
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Building GenAI powered Data-Driven Applications on...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-25-2023
7:46 PM
Why GenAI Now?
The recent announcements about SAP partnering with Microsoft to build enterprise-ready innovative solutions excited us about the future of SAP solutions. And the integration with Microsoft Azure Open AI to access language models securely got us to think about productive use cases that might fit SAP HANA Cloud/SAP Datasphere scenarios. Again, the use case we are discussing is our perspective and nothing related to any official roadmap/messaging. And the objective is that going through use cases as such will help you map similar ideas in your respective areas. Or you could learn the technical deployments that might help you. The use case was also presented at SAPPHIRE/ASUG 2019, consuming AI Business services. Still, we could do it differently based on Generative AI (AI) since we can access powerful language models (Open AI) through Microsoft Azure Cognitive Services. So here we go 😊
What’s the Use-case?
The objective was to extract budget intelligence from reports published as pdf or Word documents from the contractor sites. And the reports were updated weekly/monthly. Certain assets maintained in their SAP system were of interest and required additional information, such as program elements and the associated budget information. In the past, analysts scanned the documents manually, captured the relevant information, and matched the relevant data with SAP assets. The information would be available as reports for key business users to make appropriate decisions. Another ask was to extract asset-related details from press releases updated on the same contractor sites to understand the market trends. Now, these were registered users, and they were allowed the extract the information as it is done in compliance with applicable regulations. The solution was tested in 2018, and the data was captured, as you see in the data flow.

The whole flow involves analysts, data quality teams, and finally, the business users who review both the assets and the information processed from documents related to assets. The solution works, but there are many repetitive tasks here, and Business users need to explore the documents, like executing self-service reports on the documents directly. This also aligns with what SAP is trying to convey in this article on Joint Generative AI(GenAI) offerings that help avoid repetitive work and provide more freedom to business users to explore the documents without needing data pipelines to extract content from unstructured documents.
How would you do it now?
How about executing the query on the documents or online resources directly without data pipelines?
Let me explain the same scenario with an architecture involving SAP Datasphere/SAP HANA Cloud, Cloud Storage, Azure Cognitive services (Azure Open AI), and Azure app service. The base logic is built as Python script and extended as a Django app, a high-level Python web-based framework. And the app is deployed on Azure app services using private git repositories. We could have deployed the app on SAP BTP, Kyma runtime too. But hey, let’s learn something new.
The app consumes the Azure Open AI deployment models based on the Django framework. The user sends the prompt from the front end, such as getting the summary of the press release statements or looking for specific keywords and retrieving a summary. The user would also mention the SAP HANA Cloud /Datasphere table the app needs to refer to for the source URLs or document path. We will extract the text from the document using relevant libraries and split the extracted text into segments. The segments are sent to the Azure AI deployment model (the base model being text-davinci-003 and the segment summaries are appended before presenting to the Business users using the app. The generated summary and all the prompt history are also stored in the same table for the Business Users using SAP Analytics Cloud. And business users can prompt different queries now, and the generated responses are updated accordingly. You could update the generated response in the same table. Or you could set up a system-version table to analyze historic prompts too. Now that we have the asset-related document information stored in a table, this could be blended with SAP data sources having additional information about assets in SAP HANA Cloud or SAP Datasphere and could be visualized in SAP Analytics Cloud. I hope you get the context based on the actual use case. I am using the standard Azure Open AI deployment models directly but will build custom models for our specific data sources, train them, and share the feedback in future blogs.

I'll explain the design with two deployment options in the current scenario.
Option 1: Customer scenario by reading the online press release statements. (Instead of press statements, I am just using some blogs for the demo purpose)
Option 2: Scenario with all the documents available in cloud storage (Azure Blob).
Option 1 - Customer scenario by reading the online press release statements.
As mentioned previously, release statements and budget statements were available online on their registered sites, and they had prior permission to harvest the data. The Asset ID and the corresponding online sources are stored in a table in SAP HANA Cloud/ SAP Datasphere, as shown below. And the generated response and Asset ID will be blended with SAP Data sources for reporting or consuming in-app.

For this scenario, let’s discuss the architecture and data flow.

- User sends the prompt to get a summary or specific information from budget documents or press releases. The user also provides the table where the online documents are stored.
- App accesses the asset ID and corresponding online URL and extracts text using BeautifulSoup, a python package for extracting html documents.
- The extracted text is split into segments and sent to the app. The app redirects the prompt and segmented text to the Azure Open AI deployment engine, and the response is captured back. Business users using the app can analyze the documents directly in the app. And we must split the request sent to the language model because the OpenAI GPT (Generative Pre-trained Transformer) language model has a maximum context length of 4096 tokens. And the blogs I send as a request are way more than 4096 tokens.
- The response is updated into a new column of the same table using Asset ID as an index. The table is part of an OpenSQL container attached to a space. To store all the prompts, create a system-versioned table on SAP HANA Cloud / SAP Datasphere. And you will have the recent prompt in the active table and the rest in the history table. The business user can visualize an asset’s historical prompts using SAP Analytics Cloud.
- Asset data from the SAP portfolio is federated or replicated into a space.
- We use data builder to blend the OpenSQL containers and SAP systems data.
- Data is visualized using SAC
Here is the Python script for Option 1. I will share the GIT repository for the app later this week as some adjustments need to be made. Please note that the script provided here will differ from the script used in the Django app.
from hana_ml import dataframe
import openai
import pandas as pd
import requests
from bs4 import BeautifulSoup
import os
from dotenv import load_dotenv
load_dotenv()
hana_host = os.environ.get('HANA_HOST')
hana_port = os.environ.get('HANA_PORT')
hana_user = os.environ.get('HANA_USER')
hana_password = os.environ.get('HANA_PASSWORD')
# create a connection to SAP HANA database
conn = dataframe.ConnectionContext(hana_host, hana_port, hana_user, hana_password)
# read data from SAP HANA database into a Pandas DataFrame object
df = pd.read_sql('SELECT * FROM BTP2.TEXTURL_SV', conn.connection)
# Initialize OpenAI API key and other parameters
openai.api_key = os.environ.get('OPENAI_API_KEY')
openai.api_base = os.environ.get('OPENAI_API_BASE')
openai.api_type = 'azure'
openai.api_version = '2023-03-15-preview'
# Define a function that uses OpenAI's GPT-3 model to generate a descriptive summary of text
def get_summary(url, prompt):
# Get HTML content of web page using requests library and parse it using BeautifulSoup library
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract text content from web page using BeautifulSoup library and remove any newlines or extra spaces
text = soup.get_text().replace('\n', ' ').strip()
# Check if any specific terms are present in text before generating summary
# search_terms = ["databricks", "spotify","amazon","codewhisperer" ,"playlist"] # Replace with your desired search terms
# if any(term in text for term in search_terms):
url_str = f"{url}\n"
max_segment_length = 2000 # Set the maximum length for each segment
# Split text into segments of a certain length and process each one separately
segments = [text[i:i+max_segment_length] for i in range(0, len(text), max_segment_length)]
summaries = []
for segment in segments:
prompt_str = (f"{prompt}\n"
f"{url_str}"
f"{segment}\n"
f"Description:")
response = openai.Completion.create(engine="ai4sap", prompt=prompt_str, max_tokens=100)
summary = response.choices[0].text.strip()
summaries.append(summary.replace("'", ""))
return "".join(summaries) # Concatenate all summaries together
#else:
# return ""
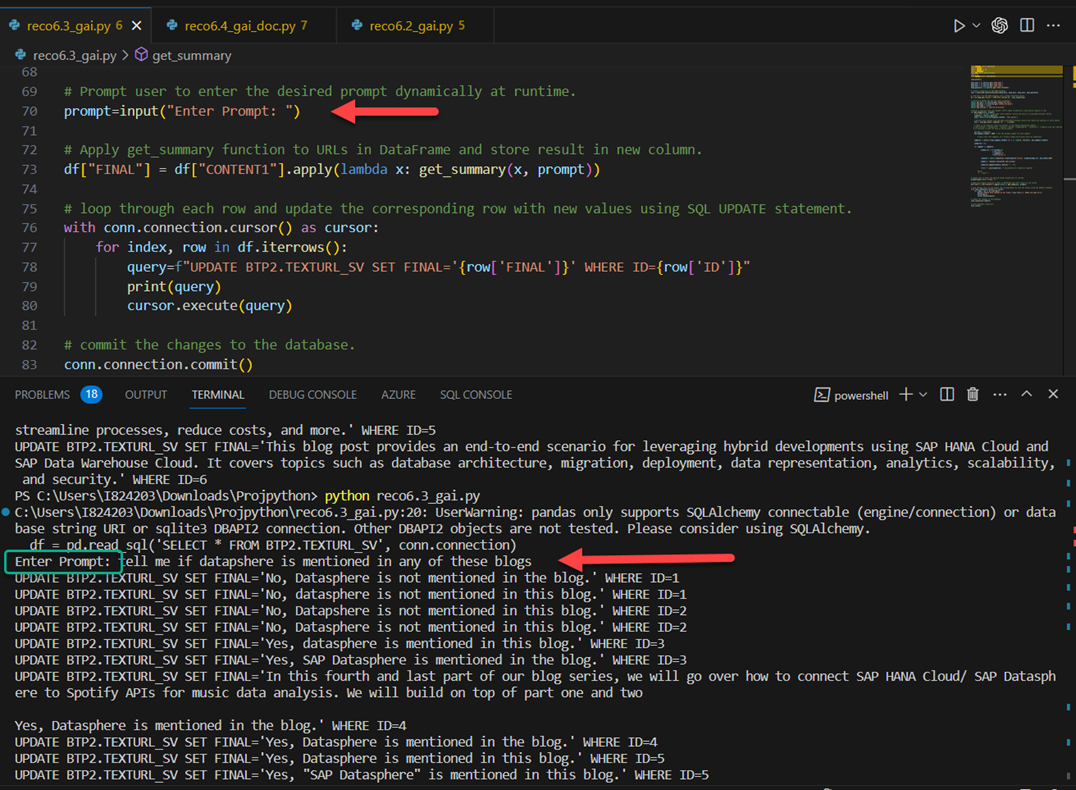
# Prompt user to enter the desired prompt dynamically at runtime.
prompt=input("Enter Prompt: ")
# Apply get_summary function to URLs in DataFrame and store result in new column.
df["FINAL"] = df["CONTENT1"].apply(lambda x: get_summary(x, prompt))
# loop through each row and update the corresponding row with new values using SQL UPDATE statement.
with conn.connection.cursor() as cursor:
for index, row in df.iterrows():
query=f"UPDATE BTP2.TEXTURL_SV SET FINAL='{row['FINAL']}' WHERE ID={row['ID']}"
print(query)
cursor.execute(query)
# commit the changes to the database.
conn.connection.commit()
# Close database connection.
conn.close()Before executing the script, please make sure you have the following:
- Installed all the necessary Python libraries
- Created a .env file with all the credentials for SAP HANA Cloud/SAP Datasphere so you don’t have to hardcode the credentials. The file should be within the same folder as the script.
- If you want to store the current response, create a column table. If all the prompts and responses are to be stored, then create a system-version table.
- And the Open AI Engine has to be changed according to the deployments in your Azure AI studio. Please refer the logic flow screenshot where I have mentioned about the same.
Here is a .env file for the provided script.
HANA_HOST=XXXXXXXXXXXXXXXX.hna0.prod-eu10.hanacloud.ondemand.com
HANA_PORT=443
HANA_USER=XXXXXXX
HANA_PASSWORD=XXXXXXXXXX
OPENAI_API_KEY=XXXXXXXXXXXXXXXXXXXXXXXXXXXX
OPENAI_API_BASE = https://XXXXXX.openai.azure.com/
#Adding these variables for Option 2
AZURE_STORAGE_CONNECTION_STRING = "DefaultEndpointsProtocol=https;AccountName=<>;AccountKey=<>;EndpointSuffix=core.windows.net"
AZURE_STORAGE_CONTAINER_NAME = <Contianer Name>And if you want to create a System-version table in SAP HANA Cloud/SAP Datasphere and store all the prompts and responses from Business Users, then you can create the table as mentioned below. Kindly adjust the script if you are going to change the table name.
#Create the table which you point as system version.
#Add all columns you want but the last two mandatory columns are mandatory
CREATE COLUMN TABLE "BTP2"."TEXTURL_SV_HIST"(
"ID" INTEGER,
"CONTENT1" NVARCHAR(5000),
"FINAL" NVARCHAR(2000),
"RESP_START" TIMESTAMP NOT NULL,
"RESP_END" TIMESTAMP NOT NULL
);
#Now Create the main table pointing to previous one as SYSTEM Versioning
CREATE COLUMN TABLE "BTP2"."TEXTURL_SV"(
"ID" INTEGER,
"CONTENT1" NVARCHAR(5000),
"FINAL" NVARCHAR(2000),
"RESP_START" TIMESTAMP NOT NULL GENERATED ALWAYS AS ROW START,
"RESP_END" TIMESTAMP NOT NULL GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME (resp_start, resp_end)
)
WITH SYSTEM VERSIONING HISTORY TABLE "BTP2"."TEXTURL_SV_HIST"Now your latest prompt will be stored in the table “TEXTURL_SV.” And the previous prompts will be stored in “TEXTURL_SV_HIST” with timestamps. If the Business users wanted to analyze the trend of the responses and visualize it in SAC, maybe it would help with additional insights.

Table TEXTURL_SV_HIST with past responses from Azure Open AI
As far as the code is concerned, I have added additional comments.

The request starts here with your prompt. And your prompt and source URL from the table is sent to the get_summary function.

Here are some comments about the logic flow of the function "get_summary". Please note the engine I used here is based on AI Studio Deployment and not directly from Open AI. Please refer this document in order to know the difference.

Finally, the generated response is updated in the column FINAL based on Asset IDS.

If you execute from the visual studio, you can see the prompt highlighted in the terminal and the corresponding output.
Option 2: Scenario with all the documents available in cloud storage (Azure Blob).
For this scenario, let’s discuss the architecture and data flow.

- User sends the prompt to get a summary or specific information from budget documents or press releases. The user also provides the table where the data is stored.
- App access the asset ID and corresponding Cloud storage path.
- App connects to the Azure Blob container and accesses the document(word document) based on the document path.
- The extracted document text is split into segments and sent to the app. The app redirects the prompt, segmented text to the Azure Open AI deployment engine, and the response is captured back. Business users using the app can analyze the documents directly in the app. And we must split the request sent to the language model because the OpenAI GPT (Generative Pre-trained Transformer) language model has a maximum context length of 4096 tokens. And the blogs I send as a request are way more than 4096 tokens.
- The response is updated into a new column of the same table using Asset ID as an index. The table is part of an OpenSQL container attached to a space. Create a system-versioned table on SAP HANA Cloud / SAP Datasphere to store all the prompts. And you will have the recent prompt in the active table and the rest in the history table. The business user can visualize an asset’s historical prompts using SAP Analytics Cloud.
- Asset data from the SAP portfolio is federated or replicated into a space.
- We use data builder to blend the OpenSQL containers and SAP systems data.
- Data is visualized using SAC
Here is the Python script for Option 2. I will share the GIT repository for the app later this week as some adjustments need to be made. Please note that the script provided here will differ from the script used in the Django app.
import os
from hana_ml import dataframe
import openai
import pandas as pd
import requests
from bs4 import BeautifulSoup
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient
import base64
import io
# Load environment variables from .env file in root directory of project.
from dotenv import load_dotenv
load_dotenv()
# Create a connection to SAP HANA database using environment variables.
hana_host = os.environ.get('HANA_HOST')
hana_port = os.environ.get('HANA_PORT')
hana_user = os.environ.get('HANA_USER')
hana_password = os.environ.get('HANA_PASSWORD')
conn = dataframe.ConnectionContext(hana_host, hana_port, hana_user, hana_password)
# Read data from SAP HANA database into a Pandas DataFrame object.
df = pd.read_sql('SELECT * FROM BTP2.STOREURL', conn.connection)
print(df)
# Initialize OpenAI API key and other parameters using environment variables.
openai.api_key = os.environ.get('OPENAI_API_KEY')
openai.api_base = os.environ.get('OPENAI_API_BASE')
openai.api_type = 'azure'
openai.api_version = '2023-03-15-preview'
# Connect to Azure Blob container using environment variables.
blob_service_client = BlobServiceClient.from_connection_string(os.environ.get('AZURE_STORAGE_CONNECTION_STRING'))
container_client = blob_service_client.get_container_client(os.environ.get('AZURE_STORAGE_CONTAINER_NAME'))
# Define a function that uses OpenAI's GPT-3 model to generate a descriptive summary of text.
def get_summary(path, prompt):
# Read word document from Azure Blob container.
try:
# Verify if blob exists before downloading it.
if not container_client.get_blob_client(path).exists():
raise Exception(f"The specified blob '{path}' does not exist.")
download_stream = container_client.download_blob(path)
content_bytes=download_stream.content_as_bytes()
# Load the binary content into a BytesIO object.
docx_file_like_object = io.BytesIO(content_bytes)
# Use python-docx library to extract text from Word document.
import docx
doc = docx.Document(docx_file_like_object)
text_list=[]
for para in doc.paragraphs:
text_list.append(para.text.strip())
# Combine all paragraphs into one string.
text=" ".join(text_list)
max_segment_length = 2000 # Set the maximum length for each segment
# Split text into segments of a certain length and process each one separately
segments = [text[i:i+max_segment_length] for i in range(0, len(text), max_segment_length)]
summaries=[]
for segment in segments:
prompt_str=(f"{prompt}\n"
f"{segment}\n"
f"Description:")
response=openai.Completion.create(engine="ai4sap", prompt=prompt_str, max_tokens=100)
summary=response.choices[0].text.strip()
summaries.append(summary.replace("'", ""))
return "".join(summaries) # Concatenate all summaries together
except Exception as e:
print(f"Error occurred while accessing {path} - {str(e)}")
# Prompt user to enter the desired prompt dynamically at runtime.
prompt=input("Enter Prompt: ")
# Apply get_summary function to CONTENT1 column in DataFrame and store result in new column FINAL.
df["FINAL"] = df["CONTENT1"].apply(lambda x: get_summary(x.strip(), prompt))
# Loop through each row and update the corresponding row with new values using SQL UPDATE statement.
with conn.connection.cursor() as cursor:
for index, row in df.iterrows():
query=f"UPDATE BTP2.STOREURL SET FINAL='{row['FINAL']}' WHERE ID={row['ID']}"
print(query)
cursor.execute(query)
# Commit the changes to the database.
conn.connection.commit()
# Close database connection.
conn.close()Before executing the script, please make sure you have the following:
- Installed all the necessary Python libraries.
- Created a .env file with all the credentials for SAP HANA Cloud/SAP Datasphere so you don’t have to hardcode the credentials. The file should be within the same folder as the script.
- If you want to store the current response, create a column table. If you wish all the prompts and responses to be stored, create a system-version table.
- In my example, you will see the word document being extracted. In case of other formats like pdf, you need to adjust the code to use packages like pypdf.
Please refer to Option 1 on setting up .env and system-version tables.
And regarding the code, I will add screenshots accessing the blog container. But the rest is the same as option 1. Please refer to the screenshots there to understand the flow.

When you store the file path in SAP HANA Cloud/SAP Datasphere, please keep the filename as such and not the whole URL, including connection strings.

In this option, instead of reading online blogs, we read the documents from cloud storage. In this case, we download the document as binary content and extract the text. Later we follow the same steps as option 1 to split the text into segments and send it to Azure Open AI deployment models.

The code execution would be the same as option 1, and the responses would be in a different table.

And if you check the history table (Option 1 or 2), all the responses for every asset would be stored by timestamp. And this would be good for business users to identify the trend.

Please make sure you have the Cloud storage keys, container, and path in SAP HANA Cloud set as mentioned and the code will work just fine!
OK, we got the script . But how does the app work?
Business users will have access to the app deployed on Azure App services [1]. As mentioned before, we could deploy this in SAP BTP Kyma or build an SAP CAP application with the base logic from Python. The app is built based on Django Framework. The Python script I shared before will be part of views, and the corresponding frontend to provide prompt and the data sources will be part of the HTML template. Once you provide the request and click submit, there will be an asynchronous AJAX post call from the template to the view. And the view will execute the Python script by making calls to SAP HANA Cloud/SAP Datasphere, Azure Open AI APIs & Azure blob storage. And the response is captured from view as data frames, converted to a dictionary, and finally displayed as a table in the app. Also, the AJAX POST call updates the back-end table too for SAC visualization. To test the web app, you do not have to deploy it on the Azure Web app. You can try it from the visual studio directly.

As you see the app below generating responses based on your prompts and data sources.

This way, business users can explore the documents and make decisions accordingly. And, of course, we can build custom models based on deployments in Azure AI studio, train with relevant datasets to generate desired responses, and have those models exposed through the app. These fit similar scenarios where you heavily depend on external data sources to make prompt decisions on data assets maintained in SAP systems.
And if you are interested in building the app end to end, please check for the GIT repository here later this week.
OK, what are the pre-requisites to set up Azure Open AI and Azure Web APP?
Let’s look into the steps:
- Pre-requisites
- Sign up for Azure Open AI service
- Setting up Azure Open AI Services.
- Setting up tables in SAP HANA Cloud
- Python Scripts (Already Shared)
- Django App (App will shared later this week)
- Azure App Deployment(Optional as you can test the app directly from Visual Studio Code)
Pre-Requisites for GenAI app
- Microsoft Azure Subscription
- Requesting preview access for Microsoft Open AI
- Setting up Azure Open AI.
- Compute where you can deploy the Python app. This could be SAP Kyma or external services like Google Cloud App Engine or Microsoft Azure App Services.
- SAP HANA Cloud or SAP Datasphere to blend the document data relevant to SAP assets with SAP data sources
Sign up for Azure Open AI service(Cognitive Services)
There is a difference between using Open AI vs. accessing the same through Microsoft Cognitive Services. In the latter case, Azure provides enterprise-level security, compliance, and regional availability. You can refer to the FAQ for additional details. And this brings us up to the next point: limited access to the services. Once you have an Azure subscription, you must request access to Azure Open AI service, as mentioned in this document. You will be redirected to the same document from your Azure subscription. You will receive the preview access, and please go through the conditions for “Limited Access Scenarios,” like content generation and terms on how you could use it now. One of the key differences in using Microsoft Open AI is that the prompt data are stored for 30 days within the same region and completely encrypted by Microsoft Managed Keys. In the case of accessing the Open AI directly, it stores the prompts to retrain or improvise the models.
And for GPT-4 preview access, you need to sign up separately. 😊 It would take a couple of days to receive this news. I am still on the waitlist for GPT-4 Azure Open AI access.

Setting Up Azure Open AI
Once you have preview access, you can create the services in the required regions. When creating custom models or fine-tuning, the services are restricted to specific regions. Please check the regional availability here.

You will get access to the keys and endpoints once you have created the services.

And you can deploy the relevant models for validating your scenarios.

You can also keep track of costs by looking into the cost analysis based on tokens used across your enterprise and the metering for the same.

OK, how to deploy the App on Azure App Services?
Deploying the app on Azure App Service is similar to deploying it in SAP BTP Kyma. When you create a new web app, you can provide the resource groups, the app’s name, and the runtime stack (Python/Ruby/Java/Go/.NET/Node).

The next step would be integrating your GitHub repo or Docker. This helped me to continue updating the changes in the branch I linked to the web app, and the web app automatically syncs and redeploys the changes. Once you select the relevant authentication, you can publish the app.

Once the web app is up, you will notice the Deployment Center with updates on the latest deployments. For any change on the git branches, you will see a status change automatically for redeployment.

What are the limitations?
There are lots 🙂
Even though I provided the data sources for the prompt, Azure Open AI could hallucinate facts.
- For example, some of the deployment models showed other SAP authors as the author of my blogs. Or it was providing content from sources other than the ones I pointed out in my tables.
- We will not know the source content for the responses generated by the deployment model.
- While testing the data, it was all fine till I changed the deployment model, and from that point, the content was taken from external sources and not mine.
One of the reasons I mentioned we still wanted to work on use cases where there is a significant dependency on external sources such as documents or videos. However, it adds value to users of SAP assets to make business decisions. And as mentioned, this is just our perspective rather than official messaging from SAP.
What are the follow-up contents?
As of now, all our testing and the models used for the app are focused on the base model of AI Deployment studio. We are in the process of testing the customized versions of base models trained for customized prompts. You will see the discussion on new apps based on custom models moving on. We will also discuss consuming REST APIs focusing on embeddings, fine-tuning, and completions and explain how we can work around the limitations. We will also discuss on how to extract and analyze content from videos. You will also see additional blogs as part of this GenAI App series from unnati.hasija , anja-katja.kerber & sarahmajercak
This is just a simple use case but think about how similar ideas could be used for use cases in Health Care, Pharmaceuticals, or the Retail Industry.
I hope you enjoyed reading the blog and please do share your feedback.
Happy Learning!
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
430 -
Workload Fluctuations
1
Related Content
- Expanding Our Horizons: SAP's Build-Out and Datacenter Strategy for SAP Business Technology Platform in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- Customers and Partners are using SAP BTP to Innovate and Extend their SAP Applications in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 31 | |
| 17 | |
| 15 | |
| 13 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |