and DR) to CPI (primary and DR) we need an abstraction layer. Otherwise you would need to change communication configuration on the backend when disaster happens. What we are looking for is a globally highly available component that acts as a reverse proxy, that can check the health of my CPI endpoints and start routing request from which ever S4 instance is currently active. I am using the managed services Azure Front Door (AFD) together with Azure API Management (APIM, consumption based) to achieve that. There are multiple other options that could achieve the same thing. For instance, on the Azure side you could look at a simple and cost-efficient DNS-based solution with Azure Traffic Manager (TM). Find a comparison of both solutions here and my second post on this topic specifically with AZure TM here.
I chose Front Door for its rich feature set (e.g Web Application Firewall and global availability) and quick failover reactions without the wait times compared to DNS propagations. With DNS caching it can take some time until your requests get re-routed to your DR CPI instance, because the cache acts on multiple layers with individual time-to-live settings. Even if the global DNS entry is adjusted by Azure Traffic Manager instantly it can still take minutes until your client sees the change.
API Management is primarily used to implement the health probes from AFD to the protected endpoints on SCP CPI. AFD accepts only http 200 as succesfull connection. With APIM I get more freedom to consider responses successful.

Fig.5 Overview failover architecture S4 and CPI
Awesome, now we can rely on AFD to re-route our iFlow calls depending on the availability of my CPI tenant. Since the communication details of the target iFlow are hidden behind the AFD address, it doesn’t matter anymore if my request originates from the primary S4 or my DR instance. In case S4 does a failover from West EU to North EU but CPI stays available in West EU, AFD accepts the requests from the DR site and forwards to CPI in West EU. It would also cover a failover that concerns only CPI, where S4 was not impacted at all and stayed in West EU.
Great, all combinations of system moves are covered routing-wise. What about the Cloud Connector for S4 inbound request? For the highest degree of flexibility, you would need to register both Cloud Connector instances with each productive SCP subaccount (West EU + East US).
If you configure only 1-1 connections between the primary Cloud Connector and the primary CPI instance, you need to failover CPI (even though it might still be operational) in case your S4 moves to the DR side. This scenario can be avoided with a many to many registrations of the SCP subaccounts on the Cloud Connector.
How do I keep the CPI tenants in synch?

Fig.6 CPI iflow synch
You could setup the SCP Content Agent Service with two transport routes. One pointing towards the primary productive CPI instance and one towards the DR instance. Find a blog post by SAP on the setup process here and an extended variation by the community here.
This works for CPI packages and its content. But what about credentials, private keys, variables, and OAuth credentials? There is no standard API provided to synch them. One option would be to create them externally first (e.g., in Azure KeyVault) and deploy via API to both tenants. Or secondly you could think of providing a custom iFlow to extract and expose to the other CPI tenants.
The SCP content agent looks nice, but creates double the cost, because I need a CPI tenant running that I am hopefully never going to use. The same is true for the S4 on the DR side. So, what if I am willing to take higher risk, suffer longer recovery times and do only passive setups?
What do I mean by passive: Above scenario in fig.3 is considered an active-active scenario where the workloads are waiting in hot-standby ready to take over once needed. An active-passive scenario involves only the SCP and Azure landing zone setup from a configuration, networking, provisioning and governance perspective. The actual workload like the Azure VM or the CPI instance are either stopped or not even created yet to save cost.
How to spin up resources for an active-passive scenario quickly?
Manual config works but can we do better than that? Here are some thoughts on it:
For the SAP backend part of it I can recommend looking at recent Infrastructure-as-Code (IaC) with DevOps blogs. Here is a link to some of the Azure-related video resources to get you started on the Infrastructure-as-a-Service part.
So far there is no IaC approach to spin up services like CPI in SCP in a programmatic way, that could be leveraged from Azure DevOps Pipelines, GitHub Actions or the likes. So, the actual service needs to be provisioned manually for sure. Once done, you could either synch from a new DR route on the SCP Transport Management Service or perform a manual import.
For manual import I recommend to version artifacts in an external Git repos to be sure you can recover the files, have auditability on the changes and avoid risk of losing access to the currently active version. Your implementation on the DEV CPI tenant is probably in a different state, that what is in production right now. And keep in mind, that an outage that causes a failover for CPI also crashes your CPI Web UI ?
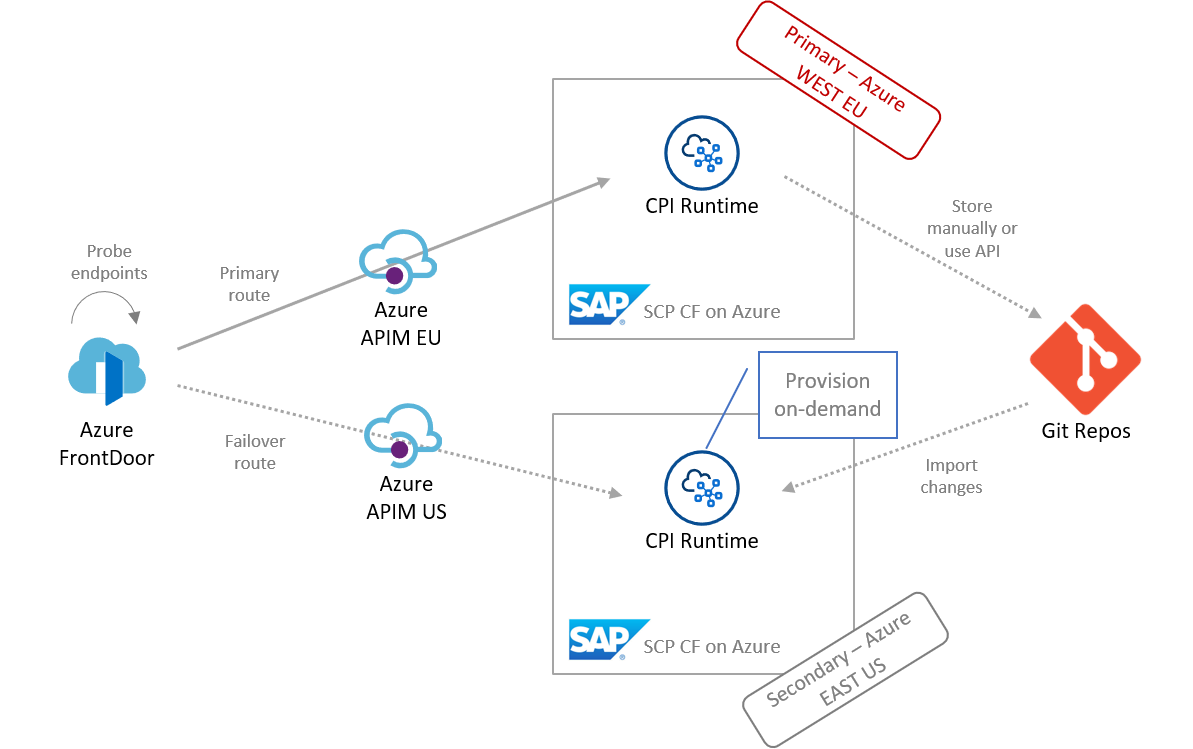
Fig.7 Manual Git-based synch of CPI artifacts
For DevOps-based approaches on iFlow-level have a look here:
- For CloudFoundry apps (MTAR projects) I published a blog on blue/green deployments with Azure DevOps
- For iFlows find guidance on an implementation here. The SAP API Business Hub describes the interface to create, modify or delete iFlows programmatically.
Bottom line is manual provisioning and configuration is straight forward but poses greater risk of failures and creates longer time to recovery during disaster.
To perform all those steps, it is a best practice to have an Admin or Emergency user with elevated rights on the Subaccount. Developers should not touch CPI in production to avoid risk of artefact inconsistency.
Finally, the Azure Front Door setup
Create a frontend (the abstraction layer with a new URL masking CPI), configure your two Azure APIM instances (your CPI proxy tenants) as backend pools and finish by creating the routing rule to tie both things together.

Fig.8 Screenshot from AFD setup
Front Door uses priorities and weightings to forward traffic. In our case I want to always target CPI in Europe and only switch to East US in case my probe fails. Below setting considers my backend healthy when the last two probes within 60 seconds (one probe every 30secs) were successful. Be aware that AFD has a large number of Point-of-Presences (PoP) around the globe, which results in a considerably high amount of probes. See below note from the Azure docs or the reference article here.

We use http method HEAD to avoid triggering messages on CPI and be most cost-efficient. Remember we map iFlow authentication errors (http 401) to 200 success for our AFD probe.
For the probe path I deployed an iFlow that returns only its region. It listens on “<cpi>/health”.

Fig.9 Screenshot from AFD health probe setting
My routing rule (AFD -> CPI) simply targets all paths, because the pattern matching is set to “/*”.

Fig.10 Screenshot of AFD Routing Rule config
The metrics on AFD allow you to monitor the health of your backends. You can create alert rules in case certain thresholds are exceeded or pin the graph to your dashboard. This way your CloudOps team has real-time insights into your CPI tenant status and possible failovers. We expect to see values high in the 90%. Otherwise there would be a failover, rigth 😉

Fig.11 Screenshot from AFD metrics screen with Alert and dashboard pinning option
On my two consumption-based Azure APIM instances (one in west EU and one in east US) I forward all requests to their respective remote SCP CPI instance.

Fig.12 Screenshot from APIM setup
The only interesting configuration can be found on the custom probe operation. In there I map authentication error (http 401) responses from CPI for the "health" iFlow to http 200 success. This way we get proper health probes on AFD.
<choose>
<when condition="@(context.Response.StatusCode == 401)">
<return-response response-variable-name="existing response variable">
<set-status code="200" reason="Probe" />
</return-response>
</when>
</choose>For your convenience I uploaded the OpenAPI definition on my GitHub repos. Find the link at the end.
DR drills for the faint hearted
Let’s test this already! We have two CPI instances: Our primary in Azure West EU and our secondary in East US. My DR demo iFlows store the value of the global variable for the location ID in a header. So, we can reuse that information on Postman to verify a correct setup. Initially my Postman request to https://cpi-dr-demo.azurefd.net/http/drdemo/primary returns the products from OData service EPM_REF_APPS_PROD_MAN_SRV with value “primary”for header “Mylocationid”.

Fig.13 Screenshot of Postman, response headers
As a next step I misconfigure the probe of the european APIM instance, that checks the health status of CPI, to simulate an outage. It is kind of hard to create an error other than http 401 as we cannot rely on iFlow message failures nor can I make CPI unavailable if I am not willing to delete the instance.
I put the probe from "https://<cpi-runtime>/http/health" to "https://<cpi-runtime>/" that gives me an http 404 fortunately ?.
As of now the probes will start to fail. Once we have multiple errors reported within the 60 second probe window...



Fig.14 Overview of simulated CPI outage in Azure west-eu
We start seeing the “Mylocationid” header change to secondary. Meaning my requests are now routed via CPI in Azure East US. Lucky us ?. The same is reflected on the AFD metrics:

Fig.15 AFD metrics of CPI health after simulated outage
We see a major drop for the red-line (CPI instance in europe), that caused our failover. Nice! Such a "drop" would be straightforward for an alert. You can create it directly from the portal from the buttons above the metrics chart (see fig.15). Typically you would send an E-Mail, push a Microsoft Teams message or log a service ticket in Servie Now for instance. You get that out of the box.

Fig.16 Screenshot from Alert wizard
Even if you don’t want to use this kind of automatic failover it is still worth considering to implement a reverse proxy in between your S4 and CPI. This way you ensure the flexibility to add this abstraction without the need touch the S4 backend configuration later on. The described setup is often called a facade pattern, in case you want to dig deeper.
Thoughts on production readiness
- Authentication endpoints CPI: This example implementation of failover with two CPI tenants in different Azure regions became a lot easier this month due to an authentication mechanism change for CPI. We can now login with S-User Ids again. Before you needed to use a service key, that contained individual credentials for each CPI tenant. That would have created the need for us to consolidate authentication first, before we can put Front Door in between. Otherwise front door would have routed you correctly, but your backend would need to know upfront which credentials to provide. Not helpful at all ? My approach back then was to add Azure AD into the mix to get a global login with one credential, that is accepted in all my SCP subaccounts. The necessary trust setup can be found in my colleague’s blog. Luckily that was no longer necessary. You just need to make sure that the S-User is a member of all relevant SCP subaccounts and contains the new MessagingSend role.
- Use HTTP 401 vs. Basic-Aauth header on probe: You could argue that my mapping to http 200 for front door is suboptimal because we use an error to communicate success. There are scenraios, where this might be misleading. Again, this is mostly about service availability and recovery rather than proper user configuration. I suspect those errors to be handled differently. If you want to actually call the iFlow with authentication you can add the basic-auth header on the pre-processing step of APIM in Azure. Be aware that you open up an iFlow on the internet in doing so. I would recommend to create a new SCP role on the subaccount at least.
- To failover or not to failover: I would recommend to fine tune the parameters and logics on FrontDoor, APIM and the iFlows provided, based on your needs to avoid unintentional CPI failovers. Especially, if you do a passive setup.
- Secure AFD and APIM: It is best-practice to limit allowed traffic only to anticipated services. Find a reference to restrict APIM inbound only to AFD here. To act upon malicious traffic on Front Door level you can activate its internal Web Application Firewall.
- Secure CPI endpoints: So far there is only a header based ip allow-list mechanism in CPI to restrict the calling ips to your services. In our case that is Front Door. Have a look at this blog to learn about the setup process on CPI. Find the description to identify your Front Door instance here and on our docs.
- Automate the failover process and configuration synch: It starts with the S-User for the CPI authentication. How do you keep him in-synch across subaccounts? User provisioning from Azure AD could be an option for a streamlined approach. There is also the SAP API Business Hub for SCP. Be it as is, there are a lot of options to add automation to the described failover case. But they require detailed knowledge and create complexity. However, a hybrid approach with manual decisions and some automation, that is well understood looks promising.
- Stateful vs stateless iFlows: My provided guidance for the failover assumed stateless iFlows that do not store any messages (e.g. JMS) and run isolated. Hence, they don’t have the risk of running in parallel creating messages twice and conflicting with each other on the target systems. Consider timer-triggered iFlows or polling triggers like SFTP in an active-active CPI scenario: You need means to deal with the duplicates or have clear “failover” switches that avoid active-active altogether. For JMS you could consider moving the message queue outside of CPI to overcome the isolation. A geo-redundant flavour of a message queue, like the Azure Service Bus, could mitigate that. You would work with your messages outside of CPI via the AMQP adapter. For polling triggers, consider replacing the iFlow trigger with http to avoid unintentional restart after an CPI outage.
- Monitoring and logging: With active-active setups you need to be aware that your CPI Admin or CloudOps team needs to check two tenants as they create independent logs. To overcome that you would need an external monitor that consumes the logs via the official OData API. I provided a guide on how to achieve that with Azure Monitor here. You could scale that to multiple CPI tenants.
Alternative Proxy components
In my example we saw Front Door with API Management. You could also look at the following depending on your requirements
- Azure Traffic Manager for a DNS-based approach. Check the DNS caching time-to-live settings and keep mulit-layer caching in mind! Here is my post on the setup
- Azure Function proxies for a programmatic approach.
- Deploying an enterprise-grade Reverse Proxy like Apache in a VM or Container and manage all SLA-relevant setup yourself.
- Consider other managed proxies on the market
Final Words
That was quite the ride! I explained how SAP deploys CloudFoundry zone-redundant in its multi-cloud environment and how that impacts your SAP backend disaster recovery plans.
At first we had a look at single SCP CPI (no DR) deployments with S4 backend failovers from its primary region west EU to its disaster recovery site in north EU. The Cloud Connector setup and Location ID concept play an important role to make that work.
To enable failover for CPI too, we needed to add two more components to abstract the communication configuration on the individual S4 backends. This way you can keep the config on the backend no matter what happens with downstream services. The newly added components act essentially as a reverse proxy, that needs to be highly available and globally available to meet the requirements for a resilient failover. For that purpose I introduced Azure Front Door and Azure API Management (consumption based). Keep in mind that some CPI configs and runtime artifacts such as Credentials need to be synched too (see last two points on "Thoughts on production readiness").
Of course, there are other services out there that could do similar things. The beauty of this setup is minimal configuration effort and complete usage of managed services.
In the end we saw simulated a failover, that was induced by a misconfigured probe endpoint on API Management, because it is rather hard to create availability errors of CPI without deleting the instance. The health probes from Front Door picked up the disruption and automatically started re-routing the traffic. Not too bad, right?
Next to this failover scenario I also published a guide oin how to monitor CPI messages with Azure Monitor here.
Find the used iFlows on my GitHub repos.
As always feel free to leave or ask lots of follow-up questions.
Best Regards
Martin
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
3 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
abapGit
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
Advanced formula
1 -
AEM
1 -
AI
8 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
API security
1 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
Azure API Center
1 -
Azure API Management
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
Bank Communication Management
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
13 -
BTP AI Launchpad
1 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Fabric
1 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
BW4HANA
1 -
CA
1 -
calculation view
1 -
CAP
4 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
4 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Dataframe
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Defender
1 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ESLint
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
first-guidance
1 -
Flask
1 -
FTC
1 -
Full Stack
8 -
Funds Management
1 -
gCTS
1 -
GenAI hub
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
9 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
Hana Vector Engine
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
Infuse AI
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
4 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multilayer Perceptron
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
Neural Networks
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
3 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
Partner Built Foundation Model
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Prettier
1 -
Process Automation
2 -
Product Updates
6 -
PSM
1 -
Public Cloud
1 -
Python
4 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
4 -
S4HANA Cloud
1 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
9 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP API Management
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
22 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Generative AI
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP BTPEA
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HANA PAL
1 -
SAP HANA Vector
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
2 -
SAP PAL
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapfirstguidance
1 -
SAPHANAService
1 -
SAPIQ
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
15 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
3 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Vectorization
1 -
Visual Studio Code
1 -
VSCode
2 -
VSCode extenions
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Distributed Resiliency of SAP CAP applications using SAP HANA Cloud (Multi-Zone Replication) with Azure Traffic Manager in Technology Blogs by SAP
- Multi-region High Availability architecture for SAP BTP Launchpad Service using Azure Traffic Manager in Technology Blogs by Members
- SAP BTP Multi-Region reference architectures for High Availability and Resiliency in Technology Blogs by Members
- Black Friday will take your CPI instance offline unless… in Technology Blogs by Members
- Second round of crashing iFlows in CPI and failing over with Azure – even simpler in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 10 | |
| 9 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 |