
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Going beyond masking: how to anonymize large data ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member20
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-26-2018
7:36 AM
Why are masking and pseudonymization not the best tools for anonymizing large data sets?
In my recent blog, Anonymization: Analyze sensitive data without compromising privacy, I gave you an outlook on SAP HANA’s vision for real-time anonymized data access and the new opportunities this opens up for use cases previously prevented by data protection and privacy regulations.
In this blog I will explain which advanced anonymization methods and criteria exist to go beyond masking and pseudonyms: specifically k-anonymity and differential privacy.
When is data truly anonymized? You can probably remember several cases where organizations such as public transport organizations or telecommunication providers published insufficiently “anonymized” data sets resulting in very damaging highly visible news headlines.
This is not to do any finger-pointing, because you know what? Anonymization is really hard! For many real-life use cases it isn’t enough to just substitute names with pseudonyms, or mask some of the values. With a little additional background knowledge it is often possible to identify the individuals you thought had been anonymized.
Organizations are increasingly looking for ways to reconcile modern data-centric business use cases with stringent privacy regulations like the General Data Protection Regulation (GDPR). So how can organizations make sure they do the right thing, and show that they are taking their digital responsibility seriously?
SAP wants to support customers on their digital transformation journey and let them turn the privacy challenge into an opportunity. Our vision is to provide real-time anonymized access to data and by doing so make data available for uses cases previously prevented by data protection and privacy regulations.

Read more about how to turn the data privacy challenge into business value in this blog by Daniel Schneiss.
The SAP HANA team has been putting a lot of thought and research into how to best help customers to safeguard data privacy, while unlocking the full potential of their data in modern analytic use cases. With SAP HANA 2.0 SPS 03, we have released a customizable functionality that allows organizations to anonymize live data – by providing an anonymized view of their data in SAP HANA. For more information on the new security features in this release, check out this blog.
Hospitals collect large amounts of patient data that contains highly sensitive information. The primary purpose of this data is to allow doctors to take care of their patients. Only a very small group of people has access to the data about an individual patient like Martin in the example below. Usually only the treating doctor, nurses, and the patient Martin himself. Data access is strictly regulated using standard security mechanisms such as access control and authorizations.

However, patient data is an extremely valuable source of information especially where it can give insights into what causes illnesses or what treatment is effective. A typical medical researcher might ask something along the lines of whether there is a correlation between a patient’s weight and cancer. Patient confidentiality and DPP regulations often prevent such an analysis because there is a risk of personal data being revealed.
In contrast to the treating doctors who need to know which specific patient has which illness, medical researchers are not interested in the illnesses of individuals like Martin. Their goal rather is to gain statistical medical insights from the patient data to find patterns.
So how can large data sets be evaluated for research purposes without exposing sensitive information about individuals?
First things first: All information that directly identifies an individual, for example names, must be eliminated. This can be achieved by removing the relevant columns, by masking the values in these columns (for example by applying a mask XXXXXXX to names), or by using pseudonyms (for example by using the hash value of names like in the example table below).

But is this enough? What if the researcher knows that his colleague Martin might be in the data set, and also knows that Martin is overweight? Looking at the table above again, with this additional knowledge about Martin’s weight it is still possible to identify Martin in the data set, even though his actual name was removed.
The next intuitive step would be to eliminate more information from the data set that could help identify individuals, so called “quasi identifiers”. If enough information is removed, individuals can no longer be identified. But wait: what about the researcher who wants to find out about correlations between weight and cancer? Looking at the purged patient data below, the weight column has been removed…so the researcher won’t be able to gain any insights from the data set any longer.

How can the right balance between utility (answering the researcher’s question) and privacy (protecting the sensitive information of the individual) be achieved?
Anonymization provides a structured approach for doing just that. Before I explain more about how this works, remember that whenever you deal with person-related data, you always need to closely align with the data protection officer in your organization to discuss which privacy regulations apply (think GDPR) and which security mechanisms and organization measures you need to apply.
One popular approach is to not eliminate data that could lead back to individuals, but generalize it in a structured way. The goal is to divide the data sets into groups that still allow valid statistical insights into the data that is to be analyzed (the Weight and Illness columns in our example), but make it impossible to get sensitive information about individuals.
The table below shows an example where the quasi identifiers Birth Year, Location and Weight have been generalized to build 2 groups with 2 members each. In a real-life use case, the groups would of course be larger, a good rule of thumb is 10 as is common in questionnaires. The variable k (2 in the example) in k-anonymity indicates the minimum group size.

Even though we know that Martin is overweight and therefore probably is one of the members of the first group in the example, it is no longer possible to identify his specific illness. But can our researcher still answer his question? Yes – even though the precise data is no longer available, a correlation between weight and cancer can still be deduced from the data set.
While k-anonymity is an anonymization method where privacy can be fine-tuned quite intuitively, differential privacy is an anonymization criterion that can be proved statistically and is achieved by adding random noise to sensitive (numerical) values.
Let’s have a look at a slightly different example to illustrate this: salary data. Like in the patient data example above, there are people who are authorized to see the real salaries of individuals, for example the responsible HR department. For analyzing average salaries or learning more about the general geographical distribution of salaries, information about individuals is not required. A typical question could be to find out the average salary of people living in Hamburg.
For such use cases, noise can be added to the individual salaries, thus making them unrecognizable from their true values. When you look at the first record in the table below for example, the “noise x1” has been added to the original salary value of 65k, thus altering the salary value to a new fictive value of 12k. The second record has been altered by a different “noise x2”, and so on.

Surprisingly, a statistical analysis of such a data set can still provide very good insights! This is because the actual noise values x1, x2, …, xi are generated in such a statistically clever way that they almost cancel themselves out if large amounts of data are analyzed:
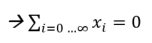
Rule of thumb here: the more data you have in your data set, the more precise an analysis on the anonymized data will be.
Stay tuned for the next part of our blog series, which will explain more about the mathematical concepts underlying differential privacy and k-anonymity in more detail.
Anonymization is just one of the tools in the security toolbox aimed primarily at doing analytics on whole sets of data that were previously denied. Managing secure data access and configuring systems securely continue to be critical operational tasks. Anonymization therefore complements other security mechanisms such as masking, authorization, and encryption.

SAP HANA has security built into its core, with a comprehensive framework and tooling for authentication and single sign-on, authorization and role management, user and identity management, audit logging, secure configuration and encryption. Find out more about SAP HANA security at http://www.sap.com/hanasecurity
In my recent blog, Anonymization: Analyze sensitive data without compromising privacy, I gave you an outlook on SAP HANA’s vision for real-time anonymized data access and the new opportunities this opens up for use cases previously prevented by data protection and privacy regulations.
In this blog I will explain which advanced anonymization methods and criteria exist to go beyond masking and pseudonyms: specifically k-anonymity and differential privacy.
When is data truly anonymized? You can probably remember several cases where organizations such as public transport organizations or telecommunication providers published insufficiently “anonymized” data sets resulting in very damaging highly visible news headlines.
This is not to do any finger-pointing, because you know what? Anonymization is really hard! For many real-life use cases it isn’t enough to just substitute names with pseudonyms, or mask some of the values. With a little additional background knowledge it is often possible to identify the individuals you thought had been anonymized.
Organizations are increasingly looking for ways to reconcile modern data-centric business use cases with stringent privacy regulations like the General Data Protection Regulation (GDPR). So how can organizations make sure they do the right thing, and show that they are taking their digital responsibility seriously?
SAP wants to support customers on their digital transformation journey and let them turn the privacy challenge into an opportunity. Our vision is to provide real-time anonymized access to data and by doing so make data available for uses cases previously prevented by data protection and privacy regulations.
Read more about how to turn the data privacy challenge into business value in this blog by Daniel Schneiss.
Data Anonymization – available now
The SAP HANA team has been putting a lot of thought and research into how to best help customers to safeguard data privacy, while unlocking the full potential of their data in modern analytic use cases. With SAP HANA 2.0 SPS 03, we have released a customizable functionality that allows organizations to anonymize live data – by providing an anonymized view of their data in SAP HANA. For more information on the new security features in this release, check out this blog.
What is the problem? A real-life example from healthcare
Hospitals collect large amounts of patient data that contains highly sensitive information. The primary purpose of this data is to allow doctors to take care of their patients. Only a very small group of people has access to the data about an individual patient like Martin in the example below. Usually only the treating doctor, nurses, and the patient Martin himself. Data access is strictly regulated using standard security mechanisms such as access control and authorizations.
However, patient data is an extremely valuable source of information especially where it can give insights into what causes illnesses or what treatment is effective. A typical medical researcher might ask something along the lines of whether there is a correlation between a patient’s weight and cancer. Patient confidentiality and DPP regulations often prevent such an analysis because there is a risk of personal data being revealed.
In contrast to the treating doctors who need to know which specific patient has which illness, medical researchers are not interested in the illnesses of individuals like Martin. Their goal rather is to gain statistical medical insights from the patient data to find patterns.
So how can large data sets be evaluated for research purposes without exposing sensitive information about individuals?
First things first: All information that directly identifies an individual, for example names, must be eliminated. This can be achieved by removing the relevant columns, by masking the values in these columns (for example by applying a mask XXXXXXX to names), or by using pseudonyms (for example by using the hash value of names like in the example table below).
But is this enough? What if the researcher knows that his colleague Martin might be in the data set, and also knows that Martin is overweight? Looking at the table above again, with this additional knowledge about Martin’s weight it is still possible to identify Martin in the data set, even though his actual name was removed.
The next intuitive step would be to eliminate more information from the data set that could help identify individuals, so called “quasi identifiers”. If enough information is removed, individuals can no longer be identified. But wait: what about the researcher who wants to find out about correlations between weight and cancer? Looking at the purged patient data below, the weight column has been removed…so the researcher won’t be able to gain any insights from the data set any longer.
How can the right balance between utility (answering the researcher’s question) and privacy (protecting the sensitive information of the individual) be achieved?
Anonymization provides a structured approach for doing just that. Before I explain more about how this works, remember that whenever you deal with person-related data, you always need to closely align with the data protection officer in your organization to discuss which privacy regulations apply (think GDPR) and which security mechanisms and organization measures you need to apply.
k-anonymity: Hiding individuals in a crowd
One popular approach is to not eliminate data that could lead back to individuals, but generalize it in a structured way. The goal is to divide the data sets into groups that still allow valid statistical insights into the data that is to be analyzed (the Weight and Illness columns in our example), but make it impossible to get sensitive information about individuals.
The table below shows an example where the quasi identifiers Birth Year, Location and Weight have been generalized to build 2 groups with 2 members each. In a real-life use case, the groups would of course be larger, a good rule of thumb is 10 as is common in questionnaires. The variable k (2 in the example) in k-anonymity indicates the minimum group size.
Even though we know that Martin is overweight and therefore probably is one of the members of the first group in the example, it is no longer possible to identify his specific illness. But can our researcher still answer his question? Yes – even though the precise data is no longer available, a correlation between weight and cancer can still be deduced from the data set.
Differential privacy: Adding noise to sensitive data
While k-anonymity is an anonymization method where privacy can be fine-tuned quite intuitively, differential privacy is an anonymization criterion that can be proved statistically and is achieved by adding random noise to sensitive (numerical) values.
Let’s have a look at a slightly different example to illustrate this: salary data. Like in the patient data example above, there are people who are authorized to see the real salaries of individuals, for example the responsible HR department. For analyzing average salaries or learning more about the general geographical distribution of salaries, information about individuals is not required. A typical question could be to find out the average salary of people living in Hamburg.
For such use cases, noise can be added to the individual salaries, thus making them unrecognizable from their true values. When you look at the first record in the table below for example, the “noise x1” has been added to the original salary value of 65k, thus altering the salary value to a new fictive value of 12k. The second record has been altered by a different “noise x2”, and so on.
Surprisingly, a statistical analysis of such a data set can still provide very good insights! This is because the actual noise values x1, x2, …, xi are generated in such a statistically clever way that they almost cancel themselves out if large amounts of data are analyzed:
Rule of thumb here: the more data you have in your data set, the more precise an analysis on the anonymized data will be.
Want to learn more?
Stay tuned for the next part of our blog series, which will explain more about the mathematical concepts underlying differential privacy and k-anonymity in more detail.
Anonymization is just one of the tools in the security toolbox aimed primarily at doing analytics on whole sets of data that were previously denied. Managing secure data access and configuring systems securely continue to be critical operational tasks. Anonymization therefore complements other security mechanisms such as masking, authorization, and encryption.
SAP HANA has security built into its core, with a comprehensive framework and tooling for authentication and single sign-on, authorization and role management, user and identity management, audit logging, secure configuration and encryption. Find out more about SAP HANA security at http://www.sap.com/hanasecurity
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
429 -
Workload Fluctuations
1
Related Content
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- How to enable an OData V4 service for anonymous access? in Technology Blogs by SAP
- How Data Anonymization in SAP HANA secure Generative AI applications through SAP Datasphere in Technology Blogs by SAP
- SAP Fiori: How to perform masking for Fiori applications with oData V4? in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 32 | |
| 17 | |
| 15 | |
| 13 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |