
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- SAP TechEd 2012 – ABAP for SAP HANA: how to exploi...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-28-2012
12:57 PM
(4th part of SAP TechEd recap blog)
In the previous post I have spoken about how to optimize the performance of existing coding for SAP HANA using standard features in ABAP such as Open SQL. In this final part of our TechEd summary, I want to focus on how to exploit the power of SAP HANA from ABAP by making use of several capabilities which are not standard database features such as advanced view modeling and processing of unstructured data.
Using HANA views and procedures from ABAP
SAP HANA currently supports two main artifact types for expressing data processing logic: views and procedures. I will not drill deep at this point into the details of developing within SAP HANA (just refer to the documentation here: http://help.sap.com/hana_appliance/) but rather focus on the ABAP consumption aspects based on the concrete example introduced in the previous part. There are currently three different view types available in the SAP HANA studio
- Attribute views: used for joining a set of master-data like tables (primarily used as dimensions of analytic views and search models)
- Analytic views: roughly a star schema structure containing key figures and dimensions
- Calculation views: allows expressing more “freestyle” logic (modeled or coded via SQL Script)
Upon activation of these view models, so-called Column Views are generated in the database catalog in a technical schema (“_SYS_BIC”). These generated views can be accessed via normal SELECT statements, which are handled by specific engines inside SAP HANA using the modeling information to decompose complex requests into elementary operations (such as column scans, joins, aggregations, etc.) and executing those in an extremely efficient manner.
In current AS ABAP 7.x releases, these views are not known to ABAP data dictionary and hence (as explained in the previous part) it is only possible to use native SQL (e.g. via ADBC) to access these views e.g. as follows:

With ABAP 7.4 it will be extremely easy to consume such views because of the possibility for dictionary integration. There is a new view type in the DDIC – a so-called external view – which serves as a proxy for the view model in HANA. With the help of this, an Open SQL based access is possible so that the overall implementation in ABAP boils down to:
[....]
SELECT bp_id sum( gross_amount_converted ) FROM <external view name>
INTO TABLE lt_result GROUP BY bp_id.
[....]In addition to the simple Open SQL syntax, also other qualities like automatic client handling, support for ranges (IN clause), code completion and where-used lists are inherited. Moreover, monitoring transactions like STAD or SAT display directly information about the involved artifacts. In this scenario, having the ABAP and SAP HANA tools running inside one Eclipse installation is a big benefit because it provides an integrated developer experience.

Returning to the example introduced in the previous part, you might remember that we started with a classic pure ABAP based implementation and improved the performance on HANA by several factors using only Open SQL. As a next step we want to complete push down all calculations to SAP HANA including those parts dealing with currency conversion and date calculations which obviously cannot be expressed directly via SQL. SAP HANA supports many of such operations out of the box. For instance, currency conversions of amounts based on the standard customizing via the TCUR* tables can be defined within an analytic view without any coding as follows

We can also express the other data logic directly in HANA, so that all the data needed in our example (master data and aggregated key figures) can be retrieved from a single HANA view doing all the needed calculations on-the-fly on the operational data model. This view serves then in particular as the interface to the pushed-down logic and supports obviously easy re-use (of course, it also implies that it should be properly tested and documented).
The resulting implementation illustrates one fundamental impact of code-pushdown in the context of our concrete example: based on the more intelligent data model in HANA, the ABAP coding is much simpler and mainly focuses on the application logic.
HANA content is database content
Implementing closer to the database requires a somewhat deeper understanding of some database concepts compared to classical ABAP development. For instance, this includes aspects like schema, client, or data type handling. Let me give a simple example: within the database catalog there are multiple schemas and when accessing a table (e.g. in SQL Script) this schema context has to be defined. Assume you would write the following piece of coding within the implementation of a database procedure
[...]
select gross_amount from "SAPNSP"."SNWD_SO" order by gross_amount ASC;
[...]then this would obviously lead to problems when transporting it to another system because the schema layout would be different (i.e. the schema SAPNSP would not exist). Instead of specifying the schema within the code, it is possible to define a default schema for the procedure in HANA which is dynamically replaced when the content is transported.
Basically you will have to familiarize yourself with these concepts and design patterns because, as with standard DDIC entities, defining data structures and operations within the database requires a careful design and thorough testing as changes at later points in time are difficult if these objects are the backbone of your application. In addition to performance aspects central design goals should always be robustness, simplicity, and extensibility.
Fuzzy search enabled value helps
We already spoke about the fact that ABAP for SAP HANA is not just about performance but also provides other opportunities e.g. for easing the daily life of an end user.
Let us consider the example of value helps (or other local searches within one application). SAP HANA has powerful built-in capabilities for searching through unstructured data (such as strings) in particular stemming from its TREX inheritance. Hence without further infrastructure or replication, it is possible to make use of these features which include capabilities like
- Multi-column search (i.e. searching through multiple columns of a table or attribute view).
- Fuzzy search (i.e. finding also results which are sufficiently similar), which is in particular useful in case of spelling mistakes or upper/lower case differences.
- Synonym search (i.e. finding also terms which are synonymous to the search term), which is in particular useful in certain industry contexts (of course this requires a previous maintenance of these synonyms or term mappings).
- Full text analysis (i.e. finding patterns and structures within unstructured data) which is in particular useful in data mining scenarios.
It is required to define a so-called full-text index of the respective columns (for details, see http://help.sap.com/hana/hana_dev_en.pdf). The text search is supported in the HANA SQL dialect via the CONTAINS predicate in the WHERE clause (which as of now can only be used via native SQL from ABAP).
For example, the following SQL statement executes a fuzzy search through several columns of some address data and makes use making use of some built-in function (score for degree of similarity)

Such a select statement could for example be used in a custom value help exit which is then usable in many UI contexts (e.g. Web Dynpro ABAP, SAP UI5, SAP GUI, etc.). Yes, even SAP GUI …
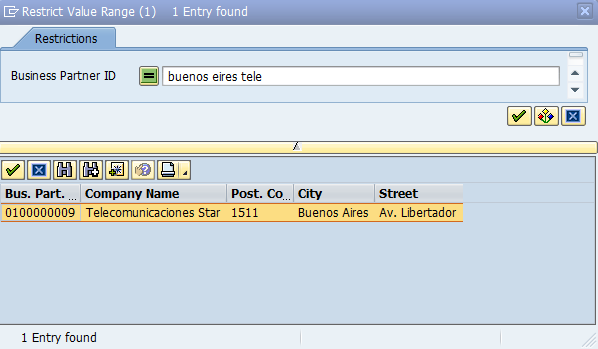
Of course, also the SAP NetWeaver Enterprise Search as central search infrastructure across applications makes use of these capabilities on SAP HANA.
Finally, it is also possible to apply the text search capabilities in other contexts such as using it for duplicate detection (e.g. look for customers with similar name and addresss before creating a new one). More generally, we strongly believe that there is a huge innovation potential in this combination of unstructured and structured data with ABAP on SAP HANA.
Bringing it all together
Starting from the original report which was running several minutes on our data set, we applied several SAP HANA features for pushing down calculations to the database, and at the same time switching to a web based user interface with an advanced search. This combination of accelerating and enhancing an existing application is one of the great innovation opportunities with ABAP on SAP HANA, which we tried to explain based on our small example.
Summary
This post concludes our series summarizing our sessions of ABAP on HANA at SAP Tech 2012. We had many very interesting discussions during and after the event and were really blown away by the interest in the topic. We are currently preparing a concise FAQ document capturing the essence of questions we received during TechEd and other events, which we will publish via SCN soon.
If you take 3 points from this blog series (resp. the lecture at TechEd), then you might want to remember:
- ABAP for SAP HANA provides entirely new opportunities for accelerating and extending existing applications, and for creating new custom applications.
- While all capabilities within SAP HANA can be in principle invoked from ABAP 7.x (e.g. using ADBC via secondary connection), AS ABAP 7.4 will be optimized for SAP HANA by allowing more native and integrated consumption of these capabilities in the AS ABAP.
- Most general ABAP performance programming guidelines remain valid on SAP HANA; some might get a different priority on SAP HANA (e.g. access to non-index columns (not bad) or nested SINGLE SINGLE * within loops (worse)).
So what’s next? While we tried to cover many aspects related to ABAP on HANA, there are also many interesting topics where we did not have the time unfortunately to drill into the details at TechEd (such as rule engines, application function libraries, combinations with HANA extended application services, etc.). And of course, there are also many other innovations in the SAP NetWeaver AS ABAP 7.4 which are not directly related to SAP HANA.
So stay tuned ...
Kind regards,
Thorsten Schneider, Eric Westenberger
- SAP Managed Tags:
- ABAP Development
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
8 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
4 -
ABAP in Eclipse
1 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
8 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
4 -
DMS
1 -
dynamic logpoints
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
General
1 -
Getting Started
1 -
IBM watsonx
1 -
Integration & Connectivity
10 -
Introduction
1 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
Product Updates
1 -
Programming Models
13 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
text editor
1 -
Tools
17 -
User Experience
5
Top kudoed authors
| User | Count |
|---|---|
| 5 | |
| 4 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 |