
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hana Data Lake Files as Object Store in SAP AI Cor...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-05-2023
12:58 AM
SAP AI Core supports connnecting multiple hyperscaler object stores, such as Amazon S3, OSS (Alicloud Object Storage Service), SAP HANA Cloud, Data Lake and Azure Blob Storage. The connected storage stores your dataset, models and other cache files of the Metaflow Library for SAP AI Core.
I will introduce an example on how to connect HANA Data Lake to SAP AI Core, then use the files located in Data Lake within the AI Core workflow and serving.
0. Prerequisites of the example
- BTP Subaccount is available and already add service plan SAP HANA Cloud (relational-data-lake) and SAP AI Core (standard) in the entitlement.
- AI Core and Hana data lake service instances were created
- AI Launchpad was created
1. Generate Client Certificate and Key for Hana Data Lake Files
Once the hana data lake instance was created successfully, to connetct the instance, the client certificate and client key are necessary. There is already a blog post that details how to establish the initial access to data lake files. Please refer to it to generate the certificate and key.
After this step, you can find client.crt and client.key flies generated in your folder which you executed the commands.

We can manage the Hana Data Lake Files using Hana Database Explore.
Add an instance:

2. Prepare Object Store Secret JSON Content
AI Core requires the data lake details in the following JSON format:
{
"name": "<object store secret name>",
"type": "webhdfs",
"pathPrefix": "<path prefix to be appended>",
"data": {
// e.g. https://c32727c8-4260-4c37-b97f-ede322dcfa8f.files.hdl.canary-eu10.hanacloud.ondemand.com
"HDFS_NAMENODE": "https://<file-container-name>.files.hdl.canary-eu10.hanacloud.ondemand.com",
"TLS_CERT": "-----BEGIN CERTIFICATE-----\nMIICmjCCAYIxxxxxxxxxxxxR4wtC32bGO66D+Jc8RhaIA==\n-----END CERTIFICATE-----\n",
"TLS_KEY": "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADANBgkqxxxxxxxxxxxxnor+rtZHhhzEfX5dYLCS5Pww=\n-----END PRIVATE KEY-----\n",
"HEADERS": "{\"x-sap-filecontainer\": \"<file-container-name>\", \"Content-Type\": \"application/octet-stream\"}"
}
}
Match the data lake details to:
| <object store secret name> | e.g. myhdl |
| <path prefix to appended> | path prefix is used to isolate different usage scenario set it according to your needs. |
| <file-container-name> | find it in the hana cloud central tools |
| HDFS_NAMENODE | same as above |
| TLS_CERT | open client.crt with text editor and copy the content, and encode the content with json encoder. Note: don't forget the last \n, there has a blank line at the end of certificate and key. |
| TLS_KEY | open client.key with text editor and copy the content, and encode the content with json encoder. |
3. Register the Object Store Secret into AI Core
The section Register an object store secret in help document introduced 2 ways: Using Postman and Using curl, I'll use AI Launchpad to register the secret.
Copy following json content prepared in second step to the Secret parameter.
{
// e.g. https://c32727c8-4260-4c37-b97f-ede322dcfa8f.files.hdl.canary-eu10.hanacloud.ondemand.com
"HDFS_NAMENODE": "https://<file-container-name>.files.hdl.canary-eu10.hanacloud.ondemand.com",
"TLS_CERT": "-----BEGIN CERTIFICATE-----\nMIICmjCCAYIxxxxxxxxxxxxR4wtC32bGO66D+Jc8RhaIA==\n-----END CERTIFICATE-----\n",
"TLS_KEY": "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADANBgkqxxxxxxxxxxxxnor+rtZHhhzEfX5dYLCS5Pww=\n-----END PRIVATE KEY-----\n",
"HEADERS": "{\"x-sap-filecontainer\": \"<file-container-name>\", \"Content-Type\": \"application/octet-stream\"}"
}

After click Add, the secret will be stored in AI Core.
4. Create a Dataset Artifact
In order for the AI Core pipeline to use the files located in Data Lake, we need to create the artifact in AI Core, and specify the name of the artifact and its address.
The address is not the actual address in the Data Lake, it's a logical address made up of Object Store Secret name + /path/file.
Notes:
For Data Lake, the address must end with a file, due to Data Lake API used in AI Core is Open, so without the file, api will run to error.
The object store secret name represent the hostnode + prefix defined in registering an object store secret.
The concept of the artifact url address:

Create dataset in the AI Core for training pipeline consumption:

More details for create file on help document.
5. Register an "default" Object Store Secret for Hana Data Lake
Perhaps you also have the same question - why the "default" object store secret is required?
It is compulsory to create a object store secret named default within your resource group, for your executable to generate models and store them in Data Lake. After execution the model will be saved to PATH_PREFIX_of_default/<execution_id>/modelin your Data Lake.
So the deault secret is used for storing the trained model.
the name must be "default", for the Secret, it's the same with step 3, and the prefix is also according to your needs.
6. Workflow Placeholders for Input and Output artifacts
Prepate a following yaml file to describe the workflow:
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: data-pipeline # executable id, must be unique across all your workflows (YAML files)
annotations:
scenarios.ai.sap.com/description: "Learning how to ingest data to workflows"
scenarios.ai.sap.com/name: "House Price (Tutorial)" # Scenario name should be the use case
executables.ai.sap.com/description: "Train with live data"
executables.ai.sap.com/name: "training" # Executable name should describe the workflow in the use case
artifacts.ai.sap.com/housedataset.kind: "dataset" # Helps in suggesting the kind of inputs that can be attached.
artifacts.ai.sap.com/housemodel.kind: "model" # Helps in suggesting the kind of artifact that can be generated.
labels:
scenarios.ai.sap.com/id: "learning-datalines"
ai.sap.com/version: "1.0"
spec:
# imagePullSecrets:
# - name: credstutorialrepo # your docker registry secret
entrypoint: mypipeline
templates:
- name: mypipeline
steps:
- - name: mypredictor
template: mycodeblock1
- name: mycodeblock1
inputs:
artifacts: # placeholder for cloud storage attachements
- name: housedataset # a name for the placeholder
path: /training_data/train.csv # where to copy in the Dataset in the Docker image
outputs:
artifacts:
- name: housepricemodel # local identifier name to the workflow
globalName: housemodel # name of the artifact generated, and folder name when placed in S3, complete directory will be `../<executaion_id>/housemodel`. Also used above in annotation
path: /output_artifacts/ # from which folder in docker image (after running workflow step) copy contents to cloud storage
container:
image: docker.io/ericwudocker01/house-price:03 # Your docker image name
imagePullPolicy: Always
command: ["/bin/sh", "-c"]
env:
- name: DT_MAX_DEPTH # name of the environment variable inside Docker container
value: "3" # will make it as variable later
args:
- >
set -e;
echo "---Start Training---";
python /src/main.py;
echo "---End Training---";
Notes:
- The path under inputs.artifacts must be end with a particular file, details can be found in Q&A.
- inthe outputs.artifacts, due to hana data lake doesn't support the disabling archive, the actual output is gzip file and store into data lake, to see help document for details.
7. Configuration and Execution in AI Core
The most important thing in configuration is binding the Artifact to the placeholder of input artifact.

After created the configuration we can start a execution with it.

The execution will:
- download the dataset from the data lake;
- copy it to the docker container (training);
- the training will generate a model and save it with artifact (located in path: <executionid>/model);
- the model also will be strored into data lake.
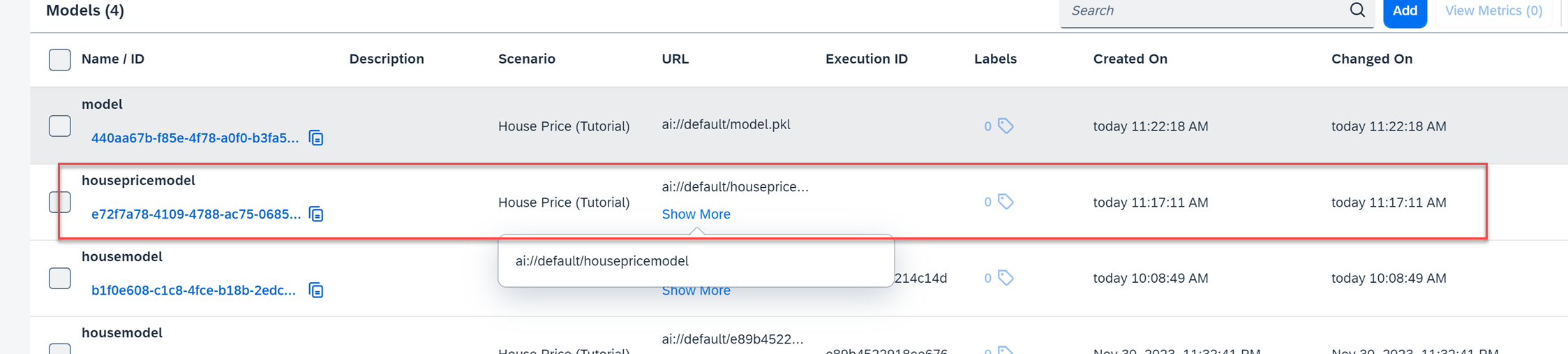
model in the data lake:

8. Summary
We have to genrate client certificate and key for consuming hana data lake, and register the details into object store secret (default for saving model and others for input artifacte), then we can use the file in configuration to match the placeholder defined in workflow and the actual file through artifact.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP AI Core,
- SAP HANA Cloud, data lake
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
95 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
310 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
353 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
441 -
Workload Fluctuations
1
Related Content
- HDI Artifact Recovery Wizard in Technology Blogs by SAP
- Vectorize your data for Infuse AI in to Business using Hana Vector and Generative AI in Technology Blogs by Members
- Extract blob data (PDF) from CAPM using python library of Document information extraction service. in Technology Blogs by Members
- Print Array in email, Fiori application - (webcontent) SAP BUILD automation, not working in Technology Q&A
- Object store secret mys-object-store-secret not found in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 19 | |
| 14 | |
| 12 | |
| 11 | |
| 10 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |