
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA運用管理の基礎(2) データバックアップ
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
04-21-2016
9:23 AM
SAP HANA運用管理の基礎(2)〜データバックアップのメカニズム

更新履歴
2016.05.13.追記: SPS12において、ストレージスナップショットとデルタバックアップの組み合わせのサポートを追記。
前回は、HANAの永続化の機能であるセーブポイントとスナップショットを説明しました。今回は、これらの機能を使っているバックアップについて説明します。具体的な手順やコマンドにはあまりこだわらずに、データバックアップのメカニズムを理解することを目的としたいと思います。
SAP HANAのバックアップ
前回説明しましたが、HANAはインメモリーデータベースであること、加えて今のメモリーは揮発性であることから、セーブポイントというデータベース更新とは独立した永続化機能がその時点のデータベースの状態をデータボリュームに書きこんでいます。
HANAのバックアップの特徴はメモリー上のデータベース本体ではなく、このディスク上のデータボリュームを対象としていることです。つまり、ディスクベースのDBMSのバックアップがDB本体をコピーするのに対して、HANAはメモリー上のDB本体ではなくディスク上のデータボリュームをコピーしようとします。
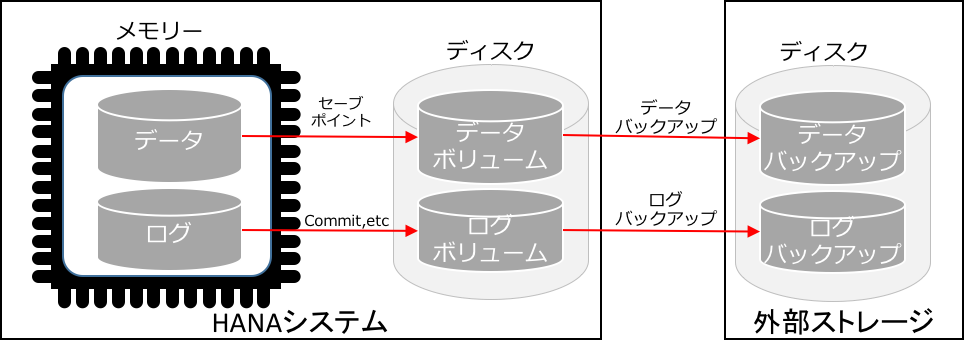
しかし、このやり方には考慮すべき点が2つあります。
- セーブポイントの内容は最大5分前(デフォルト設定)。
- セーブポイントからは一貫性のある状態でバックアップが取れない。
バックアップはセーブポイントから始まる
1番目はセーブポイントがデフォルトで5分ごとに実行されるので、バックアップの内容が最大5分は古いということです。これはログバックアップを行えば直近の状態までリカバリーできるので致命的ではないかもしれませんが、ユーザー感覚としては容認し難いレベルだと思います。
ですので、HANAはバックアップする前ににセーブポイントを実行するようになっています。
静止点はセーブポイントではなくスナップショットで確保する
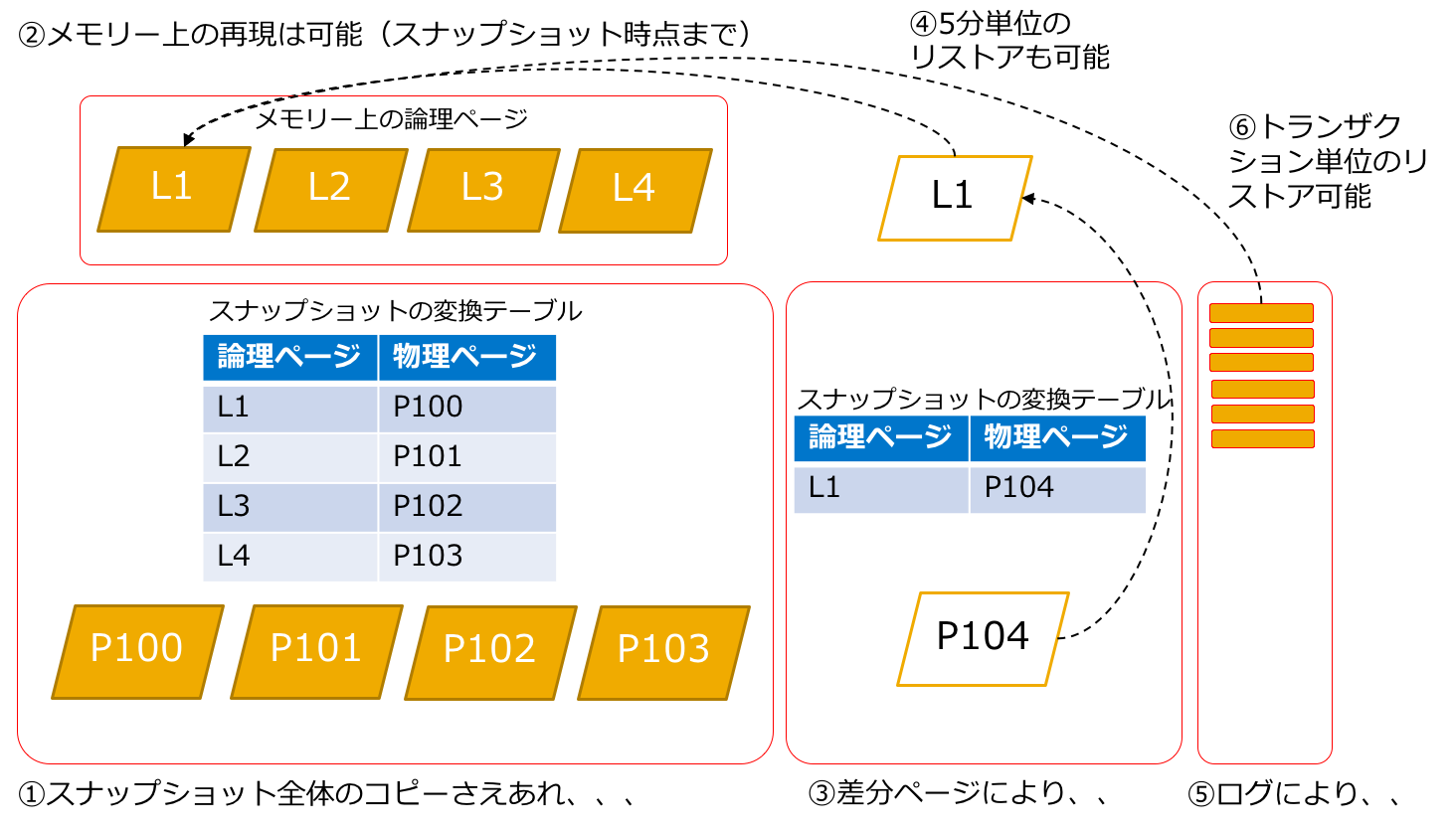
2番目の考慮点は、セーブポイントはバックアップ中でも更新されるからなのですが、データベースとしては致命的であるため、バックアップ開始直後のセーブポイント実行時にスナップショットを書き込みことにより対応しています。つまり、オンラインバックアップ中に内容が変わるかもしれないセーブポイント領域ではなく、セーブポイントのコピーであるスナップショット領域(静止点)をバックアップとすることにより、バックアップ処理中の更新の影響を受けないようにしているわけです。
HANAバックアップの基本的な考え方
HANAのバックアップ/リストアの基本的な考え方を説明します。
通常バックアップは、フルバックアップとしてのデータベース全体イメージのコピーと差分バックアップとしてのトランザクション・ログのコピーから構成されるケースが多いと思いますが、HANAの場合、フルと差分から成っていることは間違いないのですが、差分が2種類あり、1つは更新された物理ページの集合、もう1つはトランザクションログです。前者をデルタバックアップ、後者をログバックアップと呼びます。
リストアの際には、フルバックアップ→デルタバックアップ→ログバックアップの順に、つまり、ある時点の物理ページ全体→その後の差分物理ページ→その後の差分トランザクション、と適用するのが基本的な考え方ですが、RPOによっては使用しないバックアップもあります。
HANAのバックアップの種類
バックアップの種類をコマンドレベルでまとめました。
大別すると、HANA組み込みのファイルベースのバックアップと、外部のファイル複製機能を使うストレージスナップショットベースのバックアップがあります。
ファイルベースの場合、従来からあるフルに加えて、SPS10からデルタバックアップが使用可能になりました。デルタバックアップは、さらに、累積差分ページを取る増分バックアップと常に全開との差分ページだけを取る差分バックアップの2種類に分かれます。
ストレージスナップショットベースのバックアップは、HANAの外部のコピー機能を使います。cpコマンドでもtarコマンドでも機能はしますが、一般的には短時間で完了するストレージシステム付属のスナップショット機能を使用します。この場合、静止点を確保するためにBACKUP DATA CREATE SNAPSHOTコマンドを直前で実行します。バック終了後はBACKUP DATA CLOSE SNAPSHOTコマンドを使用してHANA内部のスナップショットの削除や後始末を行います。外部機能で取ったバックアップが有効(将来バックアップに使うという意味)な場合SUCCESSFULを、無効な(取ったが破棄することにした)場合や失敗した場合にはUNSUCCESSFULを指定します。

BackIntによるバックアップの説明は割愛します。動作は、ファイルベースのバックアップに準じると理解してください。
SPS12よりストレージスナップショットとHANAのデルタバックアップの組み合わせがサポートされました。(2016.05.13.追記)
リストアのシナリオ
前述の通り、フルバックアップ→デルタバックアップ→ログバックアップの順に、つまり、ある時点の物理ページ全体→その後の差分物理ページ→その後の差分トランザクション、と適用するのが基本的な考え方です。
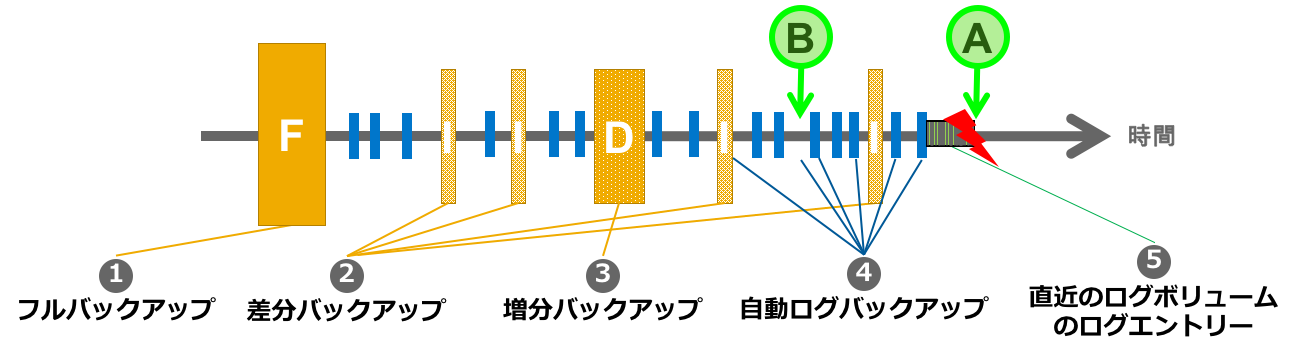
従いまして、上図で障害発生の時点A、つまり直近の状態までリカバリーするときには、
- フルバック①をリストア
- +後続の増分バックアップ(③)をリストア
- +後続の差分バックアップ(③以降の②)をリストア
- +後続のログバックアップ(最後の②以降の④)
- +オンラインログ(⑤)(ログボリュームが障害で失われず、かつ、適用可能な場合)
という順位になります。
また、任意の時点(例えばB)に戻すときも考え方は同じですがどの時点かにより使わないものが出てきます。
- フルバック①をリストア
- +後続の増分バックアップ(③)をリストア
- +後続の差分バックアップ(③以降かつB以前の②)をリストア
- +後続のログバックアップ(上記以降の④)
この辺りの、どのバックアップを使うかは、リストアの初期の段階で”リカバリーストラテジーの決定”というフェーズでHANAが決めてくれます。
バックアップファイルの管理
HANAがバックアップファイルの管理を行っている片鱗を見てみます。
以下は、インストール後、フル→増分→差分→差分というオペレーションを行った後のバックアップファイルの出力先です。
ちなみに、HANA Studioによる実行ですが、以下に相当するコマンドが発行されているはずです。
- BACKUP DATA USING FILE('COMPLETE_DATA_BACKUP');
- BACKUP DATA INCREMENTAL USING FILE('INC_DATA_BACKUP');
- BACKUP DATA DIFFERENTIAL USING FILE('DIFF_DATA_BACKUP')
- BACKUP DATA INCREMENTAL USING FILE('INC_DATA_BACKUP');

また、以下はM_BACKUP_CATALOGというシステムビューでバックアップの実行状況を参照できます。

ビュー中、ENTRY_TYPE_NAMEが”complete data backup”となっている行は1行しかありませんので、フルバックアップのBACKUP_IDは1460359737239であることがわかります。
デルタバックアップはネーミングルールで
- <プレフィックス>_'databackup_differential'_<先行のバックアップのID>_<自分自身のID>_<volume ID>_<partition ID>
- <プレフィックス>_'databackup_incremental'_<先行のバックアップのID>_<自分自身のID>_<volume ID>_<partition ID>
ですから、1460359737239を先行とするのは6−8行目の増分バックアップと11-13行目の差分バックアップということになりますが、増分→差分の場合はこのようにはならないので、11-13行目→6−8行目ということがわかります。(図中、赤で示した部分)
さらに、14-16行目の先行が6−8業目となっています(図中、黄で示した部分)ので全体としては、
- 1−4行目→11-13行目→6−8行目→14-16行目
であり
- フル→増分→差分→差分
ということになります。タイムスタンプを見ればわかるといえばそれまでですが、HANAがリカバリーストラテジー作成のための情報管理をしいてることはわかると思います。
ファイルベースのバックアップ
ファイルベースのバックアップは、バックアップの書き込みまでをHANAが行います。機能的には、ローカルファイルシテムに書き出しますが、HANAアプライアンスハードウェアの障害に対応するために通常はNFSなどによりマウントされた外部ストレージに書き込むようにします。
データボリュームの仕様が公開されていないので説明しにくいのですが、丸ごとバックアップファイルにコピーするのではなく、ペイロードと言われるヘッダーなどを除いた部分のみコピーします。
また、データボリュームの読み込みの際、チェックサムによる誤り検出および訂正を行います。
バックアップ手順
ファイルベースのバックアップの処理フローは以下の通りです
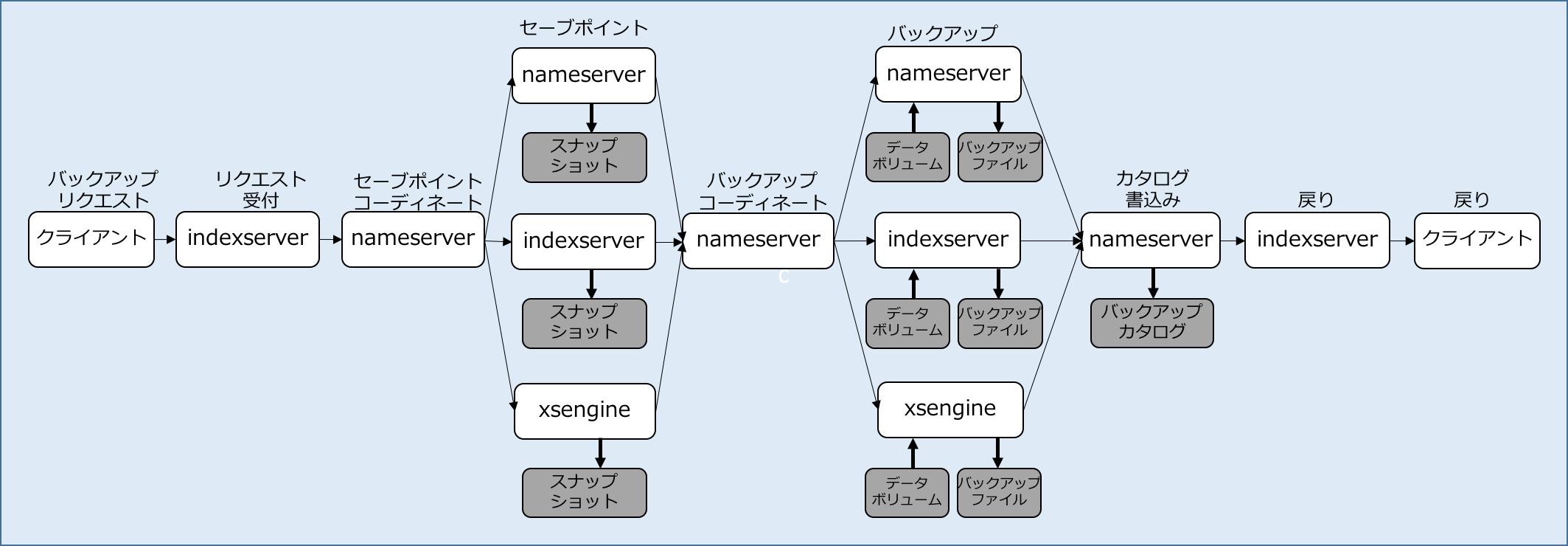
- HANA Studioやhdbsqlからバックアップコマンドを実行
- 一旦indexserverが受付、nameserverに依頼されます。以降、マスターnameserverがバックアップのコーディネートを行う
- マスターnameserverは、データベースを保持するサービス(ここでは、nameserver自身、indexserver、xsengine)に対してセーブポイントを指示します。この時nameserverは各サービス間のセーブポイントが一貫性を維持するように調整をします。
- 各サービス(nameserver、indexserver、xsengine)は更新された論理ページをデータボリュームに書き出します。前回の投稿で説明したように、新しい物理ページが割り当てられ、変換テーブルが再作成され、これがスナップショットとして保存されます。
- マスターnameserverは各サービスにバックアップを指示します。
- 各サービスは、データボリュームをバックアップファイルにコピーします。
- 最後に、nameserverは、バックアップカタログへの書込みを行って完了します。
ポイントは、以下の2点です。
- HANAでは幾つかのサービス(ここでは、nameserver、indexserver、xsengine)がデータベースを持っているわけですが、それぞれ別のファイルにバックアップされます。これら複数のバックアップが同期が取れている必要があり、このあたりの制御をマスターネームサーバーがやってくれる
- セーブポイントが実行されるとデータボリューム内に静止点としてのスナップショットが書かれ、データボリュームごとバックアップが取られる
個人的に面白いと思うのは、スナップショットの部分だけをバックアップしているのではなく、データボリューム全体をコピーしていることです。データボリュームの中には、バックアップ用に作った静止点であるスナップショットと直近のセーブポイントの少なくとも2つの状態が含まれていることになります。セーブポイントの方は、スナップショットと同じ内容なのか、次の世代なのかはわかりません。静止点以降の更新内容はスナップショット+Redoログでリカバリーされるのでわかる必要もありません。
リストアの時に(セーブポイントからではなく)スナップショットからデータベースが起動(メモリーロード)されさえすれば問題はないことになります。記憶の良い方は、前回のブログの最後のクイズを思い出すかもしれません。
リストア手順
ファイルベースのバックアップからのリストアは、バックアップファイルからデータボリュームへの戻しと、スナップショットからのメモリーロードが主なプロセスになります。通常のHANAのブート手順では、(シャットダウン時に作成された)セーブポイントからメモリーロードを行うのに対して、リストアにともなうデータベース起動ではスナップショットからメモリーロードが行われる、という点が違います。
具体的には、以下のようなプロセスになります。

- クライアントからバックアップスクリプトを実行します。バックアップスクリプトは以下のような形式です。RECOVERY DATABASE以降がリストアのためのSQLで、PythonスクリプトであるrecoverSys.pyの部分は、SQLを基に使用するバックアップを決めたり、HANAシステムのシャットダウンを行います。
- HDBSetting.sh recoverSys.py --command "RECOVERY DATABASE ...
- HANAシステムが停止すると、スクリプトはマスターネームサーバーをリストア用の特別なモードで起動し、リカバリースクリプトを取得したり、バックアップファイル内の情報でバックアップとリストアされるHANAシステムのサービスプロセス構成(indexserverなど)が一致するかも確認します
- マスターネームサーバーはHANAインスタンスをスタートします。起動された各サービスにリストアの指示が出ます。
- 各サービスは該当するバックアップファイルからデータボリュームへコピーを開始します。
- リストアが終了すると、データベース起動のための各処理を実行します。
- ログリプレイのためにテーブルをメモリー上にロードする
- ログバックアップとオンラインRedoログからログを読み込みリプレイする。等
- ログリプレイが完了するとサービス可能な状態になります。
最初のポイントはリストアのフェーズで、各プロセスはスナップショットの部分だけではなく、データボリューム全体をリカバリーします。つまり、先に述べたメモリーロードをセーブポイントから行うか、スナップショットから行うか、はまだ解決されていません。。
次のポイントは、ログリプレイのフェーズで、Redoログリプレイのためには、基になるテーブルが必要ですので、実際にリプレイが始まる前に対象テーブルのメモリーロードが行われます。重要なのはここで、通常のブートであればセーブポイントから行われるべきメモリーロードをスナップショットから行うことによりHANAはバックアップを取った静止点の時点へのリカバリーをしようとするわけです。
ストレージスナップショットベースのバックアップ
ファイルベースのバックアップはHANAインスタンスが、静止点状態の確保からデータボリュームのコピーまでの全てを管理実行しますが、データベースのサイズが大きくなるとコピーに要する時間が長期化します。この問題への対策としてストレージスナップショットベースのバックアップがあります。これは、データボリュームのコピーを文字通りストレージシステムのスナップショット機能に任せることにより時間短縮を図ろうとする機能です。
(紛らわしいので、以降では、HANAのスナップショットを内部スナップショット、ストレージによるスナップショットをストレージスナップショットと呼びます。)
HANAが行うのは、内部スナップショットの生成と削除のみです。内部スナップショット作成→ストレージスナップショット実行→内部スナップショット削除は一連の連続したオペレーションであるべきですが、機能の実装上、実行の主体がHANA→ストレージ→HANAと変わるため、データベース管理者(またはシステム運用管理ツールなど)が全体を管理する必要があります。

バックアップ手順
ストレージスナップショットベースのバックアップの手順は、下図の通りです。(クライアントとnameserverの間のindexserverは省略していますが、実際はファイルベースの場合と同様の動作となります。)
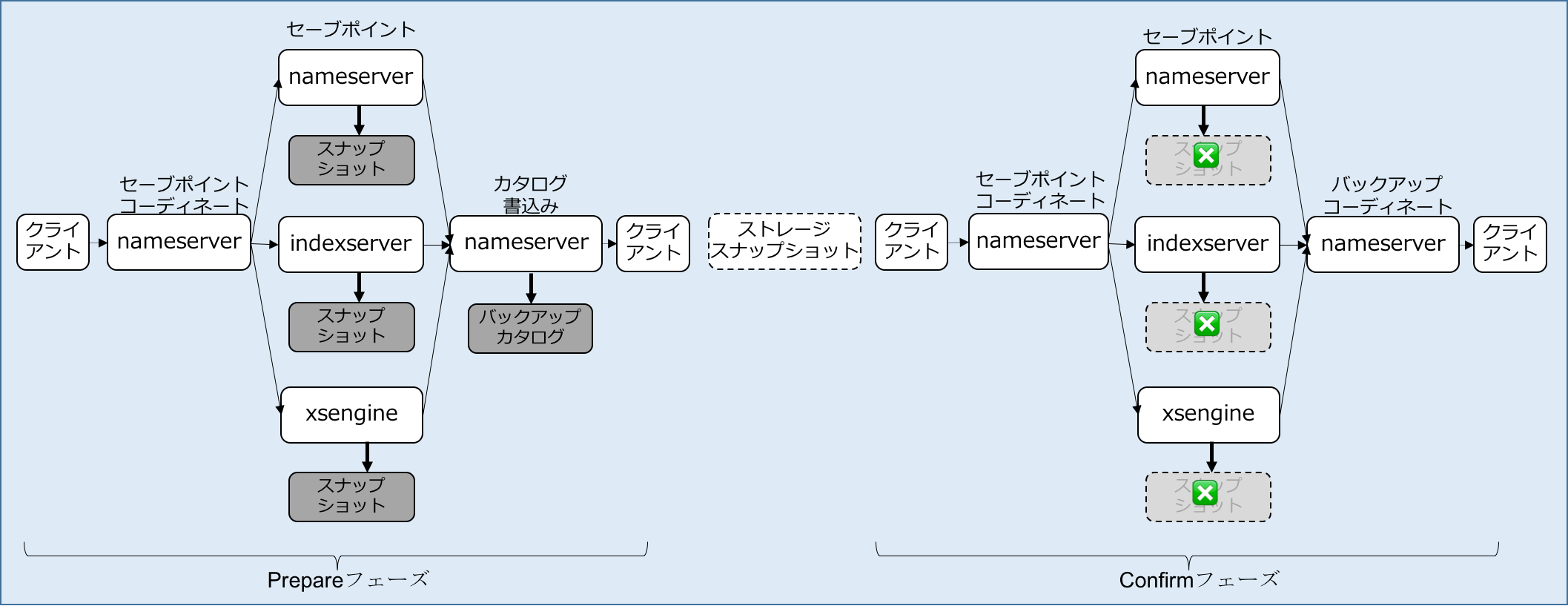
前述の内部スナップショットを作成する過程がPrepareフェーズ、削除する過程がConfirmフェーズです。PrepareとConfirmの間でストレージスナップショットが実行されます。
Prepareフェーズ
- クライアントからコマンドが実行されると、indexserver経由でnameserverにスナップショット作成が依頼されます。
- コマンド例:BACKUP DATA CREATE SNAPSHOT
- nameserverは各サービスに、セーブポイントの実行を指示します。各サービス間の同期はnameserverがとります。各サービスプロセスは、変更された論理ページを物理ページとして書き出し、最終的にスナップショットを作成します。
- nameserverは、バックアップカタログにスナップショットの情報を書き込み終了します。(下図=SYS.M_BACKUP_CATALOG)
Prepareフェーズは以上で完了ですが、運用上はここで必ずSYS.M_BACKUP_CATALOGを参照する必要があります。これは、後続のConfirmフェーズで必要となるBACKUP_IDを得るためです。以下は、コマンド実行直後のSYS.M_BACKUP_CATALOGの内容で、BACKUP_IDは1458795924881となっています。

ストレージスナップショット フェーズ
- ストレージスナップショットを実行します。このフェーズはストレージ製品に依存します。
データボリュームを複製できればいいので、テストや実習の時は、ディレクトリー全体をコピー出来るコマンドであればcp -Rやtarなどのコマンドでも使えます。
注意点は、データボリュームのみを対象とし、ログボリュームまでストレージスナップショットの対象としない、ということです。そうしないとログバアックアップによるリカバリーができなくなります。
Confirmフェーズ
- Prepareフェーズと同様にコマンドが実行され、indexserver経由でnameserverにクローズ処理が依頼されます。
- コマンド例:BACKUP DATA CLOSE SNAPSHOT BACKUP_ID 1458795924881 SUCCESSFUL 'Snapshot-based backup test';
- indexserver経由で指示を受けたnameserverは、各サービスプロセスにデータべース起動を指示します。
- 各サービスプロセスは、データボリューム内のスナップショットを削除します。
- nameserverはバックアップカタログへの書込みを行います。
基本的な考え方は、ファイルベースの場合とほぼ同じで
- スナップショットをデータボリュームに書き込む
- データボリュームごと複製退避する
2点です。
ファイルベースの時に行っている符号誤りのチェックは、ストレージスナップショットに依存することになりますので、チェックの有無や粒度には導入前に確認が必要です。
また、Confirmフェーズでは、スナップショットを削除するという重要な作業を行っています。スナップショットは、更新が多発するデータベースでは容量を圧迫することになる上、次のスナップショットを作るには現存のものを削除する必要があります。ストレージスナップショットを終えると速やかにConfirmフェーズを実行します。
リストア手順
スナップショットベースのリストアは、ストレージスナップショットのリストアとリカバリースクリプトの実行に分かれ、前者はストレージシステムに依存し、後者はHANAが行う処理です。
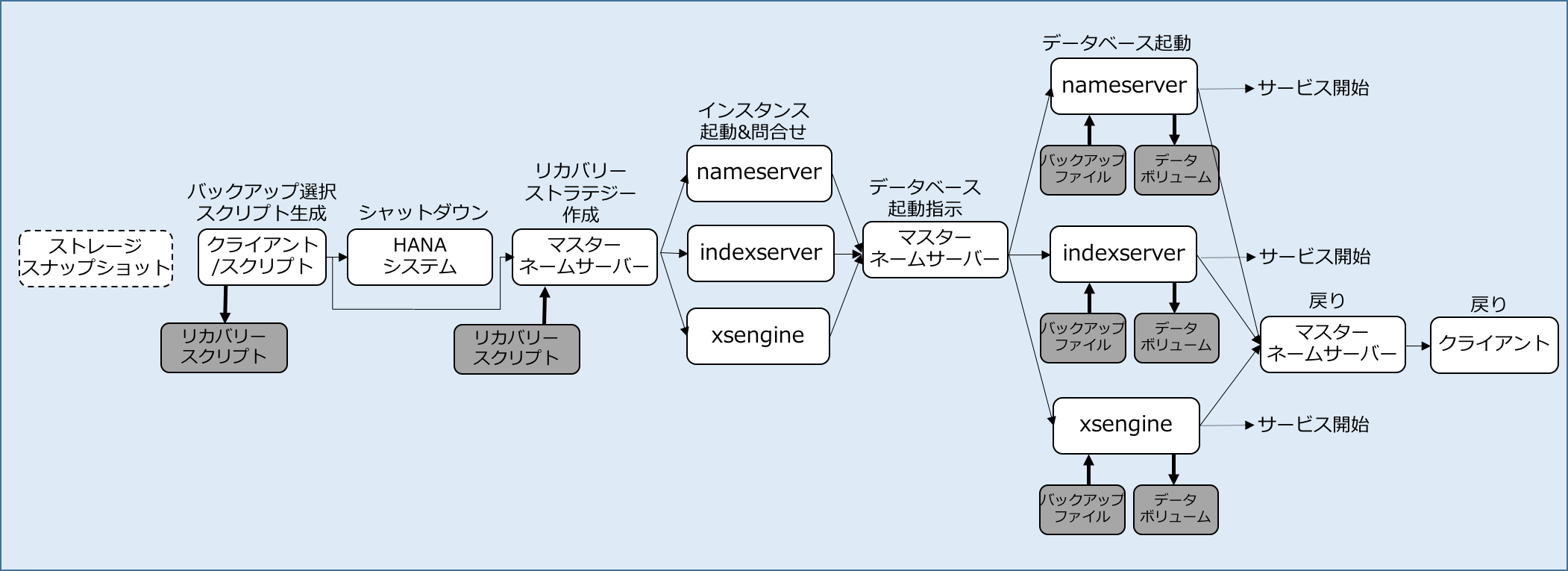
- ストレージシステムのスナップショットのリストア機能を使用してデータボリュームをリストアする
- HANA Studio、hdbsqlからリカバリースクリプトが実行されます。
- RECOVER DATABASE UNTIL TIMESTAMP '2016-03-31 12:00:00' USING SNAPSHOT CHECK ACCESS ALL;
- (起動していた場合は)HANAシステムをシャットダウンします。
- リカバリー用の特殊なモードでマスターnameserverを起動、マスターnameserverはリカバリースクリプトを読みリカバリストラテジーの決定、サービスプロセスを起動します。
- サービスプロセスは起動するとマスターnameserverに次のタスクを問い合わせします。マスターnameserverはスナップショットによるデータべース起動を各サービスぷろせすに指示します。
- 各サービスは、以下のような処理を行います。
- スナップショットからのデータベースの起動
- ログリプレイを実行、等
- バックアップカタログへの書き込み、サービス開始
以上、バックアップ/リストアのメカニズムとセーブポイント、スナップショットがどのような役割を果たすかを説明しました。
次回は、システムレプリケーションの仕組みと、永続化、バックアップ、システムレプリケーションが内部的には似たような動きであり、いづれもスナップショットが重要な役割を果たしている、というお話をしたいと思います。
- SAP Managed Tags:
- SAP HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
94 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
307 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
350 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
436 -
Workload Fluctuations
1
Related Content
- Another chapter of Secure By Default for SAP S/4HANA 2023 in Technology Blogs by SAP
- SAP HANA Cloud Migration: Setup your on-premise HANA system for the Self-Service Migration tool in Technology Blogs by SAP
- Implement a Node.js module (without xsjs support) to populate with HANA DB artifacts in HANA XSA in Technology Blogs by Members
- SAP HANA - Cannot Create Table Function in Technology Q&A
- MTA project Integration with Git in Business Application Studio: HANA XSA in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 25 | |
| 17 | |
| 11 | |
| 11 | |
| 9 | |
| 9 | |
| 9 | |
| 8 | |
| 8 | |
| 7 |