
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Surviving and Thriving with the SAP Cloud Applicat...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2023
2:51 PM
Greetings and salutations, fellow CAP enthusiasts! We're back with another episode of "Surviving and thriving with the SAP Cloud Application Programming Model" (#CAPTricks). Last time, we covered the wild and bumpy ride of getting your app up and running on your local machine, complete with all the twists and turns of talking to on-premise systems via the Cloud Connector and whatnot.
But now, I've been experimenting with the SAP BTP, Kyma runtime, and wanted to see just how quick and easy it is to take our "trusty old CAP app" from the Cloud Foundry environment over to the Kyma landscape - it's been quite a journey for me personally. Now, if you're still thinking this series is going to be a neat and tidy chronology, I hate to disappoint - I just write about what pops up on my radar. (But don't worry, I've got much more like integration and UI tests on the horizon, I just need to do some more research before I feel confident enough to share my findings. 😉)
I've been primarily working with the SAP BTP, Cloud Foundry runtime, but we have seen a growing demand and need for applications to be deployed and running on Kubernetes. SAP provides a managed Kubernetes-based runtime called SAP BTP, Kyma runtime which has started as the open-source project Kyma. With loads of discussions on which SAP BTP environment to choose, this blog post will dive into the technical aspects of deploying a CAP application on the SAP BTP, Kyma runtime.
Full disclosure as usual: I'm not exactly a Kubernetes pro, especially not in a production setting or within the context of SAP. My experience has mostly been limited to playing around with hosting dedicated GitHub Actions runners for small projects or doing "Hello World" stuff. But, the recent changes in the CAP on Kyma movement caught my eye because it involves a new approach to deployment and service binding. That's why I decided to dive a little deeper and learn more about it.
I'm not here to delve into the differences between SAP BTP, Kyma runtime and SAP BTP, Cloud Foundry runtime or to argue for one over the other. Instead, my focus is on the technical aspects of deploying a CAP application to Kubernetes.
Kubernetes? Yes, the SAP BTP, Kyma runtime is essentially "a fully managed Kubernetes runtime based on the open-source project "Kyma". This cloud-native solution allows the developers to extend SAP solutions with serverless Functions and combine them with containerized microservices. The offered functionality ensures smooth consumption of SAP and non-SAP applications, running workloads in a highly scalable environment, and building event- and API-based extensions", so the service description in the SAP Discovery Center.
To gain a better understanding, I recommend checking out available resources such as the SAP Community Call with piotr.tesny and jamie.cawley titled "Understand the value proposition of SAP BTP, Kyma runtime by example," or the "2 Minutes of Cloud Native" playlist by my friend and former colleague, kevin.muessig. You could also start with some well-known Kubernetes courses.
Before discussing the differences between the runtimes, let's first highlight their similarities. Both runtimes operate on the SAP Business Technology Platform and have an entry point in the platform, making this their commonality.
At first glance, both platforms may appear similar, as they provide an abstraction layer for developers to focus on application development and deployment, without the need to worry about the underlying infrastructure. Additionally, both platforms support containerization, allowing applications to be packaged in a consistent and portable way, making them easier to manage and deploy.
Let's talk about the deployment differences between SAP BTP, Cloud Foundry runtime and SAP BTP, Kyma runtime. Obviously, the command line tools to interact with the environments are different. While the Cloud Foundry CLI was the go-to tool to interact with the SAP BTP, Cloud Foundry runtime, kubectl is the tool you'll need to get cozy with in the world of SAP BTP, Kyma runtime.
So, let's quickly recap how you'd deploy a CAP application to SAP BTP, Cloud Foundry runtime:
The MTA (Multi-Target Application) is technically just a ZIP file that the SAP BTP, Cloud Foundry runtime (specifically the deploy service) picks up and generates the container for you. The platform takes care of managing the service instances, like creating, updating, and deleting them as needed. As a developer, all you have to do is provide a properly structured ZIP file - the MTA archive. The SAP BTP, Cloud Foundry runtime and its components create the container and the image (Diego cells and droplets) automatically for you.
The deployment of applications to Kubernetes-based environments (like SAP BTP, Kyma runtime) is a little different but provides more flexibility. However, as they say, with great power comes great responsibility. In a nutshell:
Paketo, Helm? You might be wondering about Paketo and Helm. Don't worry; we'll cover that in a bit. The main difference is that with Kubernetes-based environments, you're responsible for creating the application (Docker) image and not any platform. Kubernetes picks up the Docker images and creates the container, while Cloud Foundry takes care of the entire process from the MTA archive to running a container.
At first, this might sound complicated (it did for me!) but it's not as tough as it seems. Let's dive into the two tools, Paketo and Helm, that will help with your deployment tremendously.
Before we dive into Paketo in detail, let's take a step back to better understand where it's coming from. When a developer deploys an application to Cloud Foundry, the container and image to run the application are created by Cloud Foundry, using buildpacks. So, what exactly are buildpacks? According to the official Cloud Foundry documentation: The official Cloud Foundry documentation states the following:
In short: You provide the application. Cloud Foundry does the rest to figure out what's needed and creates the container and image to run your stuff.
Kubernetes, on the other hand, relies on Docker images to run applications or workloads in general. This means that the responsibility shifts to you, as the developer, to build the Dockerfile. While this is manageable, there are more convenient ways. And that's where Paketo comes in. Paketo provides buildpacks without actually using Cloud Foundry.
Built by the Cloud Foundry buildpacks team, Paketo allows you to build Docker images with a single command and without any additional configuration. Using the Paketo CLI, called pack, you can quickly create Docker images for your application. Want to see it in action? Here we go:
The command "pack build" is used to create a Docker image. The command specifies the following options:
The command will analyse the contents of the specified path ("gen/srv"), and will use the Paketo builder to determine which dependencies are required to run the application. Once the dependencies have been determined, the necessary packages will be installed and the Docker image will be created.
After the image is created, it will be tagged with "ghcr.io/maxstreifeneder/verificationapp-srv:test" and published to the specified container registry.
Initially, pack analyses the type of project that needs to be handled:

After determining that this is a node-based project, pack examines the package.json file to determine which version of node needs to be installed. There are various ways to install dependencies, and pack ensures to choose the most suitable one based on the available files and directories. For example, it checks if a node_modules directory already exists with the dependencies installed, or if npm ci is a viable option due to the presence of a package-lock.json file.
While there are various aspects to consider, such as the configuration of the operating system and setting environment variables, it can be unclear what the resulting Docker image will look like. To shed some light on this, I like to reverse engineer things whenever possible. But how can you reverse engineer a Docker image to its individual layers or even a Dockerfile? Although Paketo's methodology may pose some limitations, you can still deconstruct the image into its layers using tools like dive.
It's relatively simple:
In the GIF above, you can see the layers of the image on the left side and the impact of each layer on the file system (highlighted in yellow) on the right side. This provides a good idea of what Paketo does in general and gives one the opportunity to further inspect the built Docker image - for instance its different layers. If you find the previous method too detailed or excessive, pack CLI also offers a simpler alternative to inspect the built Docker image at a higher level:
You can use this feature to view the list of buildpacks that have been identified and will be included in the Docker image you have built. This Docker image can then be deployed to the SAP BTP, Kyma runtime.
All of these Docker images will later on end up in your values.yaml file for the Helm chart (next paragraph 😉) and are picked up by the SAP BTP, Kyma runtime to run the application.

You can apply the same approach to deploy SAP HANA artifacts: use the pack CLI to build the corresponding Docker image and then include its reference in the values.yaml file for the Helm installation.
Installation of pack cli: https://buildpacks.io/docs/tools/pack/
Paketo homepage: https://paketo.io/
pack build: https://buildpacks.io/docs/tools/pack/cli/pack_build/
pack inspect: https://buildpacks.io/docs/tools/pack/cli/pack_inspect/
dive tool: https://github.com/wagoodman/dive
"The package manager for Kubernetes", so the short description on helm.sh.
Helm is a package manager for Kubernetes, which makes it easy to install, upgrade, and manage applications and services in a Kubernetes cluster. When it comes to SAP Cloud Application Programming Model, Helm can be used to package and deploy CAP applications to a Kubernetes environment like SAP BTP, Kyma runtime.
Using Helm to deploy CAP applications to Kubernetes offers numerous benefits. Firstly, it simplifies the deployment process by automating the installation and configuration of applications and services, reducing the amount of manual work required. Additionally, it enables version control, so you can track changes and rollback to previous versions if necessary.
Deploying a CAP application without Helm would typically involve writing a complete Kubernetes manifest to create the corresponding resources. However, using Helm's templating function, you can avoid doing that for every single CAP application. Do you want to do that for every single CAP application? My rough guess: Most likely not. The CAP team has already taken good care of the common configuration with the help of Helm template functions and much more, so you only need to focus on the specifics for your application.
Here's a concrete example:
Let's take a values.yaml file in one of my sap-samples repositories. The values.yaml file only contains a basic configuration about the application itself and which service instances and bindings are needed and is the key file in your deployment configuration. With helm install you could already install this chart on your SAP BTP, Kyma runtime but you won't really find out what exactly you are deploying. I wanted to know more. I know that Kubernetes resource definitions are by far more complex than this particular values.yaml file for Helm - so where's the magic happening that generates a Kubernetes resource out of that Helm chart? Here's my Helm chart (Link😞
When you run cds add helm, it generates more than just the values.yaml file for your CAP application. It also creates several .tpl files that contain template helpers/functions used to generate various Kubernetes/Kyma resoucres, such as APIRules and Deployments, in addition to the basic CAP application.
To see the complete deployment configuration, you can use helm template <directory>. This command takes the template helpers (.tpl files) into account and renders the chart to standard Kubernetes resource templates. You could basically use these templates with kubectl apply -f <helm-template-result-file> without using Helm, but you won't get the benefits of Helm. I've shared the results of running "helm template" here.
Why write hundreds of lines of Kubernetes resource definitions when you can do it all with just a few dozen lines in a Helm chart for your CAP application? That's the power of using Helm. And if you've already installed a Helm chart and want to see what you've got, just use helm get manifest <release name> to get the full installation manifest. It's that simple!
Adding a new service instance is as easy as creating a new key in the values.yaml file and filling in the required properties (such as serviceInstanceFullname, serviceOfferingName, servicePlanName, etc.).
If you're familiar with SAP BTP, Cloud Foundry runtime, you'll recognise these properties, as ServiceInstances and ServiceBindings work on the same principle in both environments - thanks to the SAP BTP Service operator!
You can find a list of possible properties for creating ServiceInstances and ServiceBindings in the GitHub repository of the SAP BTP service operator.
Lastly, create a new .yaml file with the name of the key you provided in the values.yaml file. The file's content is simply "{{- include "cap.service-instance" . }}", and one of the Helm template helpers provided by CAP will pick it up and recognise it as a ServiceInstance and ServiceBinding.
In other words, the name you choose for the key in the values.yaml file to define a service instance can be anything you like, as long as you create a corresponding file with that name in the directory, and include the phrase I mentioned earlier. The whole process of using template functions, different yaml files, and getting the desired results can be a bit overwhelming at first, but once you've got the hang of it... 😉
Overall, using Helm to deploy CAP applications to Kubernetes can save time and effort, improve consistency and reliability and makes it easier to manage.
That's it in a nutshell.
Helm: https://helm.sh/
Helm template functions: https://helm.sh/docs/chart_template_guide/functions_and_pipelines/
CAP with Helm: https://cap.cloud.sap/docs/guides/deployment/deploy-to-kyma#deploy-using-cap-helm-chart
Yes, you can use the Cloud Connector with SAP BTP's, Kyma Runtime, but the Connectivity Service operates slightly different than for SAP BTP's, Cloud Foundry runtime. In Kyma, the Connectivity Proxy (read more about it in one of my previous blog posts) is created per cluster, whereas in Cloud Foundry, it already exists per region.
The Kyma reconciler, which is a scheduled job that runs frequently, checks if you have created a ServiceInstance and ServiceBinding for the Connectivity Service. The Connectivity Proxy will be provisioned into the kyma-system namespace in the runtime but only once - so don't create more than one ServiceInstance and ServiceBinding for the Connectivity service! It can be accessed from within the Kyma runtime using the URL connectivity-proxy.kyma-system.svc.cluster.local:20003. By using cds add connectivity, the Helm chart is updated with the necessary secrets for the Connectivity Proxy as volumes, so that the CAP application knows how to access the on-premise system through the SAP Cloud Connector using the Connectivity Service and its Connectivity Proxy.
When creating the ServiceInstance and ServiceBinding for the Connectivity Service, it's crucial to ensure that this process isn't part of any app deployment, as it's a one-time job and secret rotation (caused by multiple ServiceBindings) could cause inconsistencies for the Connectivity Proxy Pod. Additionally, it's important to make sure that only one connectivity-proxy Pod exists in the kyma-system namespace, as this can impact connectivity to the on-premise system. If issues arise, the Container Logs of this Pod can provide useful insights.
Important: It's also worth noting that Istio injection must be enabled in the namespace where the ServiceInstance and ServiceBinding are created, which can be done with the command
Ok, fair. Since I always like to understand how things work actually - where's the piece of code that differentiates between apps running on SAP BTP, Cloud Foundry runtime and apps running on SAP BTP, Kyma runtime? Basically, if there's no VCAP_SERVICES it's going to read the service information from the mounted volume path:
As I said, little excursion 😉
If you need to receive events from an SAP S/4HANA on-premise system in your CAP application, there are several configuration steps and artefacts required on the SAP S/4HANA on-premise side to enable this connection. Fortunately, there's a simplified process offered through a dedicated transaction called /IWXBE/CONFIG.
In essence, you just need a service key and copy its contents to this transaction, and all the necessary artefacts are automatically created for you. The service key contains information about authorization, applied namespaces, and effective endpoints for the SAP Event Mesh instance. However, this only applies to service keys created in the SAP BTP, Cloud Foundry runtime. For the SAP BTP, Kyma Runtime, which uses Kubernetes Secrets as its service key equivalent, an additional step is required to transform it into the correct format.
jq to the rescue! Since the output of the above shown secret can be formatted as json, we can make use of jq to transform it into the right format again. The jq call is slightly too complex for a one-liner (for instance not all of the properties of that secrets are needed, base64 decoding is required, etc.), that's why I've put into a dedicated file:
So, to get the right JSON for the SAP S/4HANA on-premise transaction, you can simply execute:
As usual, the above shown jq file is also part of the repository I'm currently working on: Enhance core ERP business processes with resilient applications on SAP BTP
I didn't want to dedicate a whole paragraph to it, since I can barely explain the background - my application didn't contain a pool configuration. It worked on SAP BTP, Cloud Foundry but it didn't on SAP BTP, Kyma runtime. Please make sure that you provide a proper DB Pool configuration, otherwise your CAP application might not be able to establish connections to your SAP HANA Cloud instance and something like this might appear in your application logs:
I have no idea why that happens on SAP BTP, Kyma runtime and not on SAP BTP, Cloud Foundry (same application, just packaged differently - Paketo instead of MTA), but my rough guess would be that it has to do with the buildpacks being used and a different default configuration for the underlying npm module generic-pool. I couldn't figure it out, I'm sorry. 😉
Thank you so much for taking the time to read my blog post! Although I'm a big fan of the simplicity of the SAP BTP, Cloud Foundry runtime, I'm thoroughly enjoying my experience with SAP BTP, Kyma runtime. This post is not meant to be a pro-contra comparison, but rather a collection of my thoughts and observations while working on some sample repositories.
I welcome any comments and feedback you may have, whether it's questions, personal experiences, or just your thoughts. Let's continue the conversation in the comments!
But now, I've been experimenting with the SAP BTP, Kyma runtime, and wanted to see just how quick and easy it is to take our "trusty old CAP app" from the Cloud Foundry environment over to the Kyma landscape - it's been quite a journey for me personally. Now, if you're still thinking this series is going to be a neat and tidy chronology, I hate to disappoint - I just write about what pops up on my radar. (But don't worry, I've got much more like integration and UI tests on the horizon, I just need to do some more research before I feel confident enough to share my findings. 😉)
I've been primarily working with the SAP BTP, Cloud Foundry runtime, but we have seen a growing demand and need for applications to be deployed and running on Kubernetes. SAP provides a managed Kubernetes-based runtime called SAP BTP, Kyma runtime which has started as the open-source project Kyma. With loads of discussions on which SAP BTP environment to choose, this blog post will dive into the technical aspects of deploying a CAP application on the SAP BTP, Kyma runtime.
Full disclosure as usual: I'm not exactly a Kubernetes pro, especially not in a production setting or within the context of SAP. My experience has mostly been limited to playing around with hosting dedicated GitHub Actions runners for small projects or doing "Hello World" stuff. But, the recent changes in the CAP on Kyma movement caught my eye because it involves a new approach to deployment and service binding. That's why I decided to dive a little deeper and learn more about it.
Common Ground: SAP BTP, Cloud Foundry runtime and SAP BTP, Kyma runtime
I'm not here to delve into the differences between SAP BTP, Kyma runtime and SAP BTP, Cloud Foundry runtime or to argue for one over the other. Instead, my focus is on the technical aspects of deploying a CAP application to Kubernetes.
Kubernetes? Yes, the SAP BTP, Kyma runtime is essentially "a fully managed Kubernetes runtime based on the open-source project "Kyma". This cloud-native solution allows the developers to extend SAP solutions with serverless Functions and combine them with containerized microservices. The offered functionality ensures smooth consumption of SAP and non-SAP applications, running workloads in a highly scalable environment, and building event- and API-based extensions", so the service description in the SAP Discovery Center.
To gain a better understanding, I recommend checking out available resources such as the SAP Community Call with piotr.tesny and jamie.cawley titled "Understand the value proposition of SAP BTP, Kyma runtime by example," or the "2 Minutes of Cloud Native" playlist by my friend and former colleague, kevin.muessig. You could also start with some well-known Kubernetes courses.
Before discussing the differences between the runtimes, let's first highlight their similarities. Both runtimes operate on the SAP Business Technology Platform and have an entry point in the platform, making this their commonality.
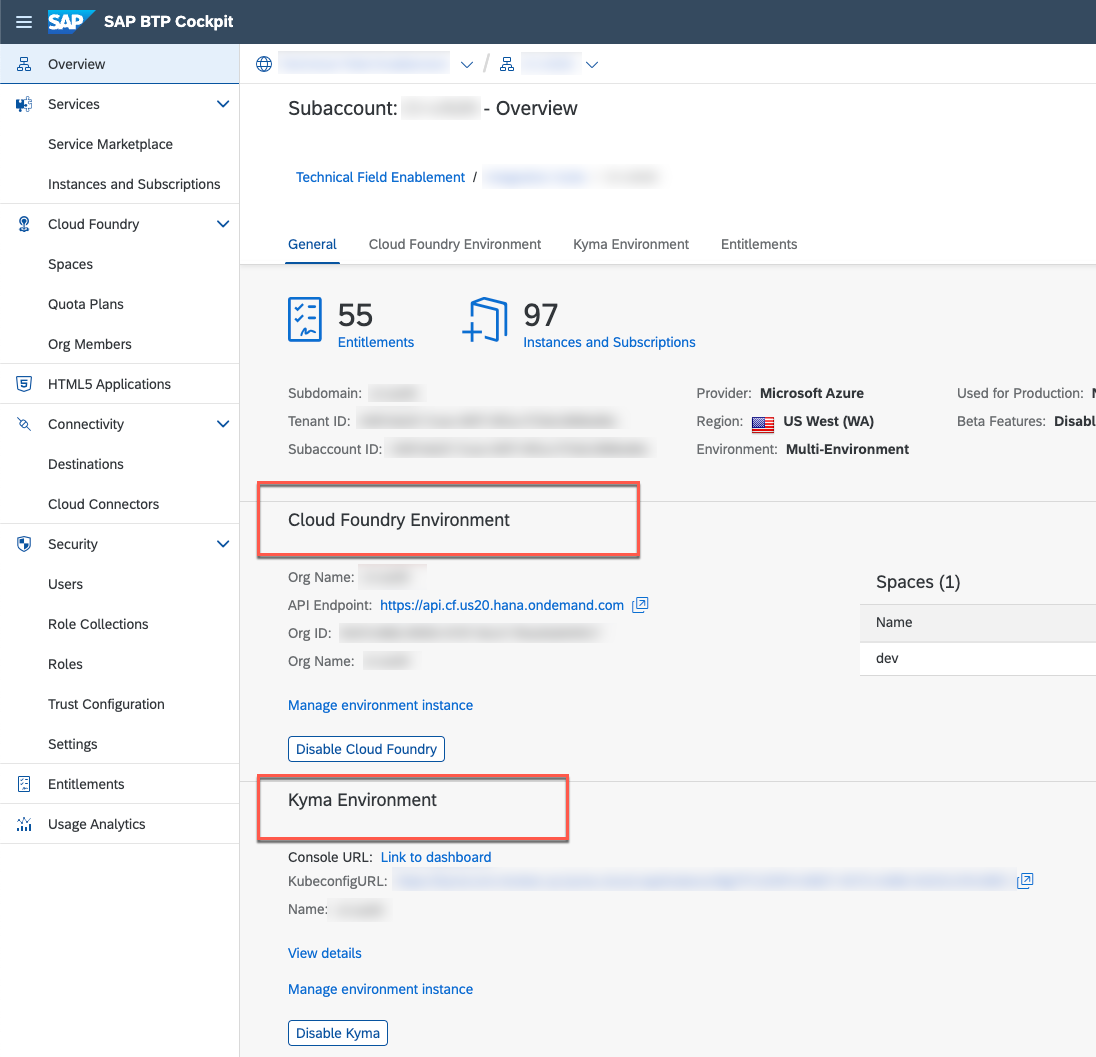
At first glance, both platforms may appear similar, as they provide an abstraction layer for developers to focus on application development and deployment, without the need to worry about the underlying infrastructure. Additionally, both platforms support containerization, allowing applications to be packaged in a consistent and portable way, making them easier to manage and deploy.
Deployment differences: SAP BTP, Cloud Foundry runtime and SAP BTP, Kyma runtime
Let's talk about the deployment differences between SAP BTP, Cloud Foundry runtime and SAP BTP, Kyma runtime. Obviously, the command line tools to interact with the environments are different. While the Cloud Foundry CLI was the go-to tool to interact with the SAP BTP, Cloud Foundry runtime, kubectl is the tool you'll need to get cozy with in the world of SAP BTP, Kyma runtime.
So, let's quickly recap how you'd deploy a CAP application to SAP BTP, Cloud Foundry runtime:
- Develop your CAP Full-Stack application (often underrated in the whole process 😉)
- Build an mta.yaml deployment descriptor with the help of cds add mta
- Create an MTA archive with the Cloud MTA Build Tool: mbt build
- Deploy the MTA archive using a CF CLI plugin called multiapps: cf deploy
The MTA (Multi-Target Application) is technically just a ZIP file that the SAP BTP, Cloud Foundry runtime (specifically the deploy service) picks up and generates the container for you. The platform takes care of managing the service instances, like creating, updating, and deleting them as needed. As a developer, all you have to do is provide a properly structured ZIP file - the MTA archive. The SAP BTP, Cloud Foundry runtime and its components create the container and the image (Diego cells and droplets) automatically for you.
The deployment of applications to Kubernetes-based environments (like SAP BTP, Kyma runtime) is a little different but provides more flexibility. However, as they say, with great power comes great responsibility. In a nutshell:
- Develop your CAP Full-Stack application
- Add a Helm Chart configuration for a common CAP application with the help of cds add helm
- Configure the right values for the provided Helm Chart of a common CAP application
- Create the needed Docker Images with the help of Paketo: pack build
- Install the Helm Chart to the Kubernetes Cluster: helm install
Paketo, Helm? You might be wondering about Paketo and Helm. Don't worry; we'll cover that in a bit. The main difference is that with Kubernetes-based environments, you're responsible for creating the application (Docker) image and not any platform. Kubernetes picks up the Docker images and creates the container, while Cloud Foundry takes care of the entire process from the MTA archive to running a container.
At first, this might sound complicated (it did for me!) but it's not as tough as it seems. Let's dive into the two tools, Paketo and Helm, that will help with your deployment tremendously.
What's Paketo?
Before we dive into Paketo in detail, let's take a step back to better understand where it's coming from. When a developer deploys an application to Cloud Foundry, the container and image to run the application are created by Cloud Foundry, using buildpacks. So, what exactly are buildpacks? According to the official Cloud Foundry documentation: The official Cloud Foundry documentation states the following:
"Buildpacks provide framework and runtime support for apps. Buildpacks typically examine your apps to determine what dependencies to download and how to configure the apps to communicate with bound services.
When you push an app, Cloud Foundry automatically detects an appropriate buildpack for it. This buildpack is used to compile or prepare your app for launch."
In short: You provide the application. Cloud Foundry does the rest to figure out what's needed and creates the container and image to run your stuff.
Kubernetes, on the other hand, relies on Docker images to run applications or workloads in general. This means that the responsibility shifts to you, as the developer, to build the Dockerfile. While this is manageable, there are more convenient ways. And that's where Paketo comes in. Paketo provides buildpacks without actually using Cloud Foundry.
Built by the Cloud Foundry buildpacks team, Paketo allows you to build Docker images with a single command and without any additional configuration. Using the Paketo CLI, called pack, you can quickly create Docker images for your application. Want to see it in action? Here we go:
pack build ghcr.io/maxstreifeneder/verificationapp-srv:test --path gen/srv \
--builder paketobuildpacks/builder:base \
--publishThe command "pack build" is used to create a Docker image. The command specifies the following options:
- ghcr.io/maxstreifeneder/verificationapp-srv:test is the name and tag of the Docker image that will be created.
- --path gen/srv specifies the path where the application artifacts are located (cds build --production has generated the needed artefacts in there)
- --builder paketobuildpacks/builder:base specifies which builder to use for the image. In this case, the "base" builder is being used from the Paketo Buildpacks project. (basically, which base OS to pick)
- --publish specifies that the image should be published to the specified container registry after it is built.
The command will analyse the contents of the specified path ("gen/srv"), and will use the Paketo builder to determine which dependencies are required to run the application. Once the dependencies have been determined, the necessary packages will be installed and the Docker image will be created.
After the image is created, it will be tagged with "ghcr.io/maxstreifeneder/verificationapp-srv:test" and published to the specified container registry.
Initially, pack analyses the type of project that needs to be handled:

pack cli detected which buildpacks are needed
Given that the analysis has determined this to be a node-based project, the pack CLI will then examine the package.json file to determine the specific version of Node.js that needs to be installed:
After determining that this is a node-based project, pack examines the package.json file to determine which version of node needs to be installed. There are various ways to install dependencies, and pack ensures to choose the most suitable one based on the available files and directories. For example, it checks if a node_modules directory already exists with the dependencies installed, or if npm ci is a viable option due to the presence of a package-lock.json file.

pack cli detected npm install as the best dependency installation process
While there are various aspects to consider, such as the configuration of the operating system and setting environment variables, it can be unclear what the resulting Docker image will look like. To shed some light on this, I like to reverse engineer things whenever possible. But how can you reverse engineer a Docker image to its individual layers or even a Dockerfile? Although Paketo's methodology may pose some limitations, you can still deconstruct the image into its layers using tools like dive.
It's relatively simple:
dive image-name:image-tag
dive tool in action
In the GIF above, you can see the layers of the image on the left side and the impact of each layer on the file system (highlighted in yellow) on the right side. This provides a good idea of what Paketo does in general and gives one the opportunity to further inspect the built Docker image - for instance its different layers. If you find the previous method too detailed or excessive, pack CLI also offers a simpler alternative to inspect the built Docker image at a higher level:
pack inspect-image <image-name>:<tag>
pack inspect to see the buildpack details (also remote vs. local)
You can use this feature to view the list of buildpacks that have been identified and will be included in the Docker image you have built. This Docker image can then be deployed to the SAP BTP, Kyma runtime.
All of these Docker images will later on end up in your values.yaml file for the Helm chart (next paragraph 😉) and are picked up by the SAP BTP, Kyma runtime to run the application.
You can apply the same approach to deploy SAP HANA artifacts: use the pack CLI to build the corresponding Docker image and then include its reference in the values.yaml file for the Helm installation.
Installation of pack cli: https://buildpacks.io/docs/tools/pack/
Paketo homepage: https://paketo.io/
pack build: https://buildpacks.io/docs/tools/pack/cli/pack_build/
pack inspect: https://buildpacks.io/docs/tools/pack/cli/pack_inspect/
dive tool: https://github.com/wagoodman/dive
What's Helm?
"The package manager for Kubernetes", so the short description on helm.sh.
Helm is a package manager for Kubernetes, which makes it easy to install, upgrade, and manage applications and services in a Kubernetes cluster. When it comes to SAP Cloud Application Programming Model, Helm can be used to package and deploy CAP applications to a Kubernetes environment like SAP BTP, Kyma runtime.
Using Helm to deploy CAP applications to Kubernetes offers numerous benefits. Firstly, it simplifies the deployment process by automating the installation and configuration of applications and services, reducing the amount of manual work required. Additionally, it enables version control, so you can track changes and rollback to previous versions if necessary.
Deploying a CAP application without Helm would typically involve writing a complete Kubernetes manifest to create the corresponding resources. However, using Helm's templating function, you can avoid doing that for every single CAP application. Do you want to do that for every single CAP application? My rough guess: Most likely not. The CAP team has already taken good care of the common configuration with the help of Helm template functions and much more, so you only need to focus on the specifics for your application.
Here's a concrete example:
Let's take a values.yaml file in one of my sap-samples repositories. The values.yaml file only contains a basic configuration about the application itself and which service instances and bindings are needed and is the key file in your deployment configuration. With helm install you could already install this chart on your SAP BTP, Kyma runtime but you won't really find out what exactly you are deploying. I wanted to know more. I know that Kubernetes resource definitions are by far more complex than this particular values.yaml file for Helm - so where's the magic happening that generates a Kubernetes resource out of that Helm chart? Here's my Helm chart (Link😞

values.yaml file
When you run cds add helm, it generates more than just the values.yaml file for your CAP application. It also creates several .tpl files that contain template helpers/functions used to generate various Kubernetes/Kyma resoucres, such as APIRules and Deployments, in addition to the basic CAP application.
To see the complete deployment configuration, you can use helm template <directory>. This command takes the template helpers (.tpl files) into account and renders the chart to standard Kubernetes resource templates. You could basically use these templates with kubectl apply -f <helm-template-result-file> without using Helm, but you won't get the benefits of Helm. I've shared the results of running "helm template" here.

part of the result for helm template
Why write hundreds of lines of Kubernetes resource definitions when you can do it all with just a few dozen lines in a Helm chart for your CAP application? That's the power of using Helm. And if you've already installed a Helm chart and want to see what you've got, just use helm get manifest <release name> to get the full installation manifest. It's that simple!

part of the result for helm get manifest
Adding a new service instance is as easy as creating a new key in the values.yaml file and filling in the required properties (such as serviceInstanceFullname, serviceOfferingName, servicePlanName, etc.).
If you're familiar with SAP BTP, Cloud Foundry runtime, you'll recognise these properties, as ServiceInstances and ServiceBindings work on the same principle in both environments - thanks to the SAP BTP Service operator!
You can find a list of possible properties for creating ServiceInstances and ServiceBindings in the GitHub repository of the SAP BTP service operator.
Lastly, create a new .yaml file with the name of the key you provided in the values.yaml file. The file's content is simply "{{- include "cap.service-instance" . }}", and one of the Helm template helpers provided by CAP will pick it up and recognise it as a ServiceInstance and ServiceBinding.

template/_helpers.tpl picks up the yaml files

How the required yaml file per ServiceInstance should look like
In other words, the name you choose for the key in the values.yaml file to define a service instance can be anything you like, as long as you create a corresponding file with that name in the directory, and include the phrase I mentioned earlier. The whole process of using template functions, different yaml files, and getting the desired results can be a bit overwhelming at first, but once you've got the hang of it... 😉

Helm flow (source: opensource.hcltechsw.com)
Overall, using Helm to deploy CAP applications to Kubernetes can save time and effort, improve consistency and reliability and makes it easier to manage.
How do I deploy my application now?
- Create a namespace in your Kyma cluster. (kubectl create namespace)
- Make sure that you have created your SAP HANA Cloud instance before and have mapped it to your namespace using the SAP HANA Cloud tools: https://blogs.sap.com/2022/12/15/consuming-sap-hana-cloud-from-the-kyma-environment/
- Add a Helm chart and the required helpers with cds add helm
- Use Paketo to build the Docker images for your db and srv artefacts
- Deploy the UI bits to the HTML5 Application Repository with a provided Docker image from the responsible team: sapse/html5-app-deployer. An example of how that could work is part of the sample repository I've provided: Dockerfile and preparation scripts
- In case you are publishing your Docker images to a private Container registry, make sure you create secret in your Kyma cluster and provide in the Helm chart
- Use Helm upgrade <release name> <chart directory> --install --debug to start the deployment (in helm jargon installation)
That's it in a nutshell.
Helm: https://helm.sh/
Helm template functions: https://helm.sh/docs/chart_template_guide/functions_and_pipelines/
CAP with Helm: https://cap.cloud.sap/docs/guides/deployment/deploy-to-kyma#deploy-using-cap-helm-chart
Can I use the Cloud Connector with SAP BTP, Kyma Runtime?
Yes, you can use the Cloud Connector with SAP BTP's, Kyma Runtime, but the Connectivity Service operates slightly different than for SAP BTP's, Cloud Foundry runtime. In Kyma, the Connectivity Proxy (read more about it in one of my previous blog posts) is created per cluster, whereas in Cloud Foundry, it already exists per region.
The Kyma reconciler, which is a scheduled job that runs frequently, checks if you have created a ServiceInstance and ServiceBinding for the Connectivity Service. The Connectivity Proxy will be provisioned into the kyma-system namespace in the runtime but only once - so don't create more than one ServiceInstance and ServiceBinding for the Connectivity service! It can be accessed from within the Kyma runtime using the URL connectivity-proxy.kyma-system.svc.cluster.local:20003. By using cds add connectivity, the Helm chart is updated with the necessary secrets for the Connectivity Proxy as volumes, so that the CAP application knows how to access the on-premise system through the SAP Cloud Connector using the Connectivity Service and its Connectivity Proxy.

connectivity-proxy-0 is the Pod name in namespace kyma-system
When creating the ServiceInstance and ServiceBinding for the Connectivity Service, it's crucial to ensure that this process isn't part of any app deployment, as it's a one-time job and secret rotation (caused by multiple ServiceBindings) could cause inconsistencies for the Connectivity Proxy Pod. Additionally, it's important to make sure that only one connectivity-proxy Pod exists in the kyma-system namespace, as this can impact connectivity to the on-premise system. If issues arise, the Container Logs of this Pod can provide useful insights.
Important: It's also worth noting that Istio injection must be enabled in the namespace where the ServiceInstance and ServiceBinding are created, which can be done with the command
kubectl label namespace <namespace> istio-injection=enabledHow does CAP know where to get the service binding information from?
On a slightly different note, as someone who has worked with the SAP BTP, Cloud Foundry runtime for quite some time, I'm well acquainted with VCAP_SERVICES. This environment variable is set for each app instance and contains all service binding information as a JSON. Many SDKs heavily rely on fetching this information to establish connections with specific backing services. Initially, in the early days of SAP BTP, Kyma runtime, and CAP, faking the VCAP_SERVICES environment variable was necessary to allow CAP to access the necessary credentials to connect to other services.
However, thanks to the SAP BTP Service operator, this is no longer necessary. Secrets and ConfigMaps are now automatically provided as volumes, eliminating the need to fake the VCAP_SERVICES environment variable.

the deployment configuration after running helm template
Ok, fair. Since I always like to understand how things work actually - where's the piece of code that differentiates between apps running on SAP BTP, Cloud Foundry runtime and apps running on SAP BTP, Kyma runtime? Basically, if there's no VCAP_SERVICES it's going to read the service information from the mounted volume path:

As I said, little excursion 😉
SAP Event Mesh and SAP S/4HANA on-premise - little detour needed
If you need to receive events from an SAP S/4HANA on-premise system in your CAP application, there are several configuration steps and artefacts required on the SAP S/4HANA on-premise side to enable this connection. Fortunately, there's a simplified process offered through a dedicated transaction called /IWXBE/CONFIG.
In essence, you just need a service key and copy its contents to this transaction, and all the necessary artefacts are automatically created for you. The service key contains information about authorization, applied namespaces, and effective endpoints for the SAP Event Mesh instance. However, this only applies to service keys created in the SAP BTP, Cloud Foundry runtime. For the SAP BTP, Kyma Runtime, which uses Kubernetes Secrets as its service key equivalent, an additional step is required to transform it into the correct format.

Secret for the SAP Event Mesh service binding
jq to the rescue! Since the output of the above shown secret can be formatted as json, we can make use of jq to transform it into the right format again. The jq call is slightly too complex for a one-liner (for instance not all of the properties of that secrets are needed, base64 decoding is required, etc.), that's why I've put into a dedicated file:
#!/usr/bin/env jq
def props: "^(management|messaging|tags|uaa)$";
.data | with_entries(select(.key != ".metadata") |
.value|=@base64d
| if .key | test(props) then .value |= fromjson else . end
) So, to get the right JSON for the SAP S/4HANA on-premise transaction, you can simply execute:
kubectl get secrets/your-messaging-secret -o json | jq -f ./kyma/eventmeshkey.jq As usual, the above shown jq file is also part of the repository I'm currently working on: Enhance core ERP business processes with resilient applications on SAP BTP
Mind your DB Pool configuration!
I didn't want to dedicate a whole paragraph to it, since I can barely explain the background - my application didn't contain a pool configuration. It worked on SAP BTP, Cloud Foundry but it didn't on SAP BTP, Kyma runtime. Please make sure that you provide a proper DB Pool configuration, otherwise your CAP application might not be able to establish connections to your SAP HANA Cloud instance and something like this might appear in your application logs:
TimeoutError: Acquiring client from pool timed out. Please review your system setup, transaction handling, and pool configuration. Pool State: borrowed: 0, pending: 0...I have no idea why that happens on SAP BTP, Kyma runtime and not on SAP BTP, Cloud Foundry (same application, just packaged differently - Paketo instead of MTA), but my rough guess would be that it has to do with the buildpacks being used and a different default configuration for the underlying npm module generic-pool. I couldn't figure it out, I'm sorry. 😉
Thank you so much for taking the time to read my blog post! Although I'm a big fan of the simplicity of the SAP BTP, Cloud Foundry runtime, I'm thoroughly enjoying my experience with SAP BTP, Kyma runtime. This post is not meant to be a pro-contra comparison, but rather a collection of my thoughts and observations while working on some sample repositories.
I welcome any comments and feedback you may have, whether it's questions, personal experiences, or just your thoughts. Let's continue the conversation in the comments!
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
430 -
Workload Fluctuations
1
Related Content
- HDI Artifact Recovery Wizard in Technology Blogs by SAP
- Deployment of Seamless M4T v2 models on SAP AI Core in Technology Blogs by SAP
- Integrating Smart contracts with SAPUI5 in Technology Blogs by Members
- Extract blob data (PDF) from CAPM using python library of Document information extraction service. in Technology Blogs by Members
- SAP Fiori for SAP S/4HANA - Empowering Your Homepage: Enabling My Home for SAP S/4HANA 2023 FPS01 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 30 | |
| 17 | |
| 15 | |
| 13 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |