
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- Quick'n'dirty solution for parsing XLSX files on t...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Astashonok
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-24-2020
11:26 PM
Hi, SAPpers,
the method I want to describe in this blog is not new and is probably known to ABAP gurus, however many of the beginners often ask questions regarding this topic, hence this blog has appeared. The described approach is not a comprehensive Excel parsing solution but rather a life ring when the customer urges for quick solution and the deadline passed "yesterday".
Any of you I definitely faced such common task as Excel files processing, this task often is raised in different SAP environments like OData services, Webdynpro apps, FPM apps and so on. Very often everything you have is a XLSX file and/or an XSTRING data made from it, knowing nothing about the structure, and you need quickly parse the table contents for processing in your app. How would you proceed?
SAP provides many Excel-related programming tools, they are listed on this handy page:
https://wiki.scn.sap.com/wiki/display/ABAP/Excel+with+SAP+-+An+overview
why not to use them? There are couple of asterisks here:
One would say: why the heck we need another tool if we already have ABAP2XLSX?
ABAP2XLSX is certainly a great and powerful tool and I used it on my projects too but often there are difficulties with its installation. Some customers dogmatically refuse to install custom packages to system, some are bothered about license issues and some guys are open to third-parties but approval of installing the third-party into the ABAP system will take months in the big multinational dinosaurs like the one I'm working now.
And when the Excel parsing is required utterly, just now, because all the deadlines are over and it was expected "yesterday", in such crucial situations I propose to clients the solution I will describe here, it cannot be really called a solution because it has many flaws, but it can do the basic job and transform Excel file into internal table in ABAP. I invite you to treat it like a proof-of-concept rather than solution, however it is fully functional and can be adapted to your needs easily (or not so easily).
When I was analyzing possible solutions to the problem I considered many candidates but there were the reasons why nothing fitted my needs. I reviewed even the ancient time pieces (2009 was lon before the COVID) and some of them were quite cool, like this one from the long respected ABAP warrior naimesh.patel Yes, the XML generation offered by Naimesh worked fast and has simplicity but the format itself is inferior by design. Spreadsheet ML despite the name is not a full-featured spreadsheet but just a subset of XML capable of representing tabular data with the numerous limitations.
There is also a marvelous piece of work done by madhu.omer, and honestly I was very impressed by the work done, but for my task it seemed over-complicated and touching only XLSX generation part and I urgently sought a way to parse. Also, iXML Library she used in her tool has some performance drawbacks and is not adapted for big data.
Another good attempt to achieve the same result was done by rrajgor Unlike Madhu with her Simple Transformations he used direct construction of XML template through ABAP string templates. Unfortunately this approach is not very flexible and again it is just a Spreadsheet ML, not a full-blown XLSX spreadsheet, so his work is only a modern rethinking of Naimesh old converter.
What I found really interesting is an import/export solution by trevor.zhang written in modern classes and a modern concise syntax. Modern problems require modern solutions, they say, hehe.
I wasn't aware of cl_ehfnd_xlsx class that was introduced with ABAP AS 752 and it is still very little info about it in the Web, so it seems more like internal S4HANA stuff not intended for customers. Anyway, it is an option but yeah, it requires 752 release and our system was still on 750 so I was out of the luck again :((
Let me briefly outline the nuts and bolts of .XLSX parsing which one must know before starting the implementation:
For parsing task we are interested only in the first two: sheet1.xml and sharedStrings.xml, it is an absolute minimum required to successfully recreate the table in ABAP.
The sheet1.xml file describes data structure across the sheet, the core part of it is <sheetData>
The shared data is nothing more than just an array of Excel sheet values stored in string format:
Let me share the steps I used for grabbing the table from XLSX file and turning it into ABAP itab:
Enough words and let's jump to the code.
Main parsing class xlsx_reader:
Transformation zheet for sheet files
Transformation zxlsx for shared strings
Sample calling program:
The idea of the program is that user has two options for parsing: either to parse into generic string table or to receive a fully-typed internal table in his hands. Type can be specified explicitly on the selection screen (DDIC structure input box) or the program can derive type from the first line of Excel table provided it is filled with data element names (Use 1st line as structure checkbox).
Sample input for 1st line-typed table MARC (subset of columns)
and the output to fully-typed itab
Sample input for explicitly specified DDIC structure KALC
pay attention that in spite of the "number stored as string" values we received fully-typed table in ABAP, and even FLTP values are stored correctly
And finally the most simple case with conversion into string table
A couple of notes about limitations of the current sample implementation:
Come down to, I didn't set a task to make a comprehensive tool for all situations, but rather show to community how it can be done in a simple and standard way, you are free to adapt and tailor the class to your needs.
And now about the advantages my solution posses over other approaches:
Feel free to comment and share your considerations, dear community!
the method I want to describe in this blog is not new and is probably known to ABAP gurus, however many of the beginners often ask questions regarding this topic, hence this blog has appeared. The described approach is not a comprehensive Excel parsing solution but rather a life ring when the customer urges for quick solution and the deadline passed "yesterday".
Problem definition
Any of you I definitely faced such common task as Excel files processing, this task often is raised in different SAP environments like OData services, Webdynpro apps, FPM apps and so on. Very often everything you have is a XLSX file and/or an XSTRING data made from it, knowing nothing about the structure, and you need quickly parse the table contents for processing in your app. How would you proceed?
SAP provides many Excel-related programming tools, they are listed on this handy page:
https://wiki.scn.sap.com/wiki/display/ABAP/Excel+with+SAP+-+An+overview
why not to use them? There are couple of asterisks here:
- Almost all standard Excel reading tools are based on OLE and do not allow reading in batch or non-dialog mode
- All the rest are third-party and highly specific like PI libraries
One would say: why the heck we need another tool if we already have ABAP2XLSX?
ABAP2XLSX is certainly a great and powerful tool and I used it on my projects too but often there are difficulties with its installation. Some customers dogmatically refuse to install custom packages to system, some are bothered about license issues and some guys are open to third-parties but approval of installing the third-party into the ABAP system will take months in the big multinational dinosaurs like the one I'm working now.
And when the Excel parsing is required utterly, just now, because all the deadlines are over and it was expected "yesterday", in such crucial situations I propose to clients the solution I will describe here, it cannot be really called a solution because it has many flaws, but it can do the basic job and transform Excel file into internal table in ABAP. I invite you to treat it like a proof-of-concept rather than solution, however it is fully functional and can be adapted to your needs easily (or not so easily).
History of the approaches
When I was analyzing possible solutions to the problem I considered many candidates but there were the reasons why nothing fitted my needs. I reviewed even the ancient time pieces (2009 was lon before the COVID) and some of them were quite cool, like this one from the long respected ABAP warrior naimesh.patel Yes, the XML generation offered by Naimesh worked fast and has simplicity but the format itself is inferior by design. Spreadsheet ML despite the name is not a full-featured spreadsheet but just a subset of XML capable of representing tabular data with the numerous limitations.
There is also a marvelous piece of work done by madhu.omer, and honestly I was very impressed by the work done, but for my task it seemed over-complicated and touching only XLSX generation part and I urgently sought a way to parse. Also, iXML Library she used in her tool has some performance drawbacks and is not adapted for big data.
Another good attempt to achieve the same result was done by rrajgor Unlike Madhu with her Simple Transformations he used direct construction of XML template through ABAP string templates. Unfortunately this approach is not very flexible and again it is just a Spreadsheet ML, not a full-blown XLSX spreadsheet, so his work is only a modern rethinking of Naimesh old converter.
What I found really interesting is an import/export solution by trevor.zhang written in modern classes and a modern concise syntax. Modern problems require modern solutions, they say, hehe.
I wasn't aware of cl_ehfnd_xlsx class that was introduced with ABAP AS 752 and it is still very little info about it in the Web, so it seems more like internal S4HANA stuff not intended for customers. Anyway, it is an option but yeah, it requires 752 release and our system was still on 750 so I was out of the luck again :((
Integral parts of the parser
Let me briefly outline the nuts and bolts of .XLSX parsing which one must know before starting the implementation:
- XLSX format in fact is not a single file, but a set of files which define how the Excel workbook will look like. This is a fundamental difference from old .XLS which was a binary non-extractable container and from primitive SpreadsheetML which defines worksheet in a single XML.
- The main decommissioning parts of XLSX file are
- sheet files (sheet1.xml, sheet2.xml, ...), they contain markup for data placement on a sheet
- shared strings file (sharedStrings.xml), it contains a deduplicated array of values
- styles definition (styles.xml) which defines how the cells of worksheet will look like
- workbook file (workbook.xml) it set up the structure of workbook and worksheets in it
- many others...
For parsing task we are interested only in the first two: sheet1.xml and sharedStrings.xml, it is an absolute minimum required to successfully recreate the table in ABAP.
The sheet1.xml file describes data structure across the sheet, the core part of it is <sheetData>
<sheetData>
<row r="1" x14ac:dyDescent="0.25" spans="1:107">
<c r="A1" t="s">
<v>21</v>
</c>
<c r="B1" t="s">
<v>22</v>
</c>
<c r="C1" t="s">
<v>23</v>
</c>
</row>
</sheetData>The shared data is nothing more than just an array of Excel sheet values stored in string format:
<sst count="309" uniqueCount="83">
<si>
<t>MANDT</t>
</si>
<si>
<t>CARRID</t>
</si>
<si>
<t>CONNID</t>
</si>
<si>
<t>COUNTRYFR</t>
</si>
</sst>Let me share the steps I used for grabbing the table from XLSX file and turning it into ABAP itab:
- Extract the sheet structure (sheet1.xml) into XSTRING XML
- Extract the array of sheet values (sharedStrings.xml)
- Transform both XMLs into internal tables through ST transformations
- Construct the result internal table by mapping indices in sheet file against array of values
Enough words and let's jump to the code.
Main parsing class xlsx_reader:
CLASS xlsx_reader DEFINITION.
PUBLIC SECTION.
METHODS: read IMPORTING file TYPE string
first TYPE abap_bool
ddic TYPE string
EXPORTING tab TYPE REF TO data,
extract_xml IMPORTING iv_xml_index TYPE i
xstring TYPE xstring
RETURNING VALUE(rv_xml_data) TYPE xstring.
ENDCLASS.
CLASS xlsx_reader IMPLEMENTATION.
METHOD read.
TYPES: BEGIN OF ty_row,
value TYPE string,
index TYPE abap_bool,
END OF ty_row,
BEGIN OF ty_worksheet,
row_id TYPE i,
row TYPE TABLE OF ty_row WITH EMPTY KEY,
END OF ty_worksheet,
BEGIN OF ty_si,
t TYPE string,
END OF ty_si.
" Excel varaibles
DATA: data TYPE TABLE OF ty_si,
sheet TYPE TABLE OF ty_worksheet.
" RTTS variables
DATA: lo_struct TYPE REF TO cl_abap_structdescr,
table TYPE abap_component_tab.
FIELD-SYMBOLS: <table> TYPE STANDARD TABLE.
TRY. " loading XLSX zip from file
DATA(xstring_xlsx) = cl_openxml_helper=>load_local_file( file ).
CATCH cx_openxml_not_found.
ENDTRY.
"Read the sheet XML
DATA(xml_sheet) = extract_xml( EXPORTING xstring = xstring_xlsx iv_xml_index = 2 ).
"Read the shared data XML
DATA(xml_data) = extract_xml( EXPORTING xstring = xstring_xlsx iv_xml_index = 3 ).
TRY.
" transforming sheet structure into ABAP
CALL TRANSFORMATION zsheet
SOURCE XML xml_sheet
RESULT root = sheet.
" transforming shared data into ABAP
CALL TRANSFORMATION zxlsx
SOURCE XML xml_data
RESULT root = data.
CATCH cx_xslt_exception.
CATCH cx_st_match_element.
CATCH cx_st_ref_access.
ENDTRY.
DATA(header_line) = VALUE #( sheet[ 1 ]-row OPTIONAL ).
IF first IS NOT INITIAL AND header_line IS NOT INITIAL. "building itab from first line
table = VALUE #( BASE table FOR ls_key IN header_line
( name = data[ ls_key-value + 1 ]-t
type = CAST #( cl_abap_datadescr=>describe_by_name( VALUE #( data[ ls_key-value + 1 ]-t OPTIONAL ) ) )
)
).
DELETE sheet INDEX 1.
ELSE. "building itab of strings
DELETE header_line WHERE value IS INITIAL.
DO lines( header_line ) TIMES.
APPEND VALUE #( name = 'field' && sy-index type = CAST #( cl_abap_typedescr=>describe_by_name( 'STRING' ) ) ) TO table.
ENDDO.
ENDIF.
" creating structure from DDIC structure
IF ddic IS NOT INITIAL.
lo_struct ?= cl_abap_structdescr=>describe_by_name( ddic ).
ELSEIF table IS NOT INITIAL.
" create structure from previously constructed type handle
TRY.
lo_struct = cl_abap_structdescr=>create( table ).
CATCH cx_sy_struct_creation .
ENDTRY.
ENDIF.
" creating table from structure
CHECK lo_struct IS BOUND.
DATA(dyntable_type) = cl_abap_tabledescr=>create( p_line_type = lo_struct ).
CREATE DATA tab TYPE HANDLE dyntable_type.
ASSIGN tab->* TO <table>.
* mapping structure and data
LOOP AT sheet ASSIGNING FIELD-SYMBOL(<fs_row>).
APPEND INITIAL LINE TO <table> ASSIGNING FIELD-SYMBOL(<line>).
DELETE <fs_row>-row WHERE value IS INITIAL.
LOOP AT <fs_row>-row ASSIGNING FIELD-SYMBOL(<fs_cell>).
ASSIGN COMPONENT sy-tabix OF STRUCTURE <line> TO FIELD-SYMBOL(<fs_field>).
CHECK sy-subrc = 0.
<fs_field> = COND #( WHEN <fs_cell>-index = abap_false THEN <fs_cell>-value ELSE VALUE #( data[ <fs_cell>-value + 1 ]-t OPTIONAL ) ).
ENDLOOP.
ENDLOOP.
ENDMETHOD.
METHOD extract_xml.
TRY.
DATA(lo_package) = cl_xlsx_document=>load_document( iv_data = xstring ).
DATA(lo_parts) = lo_package->get_parts( ).
CHECK lo_parts IS BOUND AND lo_package IS BOUND.
DATA(lv_uri) = lo_parts->get_part( 2 )->get_parts( )->get_part( iv_xml_index )->get_uri( )->get_uri( ).
DATA(lo_xml_part) = lo_package->get_part_by_uri( cl_openxml_parturi=>create_from_partname( lv_uri ) ).
rv_xml_data = lo_xml_part->get_data( ).
CATCH cx_openxml_format cx_openxml_not_found.
ENDTRY.
ENDMETHOD.
ENDCLASS.Transformation zheet for sheet files
<?sap.transform simple?>
<tt:transform xmlns:tt="http://www.sap.com/transformation-templates" template="main">
<tt:root name="root"/>
<tt:template name="main">
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:x14ac=
"http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac" xmlns:xr="http://schemas.microsoft.com/office/spreadsheetml/2014/revision" xmlns:xr2="http://schemas.microsoft.com/office/spreadsheetml/2015/revision2" xmlns:xr3=
"http://schemas.microsoft.com/office/spreadsheetml/2016/revision3">
<tt:skip count="4"/>
<sheetData>
<tt:loop name="row" ref="root">
<row>
<tt:attribute name="r" value-ref="row_id"/>
<tt:loop name="cells" ref="$row.ROW">
<c>
<tt:cond><tt:attribute name="t" value-ref="index"/><tt:assign to-ref="index" val="C('X')"/></tt:cond>
<tt:cond>
<v>
<tt:value ref="value"/>
</v>
</tt:cond>
</c>
</tt:loop>
</row>
</tt:loop>
</sheetData>
<tt:skip/>
</worksheet>
</tt:template>
</tt:transform>Transformation zxlsx for shared strings
<?sap.transform simple?>
<tt:transform xmlns:tt="http://www.sap.com/transformation-templates" template="main">
<tt:root name="ROOT"/>
<tt:template name="main">
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main">
<tt:loop name="line" ref=".ROOT">
<si>
<t>
<tt:value ref="t"/>
</t>
</si>
</tt:loop>
</sst>
</tt:template>
</tt:transform>Sample calling program:
START-OF-SELECTION.
PARAMETERS: p_file TYPE string LOWER CASE DEFAULT `C:\table.xlsx`.
SELECTION-SCREEN BEGIN OF BLOCK out WITH FRAME TITLE text-s01.
SELECTION-SCREEN BEGIN OF LINE.
SELECTION-SCREEN COMMENT 1(25) text-002.
PARAMETERS: p_hdr TYPE xfeld MODIF ID hdr USER-COMMAND hdr.
SELECTION-SCREEN COMMENT 30(25) text-001.
PARAMETERS: p_ddic TYPE string MODIF ID dic.
SELECTION-SCREEN END OF LINE.
SELECTION-SCREEN END OF BLOCK out.
AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_file.
p_file = cl_openxml_helper=>browse_local_file_open( iv_title = 'Select XLSX File' iv_filename = '' iv_extpattern = 'All files(*.*)|*.*' ).
AT SELECTION-SCREEN OUTPUT.
IF p_hdr = abap_true.
DATA(imp) = 1.
CLEAR: p_ddic.
ELSE.
imp = 0.
ENDIF.
LOOP AT SCREEN.
CASE screen-group1.
WHEN 'DIC'.
SCREEN-input = COND #( WHEN imp = 1 THEN 0 ELSE 1 ).
ENDCASE.
MODIFY SCREEN.
ENDLOOP.
AT SELECTION-SCREEN.
FIELD-SYMBOLS: <fs_out> TYPE ANY.
IF sy-ucomm = 'ONLI'.
DATA(reader) = NEW xlsx_reader( ).
reader->read( EXPORTING file = p_file first = p_hdr ddic = p_ddic IMPORTING tab = DATA(tab) ).
ASSIGN tab->* TO FIELD-SYMBOL(<table>).
ENDIF.Samples of usage
The idea of the program is that user has two options for parsing: either to parse into generic string table or to receive a fully-typed internal table in his hands. Type can be specified explicitly on the selection screen (DDIC structure input box) or the program can derive type from the first line of Excel table provided it is filled with data element names (Use 1st line as structure checkbox).

Sample input for 1st line-typed table MARC (subset of columns)

and the output to fully-typed itab

Sample input for explicitly specified DDIC structure KALC
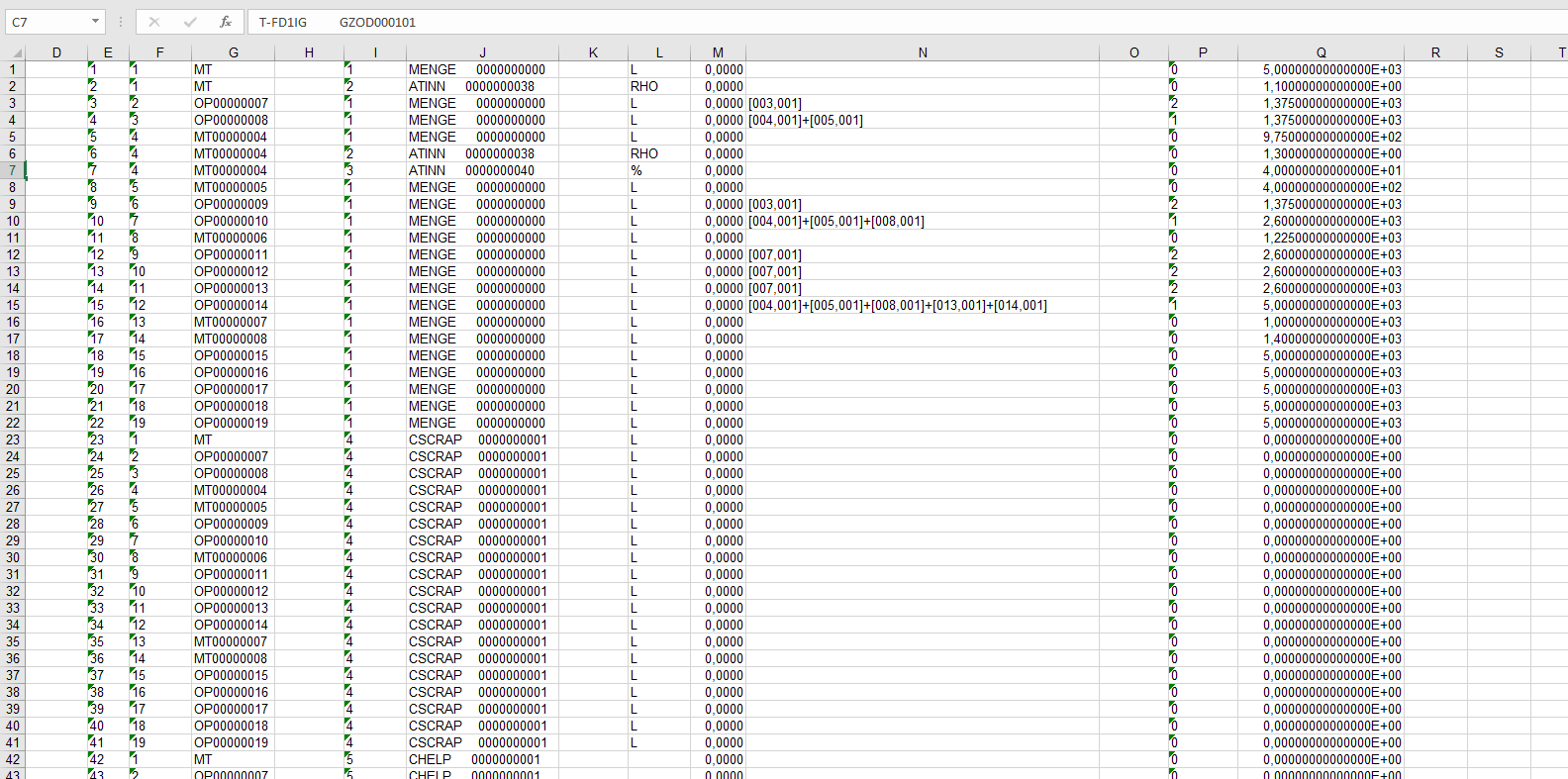
pay attention that in spite of the "number stored as string" values we received fully-typed table in ABAP, and even FLTP values are stored correctly

And finally the most simple case with conversion into string table

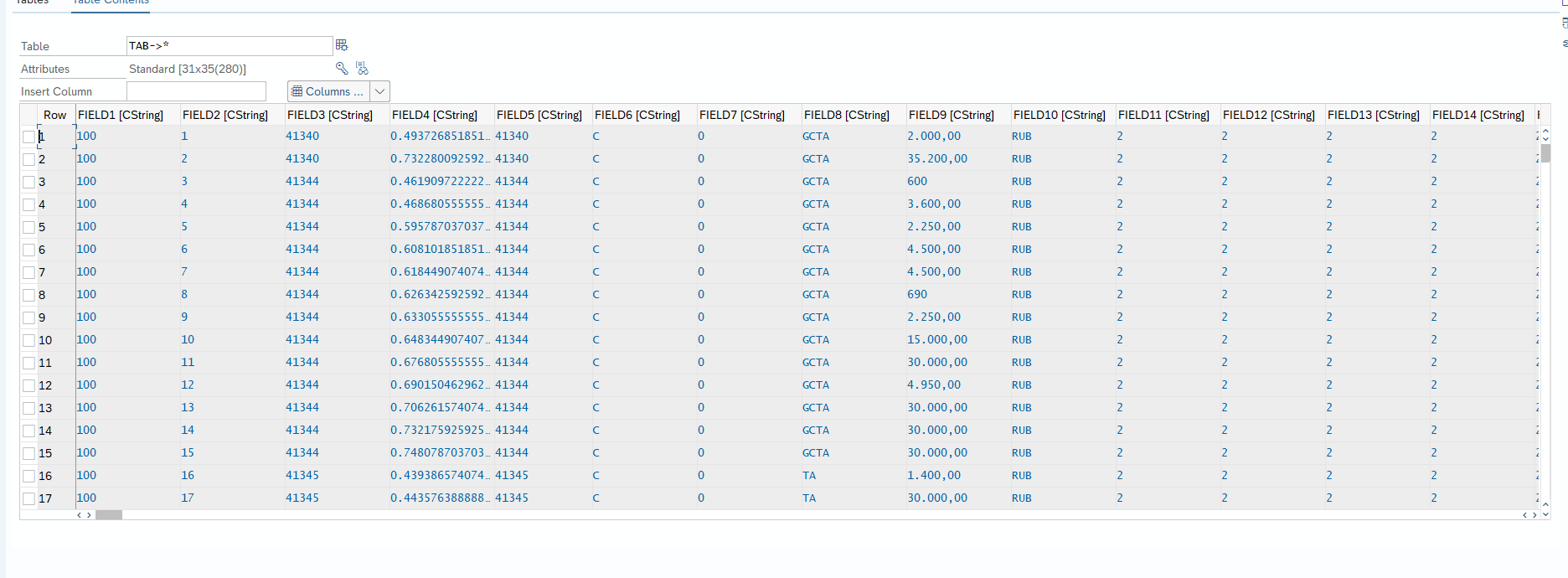
Conclusion
A couple of notes about limitations of the current sample implementation:
- It parses only first sheet in this variant (easily curable by adding couple lines of code)
- It does not respect blank columns in an Excel sheet
- Dates are not recognized properly 'cause in sharedStrings.xml they are stored in Epoch format
- Decimal number values may throw a dump while parsing if user locale settings differs from settings of those who sent the file
Come down to, I didn't set a task to make a comprehensive tool for all situations, but rather show to community how it can be done in a simple and standard way, you are free to adapt and tailor the class to your needs.
And now about the advantages my solution posses over other approaches:
- Pretty and concise, the class consists of only 100 lines of code
- Absolutely standard, based on CL_XLSX_DOCUMENT class which is available for almost all releases, except the most ancient ones, particularly ≥7.02
- Built on simple transformations in contrast to XSLT ones like in unified approach,for example. ST are significantly faster on big data, they are more intuitive for adaptation to customer needs and (the sweetest!) they are two-sided, and can be used both for serialization and deserialization.
- Performance. I tested my parser on big amounts of data and it works good enough (10 sec on 100Mb file), whilst, e.g. ABAP2XLSX parsing is based on CL_IXML class (iXML library) and does not perform well on big datasets.
Feel free to comment and share your considerations, dear community!
- SAP Managed Tags:
- ABAP Development,
- ABAP Extensibility
12 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
9 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
5 -
ABAP in Eclipse
2 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
9 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
3 -
DMS
1 -
dynamic logpoints
1 -
Dynpro
1 -
Dynpro Width
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
General
1 -
Getting Started
1 -
IBM watsonx
2 -
Integration & Connectivity
9 -
Introduction
1 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
14 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
2 -
SAP SEGW
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
SM30
1 -
Table Maintenance Generator
1 -
text editor
1 -
Tools
18 -
User Experience
6 -
Width
1
Top kudoed authors
| User | Count |
|---|---|
| 4 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |