Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
In conventional machine learning (the one existing on HANA Cloud PAL, for example), we can use some resampling methods to evaluate model performance. PAL provides model evaluation and parameter selection for some training algorithms, such as SVM and logistic regression.
But for LLMs, it's different. The MML Benchmark evaluates LLMs on knowledge and reasonability, but no uniform method exists for running it, whether we evaluate prompt sensitivity, the LLM, our RAG, or our prompts. Even simple changes like altering parenthesis can drastically affect accuracy, making consistent evaluation challenging.
The RAG ecosystem's evolution is closely tied to advancements in its technical stack, with tools like LangChain and LLamaIndex gaining prominence alongside emerging platforms like Flowise AI, HayStack, Meltano, and Cohere Coral, each contributing unique features to the field. Traditional software and cloud service providers are also expanding their offerings to include RAG-centric services, further diversifying the technology landscape. This divergence is marked by trends towards customization, simplification, and specialization, indicating a symbiotic growth between RAG models and their technical stack. While the RAG toolkit is converging into a foundational technical stack, the vision of a fully integrated, comprehensive platform remains a future goal, pending ongoing innovation and development.
Gao et al. Retrieval-Augmented Generation for Large Language Models
After SAP releases (will release) SAP HANA Cloud Vector Engine (still in preview, but you can use pgvector PostreSQL extension on BTP) and Generative AI Hub, both summarized in this blog post, you see SAP moving towards RAG (Retrieval Augmented Generation). RAG, a buzzword in the industry, focuses on knowledge search, QA, conversational agents, workflow automation, and document processing for our Gen AI applications.
Soon enough, you start playing around with a RAG implementation, it's easy to find ourselves in the middle of the challenges in productionizing applications; things like bad retrieval issues leading to low response quality, hallucinations, irrelevance, or outdated information are just a few examples that before bringing it to production you must set up the architecture ready to do an evaluation of our RAG system, emphasizing the need for relevant and precise results to avoid performance degradation due to distractors.
Defining benchmarks, evaluating end-to-end solutions, and assessing specific components of the retrieval is what I am going to discuss in this blog. NOT model / AI application evaluation (which is a topic for another day).
RAG Evaluation (concept)
RAG Evaluation is a vital step; you must establish benchmarks for the system 1) to track progress and 2) to make improvements.
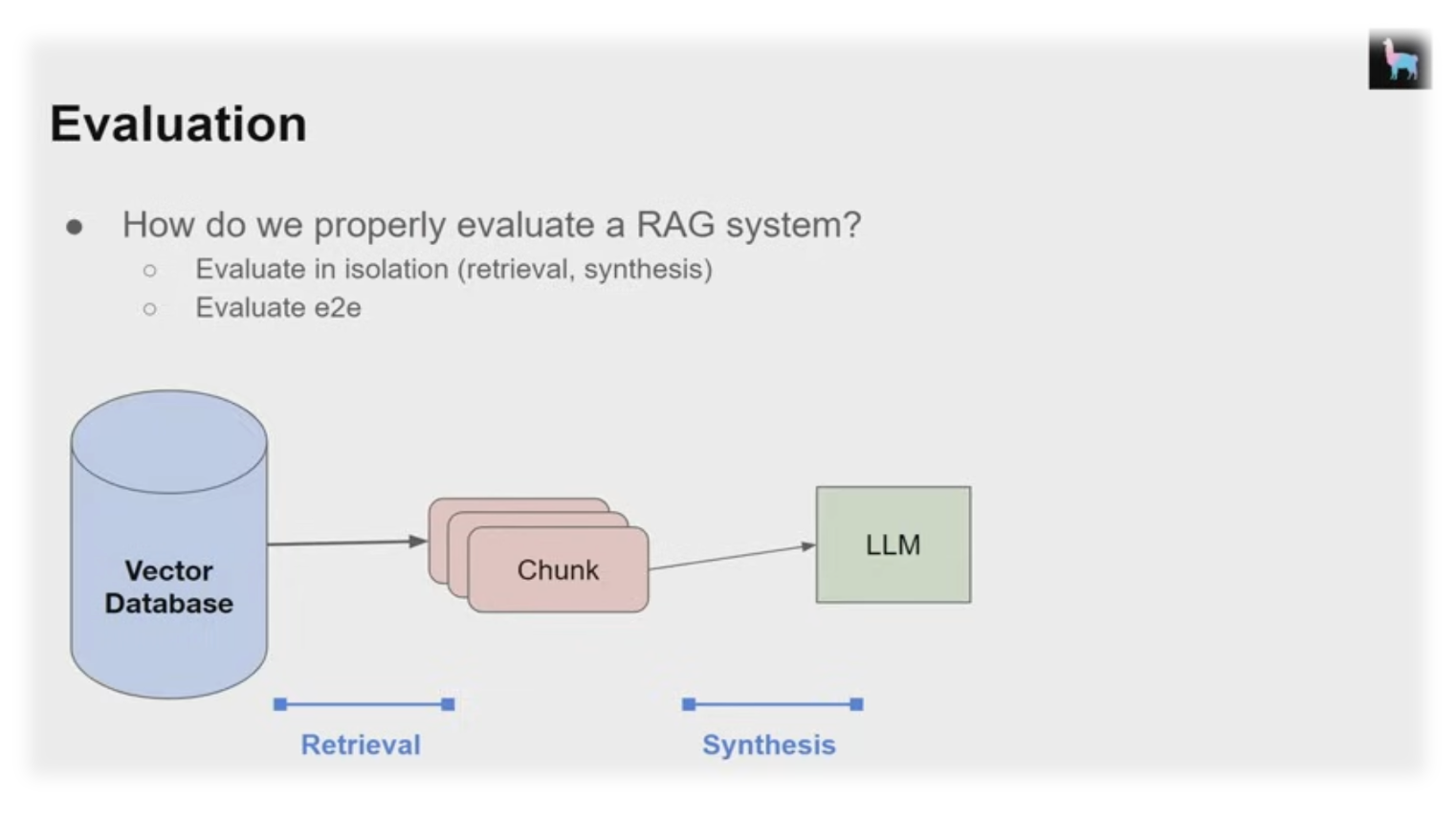
There are several approaches to evaluation. You need to evaluate both the end-to-end solution, considering input queries and output responses, and specific components of your system. For instance, if you've identified retrieval as an area for improvement, you'll need retrieval metrics to assess your retrieval system.
Evaluation in Isolation ensures that the retrieved results answer the query accurately and do not include irrelevant information. First, you need an evaluation dataset that pairs input queries with relevant document IDs. You can obtain such datasets through human labeling, user feedback, or even synthetic generation. Once you have this dataset, you can measure various ranking metrics.
In summary, it is a suite of metrics that measure the effectiveness of systems (like search engines, recommendation systems, or information retrieval systems) in ranking items according to queries or tasks. The evaluation metrics for the retriever module mainly focus on context relevance, measuring the relatedness of retrieved documents to the query question.
End-to-End Evaluation focuses after retrieval. After generating a response and evaluating the final response. You need another dataset to assess the quality of the responses generated from the input queries. This dataset can be created through human annotations, user feedback, or by having ground truth reference answers for each query. After obtaining this dataset, you can run the entire retrieval and synthesis pipeline, followed by evaluations using language models.
From the perspective of content generation goals, evaluation can be divided into unlabeled and labeled content. Unlabeled content evaluation metrics include answer fidelity, answer relevance, harmlessness, etc., while labeled content evaluation metrics include Accuracy and EM. Additionally, from the perspective of evaluation methods, end-to-end evaluation can be divided into manual evaluation and automated evaluation using LLMs.
While these evaluation processes might seem complex, retrieval evaluation has been a well-established practice in the field for years and is well-documented.
RAG Eval Frameworks (open source)
RaLLe
RaLLe is a framework for developing and evaluating RAG that appeared this Q4 2023.
A variety of actions can be specified for an R-LLM, with each action capable of being tested independently to assess related prompts. The experimental setup and evaluation results are monitored using MLflow. Moreover, a straightforward chat interface can be constructed to apply and test the optimal practices identified during the development and evaluation phases in a real-world context.
RaLLe's main benefit over other frameworks is it provides a higher transparency in verifying individual inference steps and optimizing prompts vs other tools like ChatGPT Retrieval Plugin, Guidance, and LangChain by providing an accessible platform.
You can check out RaLLe in this video.
ARES
ARES framework (Stanford University) requires inputs such as an in-domain passage set, a human preference validation set of 150+ annotated data points, and five few-shot examples of in-domain queries and answers for prompting LLMs in synthetic data generation. The first step is to initiate by creating synthetic queries and answers from the corpus passages. Leveraging these generated training triples and a contrastive learning framework, the nest step is to fine-tune an LLM to classify query-passage-answer triples across three criteria 1) context relevance, 2) answer faithfulness, and 3) answer relevance. Then, finally, LLM is employed to judge and evaluate RAG systems and establish confidence bounds for ranking using Prediction-Powered Inference (PPI) and the human preference validation set.
Unlike RaLLe, ARES offers statistical guarantees for its predictions using PPI, providing confidence intervals for its scoring.
RAGAS (People's Choice Award)
RAGAS provides a suite of metrics to evaluate different aspects of RAG systems without relying on ground truth human annotations. These metrics are divided into two categories: retrieval and generation.
Retrieval Metrics evaluate the performance of the retrieval system.
Context Relevancy measures the signal-to-noise ratio in the retrieved contexts.
Context Recall measures the ability of the retriever to retrieve all the necessary information needed to answer the question.
Generation Metrics evaluate the performance of the generation system.
Faithfulness measures hallucinations or the generation of information not present in the context.
Answer Relevancy measures how to the point the answers are to the question.
The harmonic mean of these four aspects gives you the RAGAS score, which is a single measure of the performance of your QA system across all the important aspects.
To use RAGAS, you need a few questions and a reference answer if you're using context recall. Most of the measurements do not require any labeled data, making it easier for users to run it without worrying about building a human-annotated test dataset first.
Below, you can see the resulting RAGAs scores for the examples:
RAGAs scores context precision, context recall, faithfulness, and answer relevancy.
The following output is produced by Ragas:
1. Retrieval: context_relevancy and context_recall which represents the measure of the performance of your retrieval system.
2. Generation : faithfulness, which measures hallucinations, and answer_relevancy, which measures the answers to question relevance.
Additionally, RAGAs leverage LLMs under the hood for reference-free evaluation to save costs or combine RAGAS with LangSmith.
TruLens Eval RAG Triad of Metrics
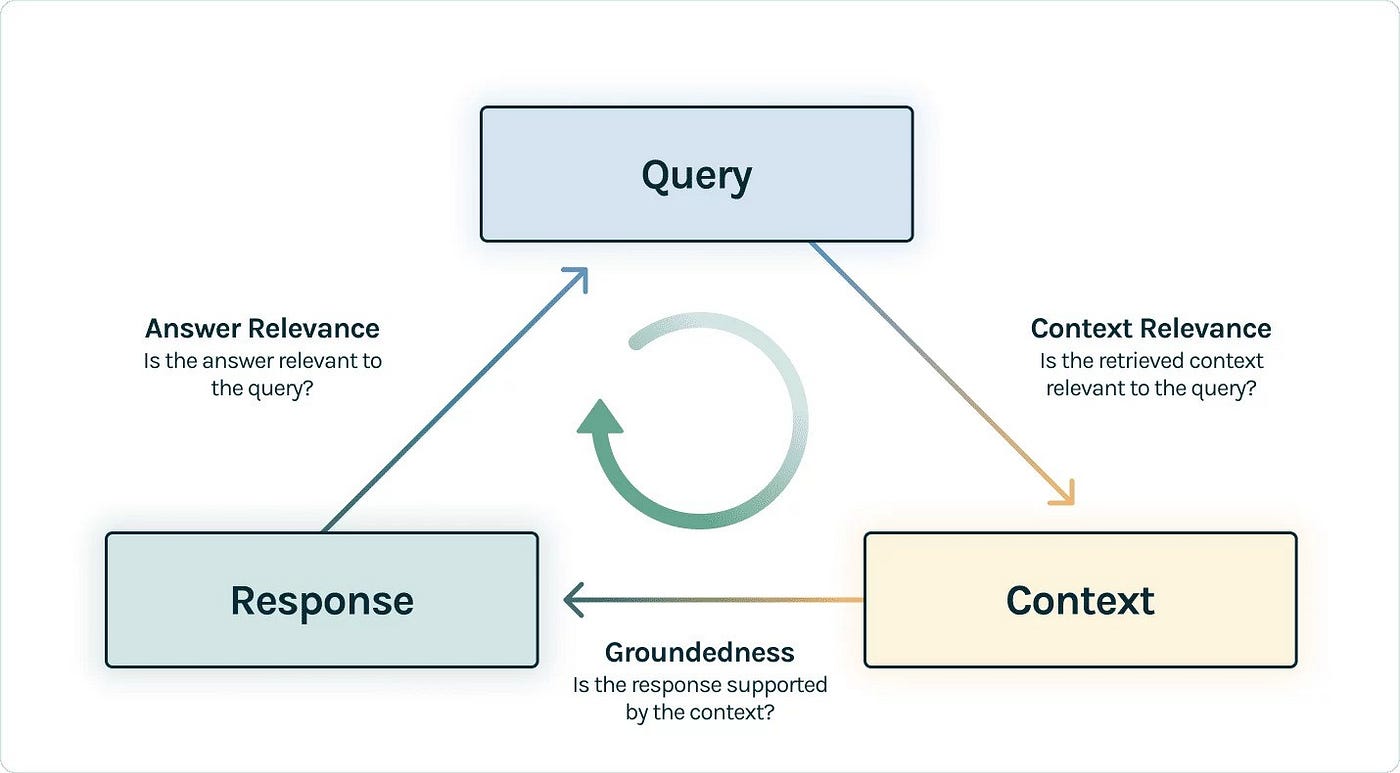
The RAG Triad comprises three evaluative tests: context relevance, groundedness, and answer relevance. Context relevance involves verifying the pertinence of retrieved content to the input query, which is crucial to preventing irrelevant context from leading to inaccurate answers; this is assessed using a Language Model to generate a context relevance score. Groundedness checks the factual support for each statement within a response, addressing the issue of LLMs potentially generating embellished or factually incorrect statements. Finally, answer relevance ensures the response not only addresses the user's question but does so in a directly applicable manner. By meeting these standards, an RAG application can be considered accurate and free from hallucinations within the scope of its knowledge base, providing a nuanced statement about its correctness.
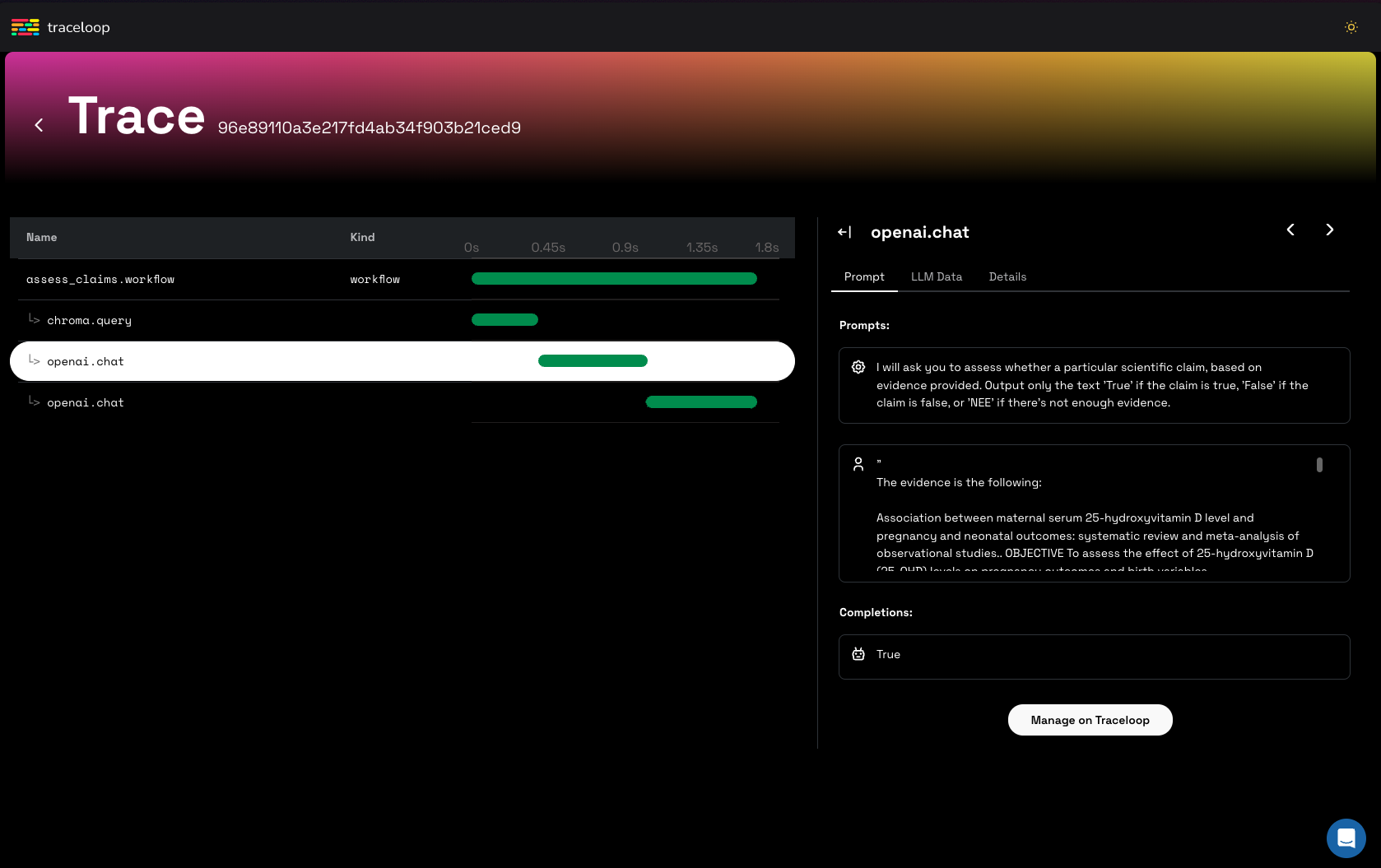
OpenLLMetry provides observability for RAG systems. It allows tracing calls to VectorDBs, Public and Private LLMs, and other AI services. It gives visibility to query and index calls and LLM prompts and completions.
Traceloop helps you to debug and test changes to your models and prompts for every request. It can run on a cloud-hosted version.
Futures on RAG platforms
Timeline of existing RAG studies. Timetables are determined primarily based on release dates.
In the research timeline, the bulk of Retrieval-Augmented Generation (RAG) studies surfaced post-2020, with a notable surge following ChatGPT's release in December 2022, marking a pivotal moment. Initially, RAG research focused on reinforcement strategies during pre-training and supervised fine-tuning stages. However, in 2023, with the advent of large, costly-to-train models, the emphasis has shifted towards reinforcement during the inference stage, aiming to embed external knowledge cost-effectively through RAG modules.
SAP releases for Vector Engine and Generative AI Hub go in the direction to help BTP become a platform of choice for our RAG pipelines, where we will need to provide solutions that are driving the attention of Vector DBs ecosystem;
Context Length: The effectiveness of RAG is constrained by the context window size of Large Language Models (LLMs). Late 2023 research aims to balance the trade-off between too short and too long windows, with efforts focusing on virtually unlimited context sizes as a significant question.
Robustness: noisy or contradictory information during retrieval can negatively impact RAG's output quality. Enhancing RAG's resistance to such adversarial inputs is gaining momentum as a key performance metric.
Hybrid Approaches (RAG+FT): Integrating RAG with fine-tuning, whether sequential, alternating, or joint training, is an emerging strategy. Exploring the optimal integration and harnessing both parameterized and non-parameterized advantages are ripe for research.
CONCLUSION
The journey of RAG on SAP has just started, and the future of Retrieval-Augmented Generation (RAG) looks promising yet challenging. As RAG continues to evolve, driven by significant strides post-2020 and catalyzed by the advent of models like ChatGPT, it faces hurdles such as context length limitations, robustness against misinformation, and the quest for optimal hybrid approaches. The emergence of diverse tools and frameworks provides a more transparent, effective way to optimize RAG systems. With SAP's advancements toward RAG-friendly platforms, our focus in the AI engineering space is on overcoming these challenges and ensuring accurate, reliable, and efficient augmented generation systems.