
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Multi-model in hana_ml 2.6 for Python (part 02): M...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Developer Advocate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-12-2020
9:54 PM
In the previous post, we looked at the basics of Pandas and HANA dataframes that we will use in this series explaining the new multi-model functionality of
...we loaded data from CSV files into a client's Pandas dataframe and then persisted those Pandas dataframes by creating tables with that data in SAP HANA using
We then applied
and that was a really bad line of code!
It was bad for two reasons.
First, the Pandas module provides its own method to output the content of the dataframe:
The good news is that
Second, applying
If all we need is to see a few sample records stored in the SAP HANA table, then you should apply
When a method like
As we said above, the best practice is pushing the calculation down to the SAP HANA database and limiting the amount of data transferred back to the client. And this limiting should apply not only to a number of rows but as well to required columns only. Tables in SAP HANA are column-oriented by default, and selecting columns you do not need in the result is the anti-pattern.
The method
If you need only column names without data types, then you can simply use the
Now, let's answer some data exploration questions!
We need to use the
To make the code easier to read I wanted to split this Python line of code into multiple lines. That's why I put it all into the brackets.
Accordingly to https://simpleflying.com/longest-runways/ "...the [Qamdo Bamda Airport] runway’s length is a necessity due to its high altitude. In fact, the airport and runway are situated 4,400 meters above sea level. As we alluded to above, high altitude affects engine performance and the ability for wings to acquire the lift needed to get the aircraft airborne."
The
To answer this we need to add a calculated column
Accordingly to https://en.wikipedia.org/wiki/Svalbard_Airport,_Longyear Svalbard Airport "...is the northernmost airport in the world with scheduled public flights."
For that, we will use the
...in
I did not include generated SQL statements for the last two examples. I leave these to you to find out as a hands-on exercise.
If you want to even better understand HANA dataframe calculations, then I would suggest you to experiment with the statements to include
So far, we haven't done anything multi-model specific in our code, but I wanted to make sure that we are on the same page before we jump to the geospatial data in the next post.
Stay healthy ❤️ stay curious,
-Vitaliy (aka @Sygyzmundovych)
hana_ml 2.6 in the context of my demo used in SAP TechEd’s DAT108 session.In the previous episode...
...we loaded data from CSV files into a client's Pandas dataframe and then persisted those Pandas dataframes by creating tables with that data in SAP HANA using
create_dataframe_from_pandas(). The result of each create_dataframe_from_pandas() method execution was a HANA dataframe in Python that defines a SELECT statement to read this data.We then applied
collect() method to that HANA dataframe to get the result of that SELECT statement as data in a Pandas dataframe. I used the following Python code for that:print(dfh_ports.collect())and that was a really bad line of code!
It was bad for two reasons.
How to display the results
First, the Pandas module provides its own method to output the content of the dataframe:
display() i/o print(). The advantages of the display method are:- nicely formatted outputs in notebooks,
- options to customize the output.
The good news is that
display is the default action for Pandas dataframes.How to collect the results from SAP HANA
Second, applying
collect() to a HANA dataframe that selects the complete SAP HANA table will read all table's records in the database, transfer that complete dataset over the network, and will try to store all this data in your Python client's memory. And that's not how it should be done!If all we need is to see a few sample records stored in the SAP HANA table, then you should apply
head() before collect().
When a method like
head() is applied to a HANA dataframe, then the result is another HANA dataframe with a modified SELECT statement. Let's see this in practice.dfh_portsdfh_ports.select_statementdfh_ports.head(5)dfh_ports.head(5).select_statement
Data exploration with HANA dataframes
As we said above, the best practice is pushing the calculation down to the SAP HANA database and limiting the amount of data transferred back to the client. And this limiting should apply not only to a number of rows but as well to required columns only. Tables in SAP HANA are column-oriented by default, and selecting columns you do not need in the result is the anti-pattern.
The method
dtypes() is used to find columns of a HANA dataframe. If you are familiar with Pandas, then you can notice that with a HANA dataframe it is a method, while in a Pandas dataframe dtypes is a property.If you need only column names without data types, then you can simply use the
columns property.print(dfh_ports.columns)
Now, let's answer some data exploration questions!
What is the airport with the longest runway?
We need to use the
sort() method to answer this question.(
dfh_ports
.select("CODE", "DESC", "LONGEST", "COUNTRY", "CITY")
.sort("LONGEST", desc=True)
.head(3).collect()
)To make the code easier to read I wanted to split this Python line of code into multiple lines. That's why I put it all into the brackets.

Accordingly to https://simpleflying.com/longest-runways/ "...the [Qamdo Bamda Airport] runway’s length is a necessity due to its high altitude. In fact, the airport and runway are situated 4,400 meters above sea level. As we alluded to above, high altitude affects engine performance and the ability for wings to acquire the lift needed to get the aircraft airborne."
The
SELECT statement behind the result was:
What airport is the closest to a pole (either North or South)?
To answer this we need to add a calculated column
ABSLAT with the absolute values of airports' latitudes that can be either positive in the Northern hemisphere, or negative in the Southern.(
dfh_ports
.select(
"CODE", "DESC", "LONGEST", "COUNTRY", "CITY", "LAT",
('ABS("LAT")', "ABSLAT")
)
.sort("ABSLAT", desc=True).head(3)
.collect()
)
Accordingly to https://en.wikipedia.org/wiki/Svalbard_Airport,_Longyear Svalbard Airport "...is the northernmost airport in the world with scheduled public flights."
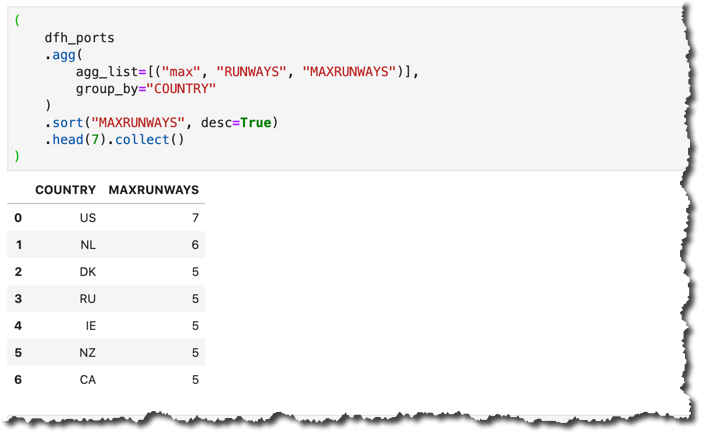
What are the countries with airports with the highest number of runways?
For that, we will use the
agg() method with max aggregation function from SAP HANA SQL.(
dfh_ports
.agg(
agg_list=[("max", "RUNWAYS", "MAXRUNWAYS")],
group_by="COUNTRY"
)
.sort("MAXRUNWAYS", desc=True)
.head(7).collect()
)
You can find this notebook...
...in
hana-ml-samples repository: https://github.com/SAP-samples/hana-ml-samples/blob/main/Python-API/usecase-examples/multimodel-anal....A self-check riddle
I did not include generated SQL statements for the last two examples. I leave these to you to find out as a hands-on exercise.
If you want to even better understand HANA dataframe calculations, then I would suggest you to experiment with the statements to include
filter(), deselect(), distinct() etc.So far, we haven't done anything multi-model specific in our code, but I wanted to make sure that we are on the same page before we jump to the geospatial data in the next post.
Stay healthy ❤️ stay curious,
-Vitaliy (aka @Sygyzmundovych)
- SAP Managed Tags:
- SAP HANA Cloud,
- Python,
- SAP HANA,
- Big Data
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
95 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
311 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
354 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
443 -
Workload Fluctuations
1
Related Content
- Fairness in Machine Learning - A New Feature in SAP HANA Cloud PAL in Technology Blogs by SAP
- Unlocking Data Value #3: Machine Learning with SAP in Technology Blogs by SAP
- Auto-generating HANA ML CAP Artifacts from Python in Technology Blogs by SAP
- How to compare an APL model to a non-APL model ─ Part 2 in Technology Blogs by SAP
- Develop a Machine Learning Application on SAP BTP - Data Science part in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 18 | |
| 16 | |
| 12 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 | |
| 6 |