This blog highlights an ASUG webcast done by Sue Waite and David Steinbruck
Of course, the more data sources you use require a more active information management practice. The saying still applies: garbage in, garbage out.
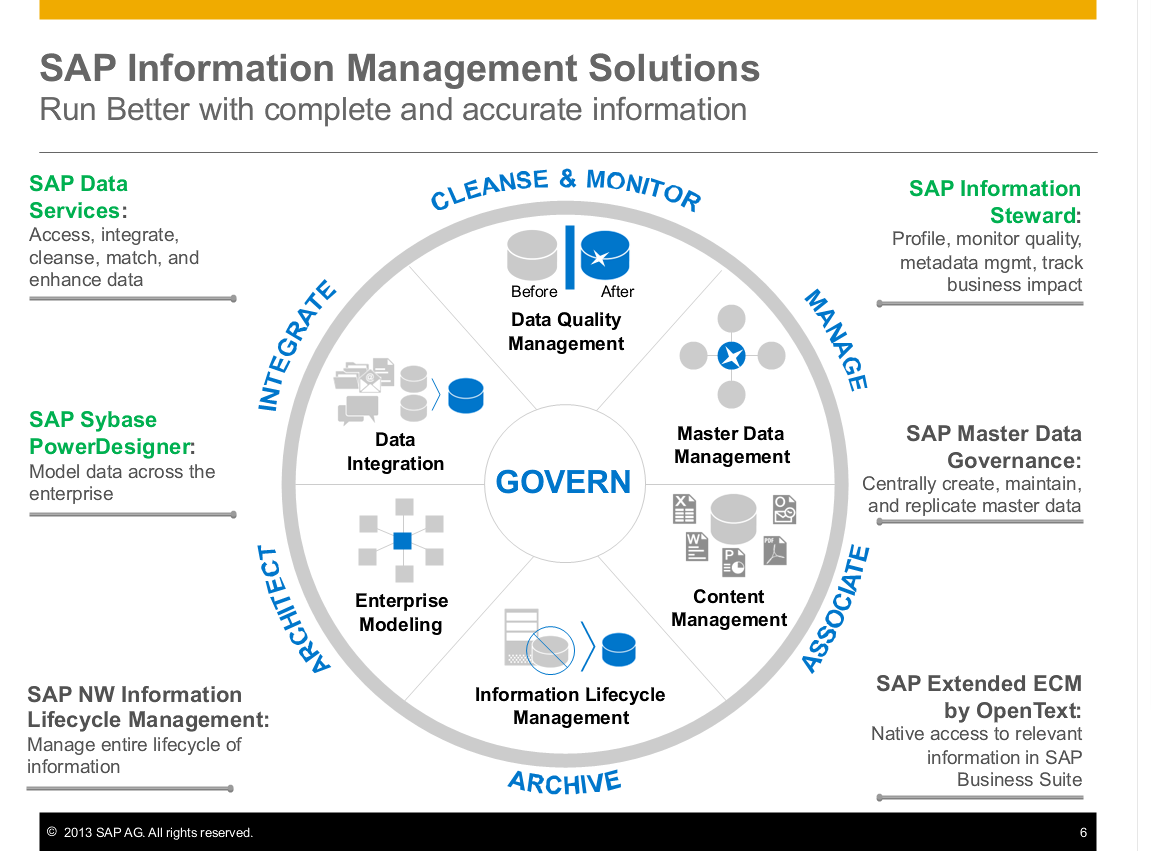
Today, we’ll be talking about SAP Data Services, SAP Information Steward, and SAP Sybase PowerDesigner. PowerDesigner helps you model data across the enterprise. Data Services helps you clean your information, and Information Steward helps you monitor and assess your information for data quality errors.
Data Services overview
Data Services supports SAP and non-SAP sources and targets. Regardless of file type, system, or application. It validates and cleans the information and then pushes that information to the downstream systems (including HANA, and BW). These scenarios work in batch or in real-time actions.

Many standard transforms are included out of the box, including key generation, pivots, etc. Data Quality transforms are also provided, as well as Text Data Processing. For a quick shot of Text Data Processing, check the example below.

Of course, Data Services is a key supporter of accurate analytics. You have to trust the data in your reports. Notice the example of disparate data from disparate systems, all moved to one single best record that can feed your BI.

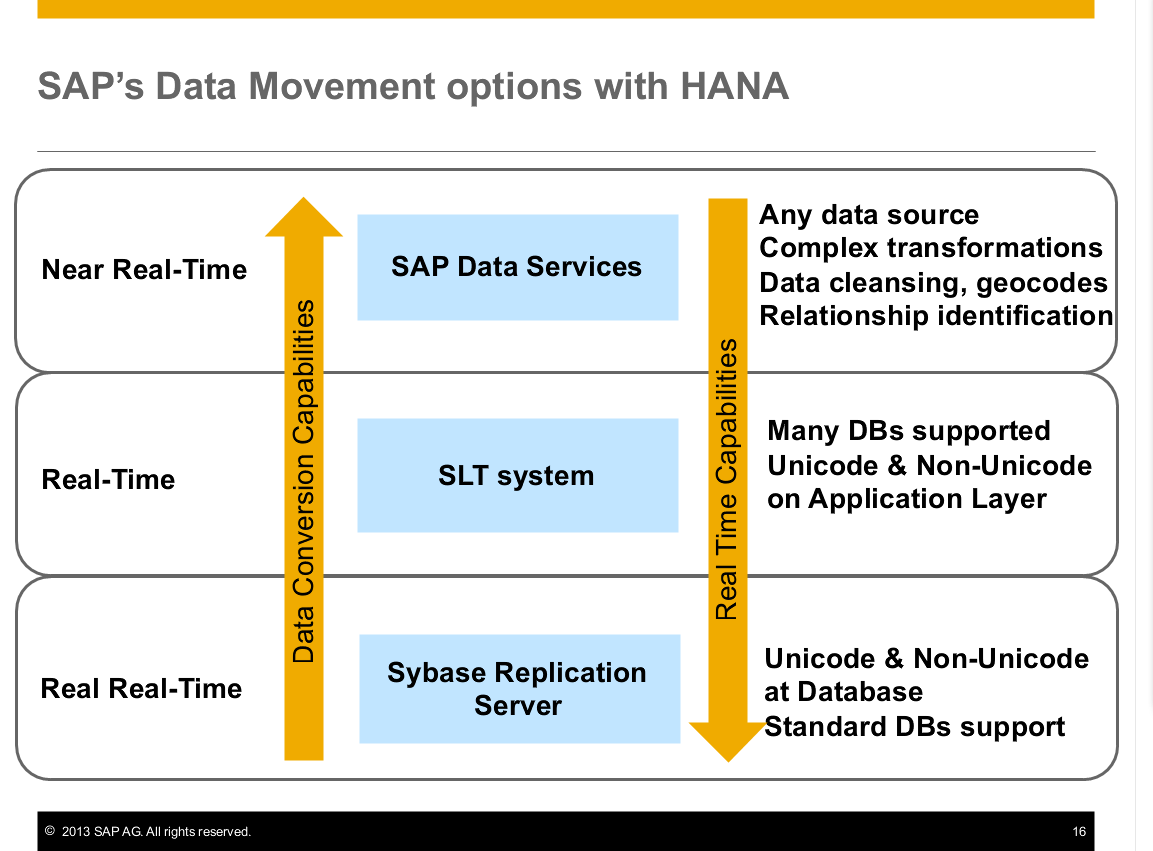
Data Services with HANA
When you use HANA, you have a few different data movement options. If you have high data conversion requirements, the Data Integration functionality that comes with HANA is perfect. However, if you also have data quality and consolidation issues, then you want the Data Services license.
Data Services 4.1 can load up to 50% faster data transfer from file and database to HANA. Also Parallelized SAP BW Data Extract is as much as 10 times faster.
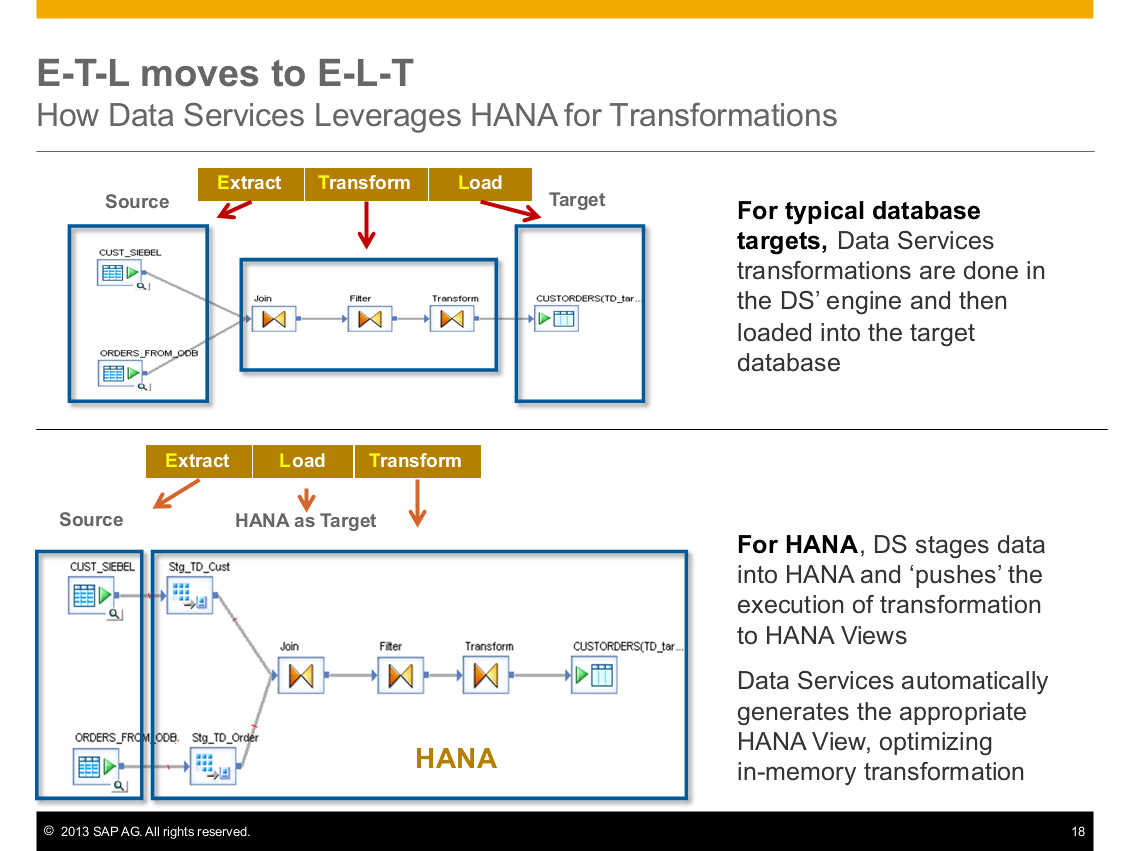
For HANA, Data Services pushes the execution of transformations down into HANA. This dramatically improves processing time.
With the 4.2 release, we are now generating HANA Calculation views. This gives Data Service very high performance result numbers.

Also in 4.2, you’ll see some integration with SLT and Replication Server. The integrated solution is for enriched CDC data provisioning across SAP ERP and non-SAP data replication. This enables changed data sharing, and leverages native CDC reading from Replication Server and SAP SLT.
Data Services does also support Hadoop. In some cases, customers want to extract information from Hadoop and move that information to HANA. Data Services definitely supports that. We even push transformations down into Hadoop as MapReduce jobs, in the case of Text Data Processing. This allows Data Services makes it transparent for your IT staff, so they don’t have to learn additional skills of writing in Pig, for example.

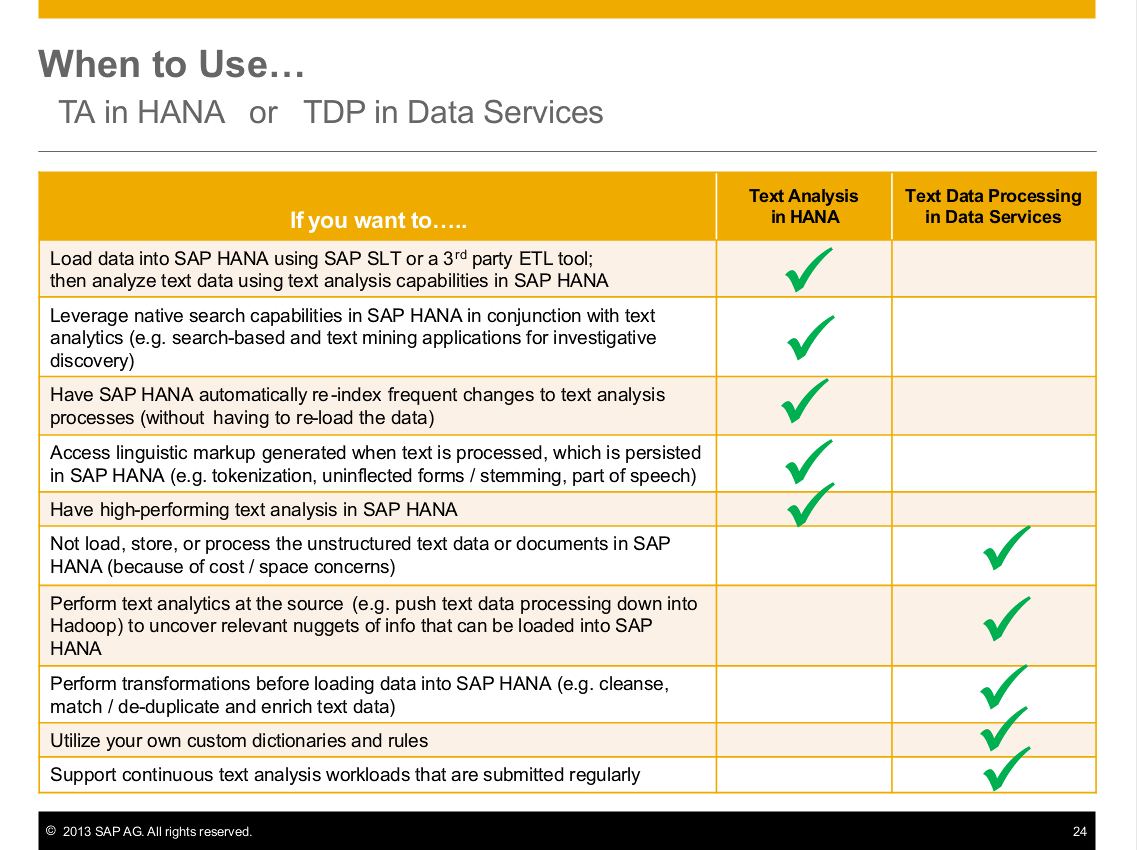
So how do you know when to use Data Services’ Text Data Processing or the Text Analytics in HANA? Follow this handy chart.
Data Services has a long history of working with BW.

You can create on-the-fly Data Services jobs from BW Workbench, and parallel loads into BW are 10 times faster with Data Services 4.1+. Auto generate Data Services extraction jobs from within BW to load data from any sources. Data Services connectivity is in BW 7.3. We also have native laoding in BW 7.3 datastores through new staging BAPIs.
Working with Business Suite
First, you have some high volume alternatives:
- ABAP tables in a regular dataflow (RFC_Read_Table). Use this for individual tables (no joins) in a regular dataflow, extract only.
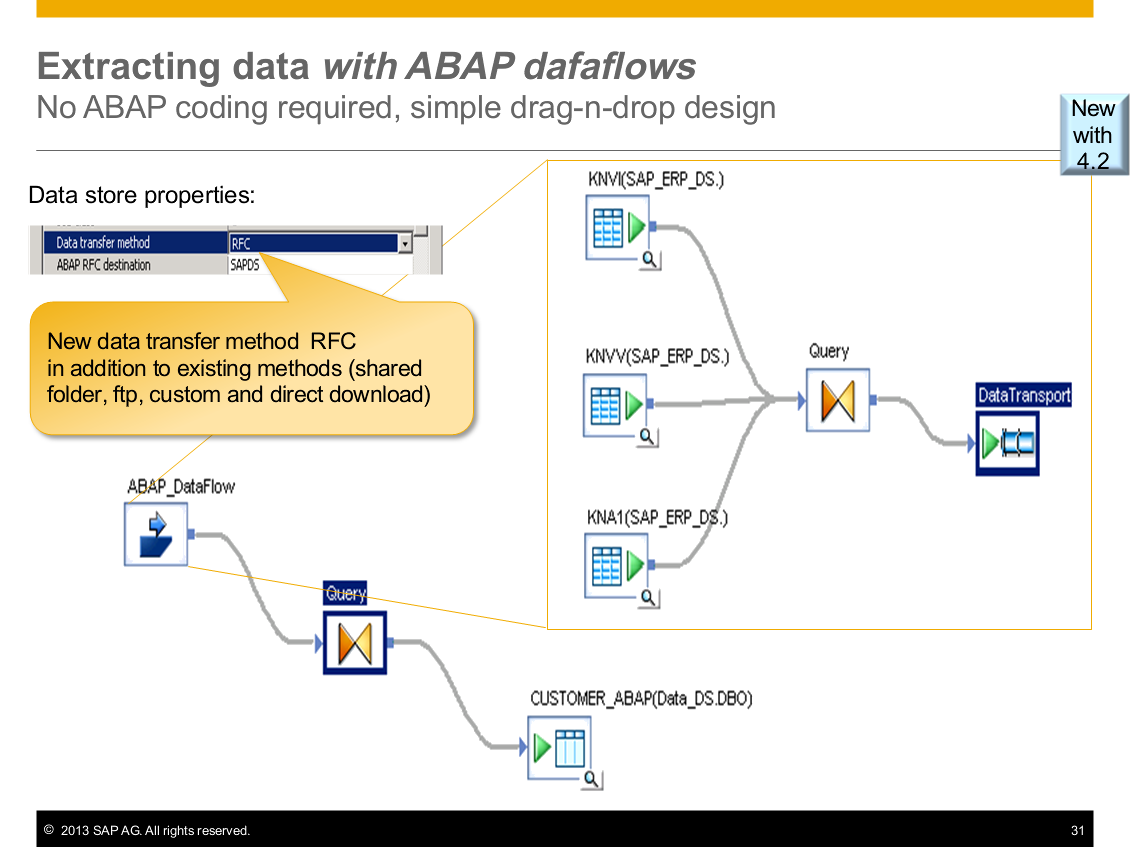
- ABAP dataflows have 100% flexibility without coding, but are also extract only.
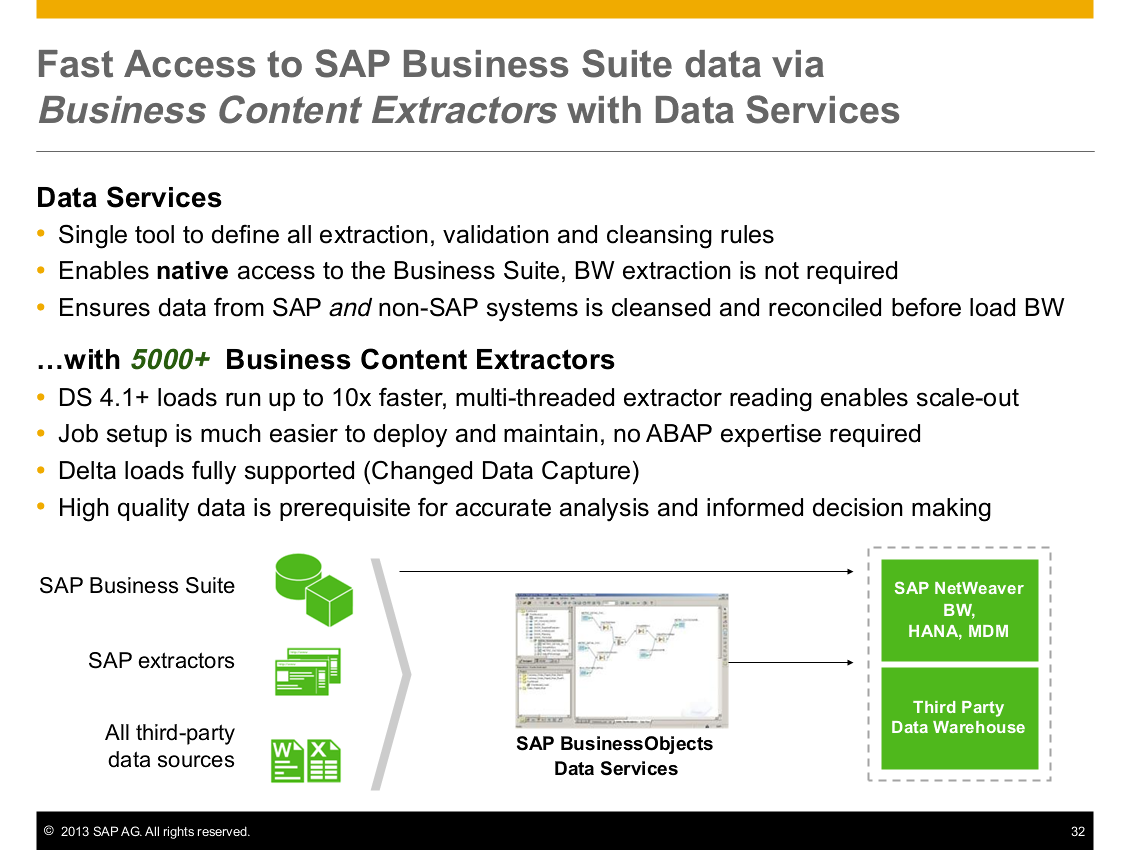
- Business Content Extractors (datasources in BW) for standard content, with out-of-the-box delta support. Extract only.
There are some special uses, which are generally not for high volume
- iDocs for real-time changes in transactional use cases, for extract and load
- BAPI function calls for small data sets, but complex processing made simple, extract, transformation, and load.
ABAP tables
We implemented RFC_Read_Table with the 4.1 release, and erformance is much faster. In 4.2, we have added the ability to do partitions for even more speed.

Data Services 4.0 introduced Business Content Extractor support. Now we support more than 5000. Remember, extractor reads is more than 10 times faster!
There’s no need to know ABAP…Data Services can take care of it for you.
Information Steward
With 4.2, profiling operations have been pushed down to HANA, which results in speed that is 1000 times faster! Yes, that’s three zeros.
The 4.2 release also has Information Steward collecting metadata from HANA. We are looking into attribute, analytic, and calculation views. This metadata also allows us to include HANA in the data lineage and impact analysis features of Information Steward.
Remember, you see the lineage, scores, and trends directly from within your BI Launchpad and WebI.
David also provided a demo. Make sure to check out the ASUG recording to get a view of the demo.
4.1 included several good features that are relevant. Check out the screen shot for the list.

Thank you, David and Sue for the webcast. If you have additional questions, please reach out to Sue.Waite@sap.com or David.Steinbruck@sap.com.
