Intro
One of the cool things in my new role is that I get to work with the community on a daily basis and as the SAP NetWeaver Cloud platform gets traction we see lots of new people popping up willing to give it a try. It's simply amazing to see the diverse crowd of people eager to test-drive the platform: I have met old veterans, yet also newcomers who are attracted by the ease-of-use promise of PaaS and then I know there are even some high-school kids and students out there getting their feet wet and taking their first steps in the cloud. Whatever bucket you should belong to - we are happy to have you!
Some turn to me asking for help to get started and that's just fine, because that's exactly what my new role is all about: to push adoption. Admittedly, some of the questions I get asked are rather basic, yet as a wise man once said: there are no stupid questions!
Based on this rationale I figured it may be time to kick-off this "Essentials" series to lower the entry barrier even further; taking nothing for granted. This series will really focus on the "bare necessities" [feel free to hum along!] in order to help beginners to get started.
Local database support
In the first blog post of the series I want to address working with the local database as it's the domain of the most common questions I got asked lately.
By default, we launch a in-memory (in the classical sense of the word, so not HANA) Derby DB on the localhost. While that is the most simple approach and requires no work on your side it comes with the caveat that a) all data will be lost once you shutdown the server and b) that you have no way of looking at the data from the outside. We also have support for MaxDB and HANA DB, but then the number of people with access to a local HANA DB outside of SAP is rather limited at the moment I guess.
So, this is the problem space I want to adress today, by providing you with a short tutorial on how to use a local Derby DB running as a server. Interested? Here we go...
Installing Apache Derby
So, let's get started with downloading and installing Derby.
- Download the release of your choice from the website: http://db.apache.org/derby/derby_downloads.html (at the time of writing the latest release was 10.9.1.0)
- Move it and extract it to your preferred location. It should look like this:

- In the bin folder you'll find the startup scripts for both the windows and the linux world: startNetworkServer. If all goes well, you should get a console window with the following output:
Thu Jul 12 10:53:47 CEST 2012 : Security manager installed using the Basic server security policy.
Thu Jul 12 10:53:47 CEST 2012 : Apache Derby Network Server - 10.9.1.0 - (1344872) started and ready to accept connections on port 1527
Couldn't be any simpler than that, right? So, now that we have a running DB, let's do the necessary changes to the local JPaaS runtime to use this database.
Adjusting the local JPaaS runtime
Again, this is an easy change. In your Project Explorer you have a Servers node. Collapse it and drill down to the connection_data folder with the config_master node. There's a file called connection.properties.

Let's open it up and change the content so it looks as follows:
#----------------------------------------
# Connection parameters for a local Derby database
# DB and tables are created automatically (if missing)
#----------------------------------------
javax.persistence.jdbc.driver=org.apache.derby.jdbc.ClientDriver
javax.persistence.jdbc.url=jdbc:derby://localhost:1527/DemoDB;
javax.persistence.jdbc.user=demo
javax.persistence.jdbc.password=demo
eclipselink.target-database=Derby
Note: Make sure that you comment out the other DB driver definitions (by adding the # prefix.)
Bonus: Install SQuirreL to manage your data

Well, as I mentioned in the intro most of us would like to have the possibility to check the data in our DB and make some changes (if required.) There are many tools to do so, but one of my favorite ones is SQuirreL - a universal SQL tool. Not only, because it's quite versatile, easy to install and small, but also because it has a damn geeky name and... how can one not love squirrels?!? They are so cute... :wink:
So, let's quickly walk through the steps to get it up and running, shall we?
- Download the program from the website: http://squirrel-sql.sourceforge.net/#installation. There are installer for all the major platforms and the installation guide is one of the best I ever saw.
- The next thing we need to do is complete the JDBC driver definition for Derby. For this purpose, click on the Drivers tab and then select the Apache Derby Client entry. Trigger the context menu and choose Modify Driver...

- Now, we need to add the Derby Client JDBC jar to the Extra Class Path as shown below:

- Next step is to create a database alias for our DB via the Aliases tab. Simply click on the + icon, select the Apache Derby Client driver and maintain the same info we did in the connection.properties file:
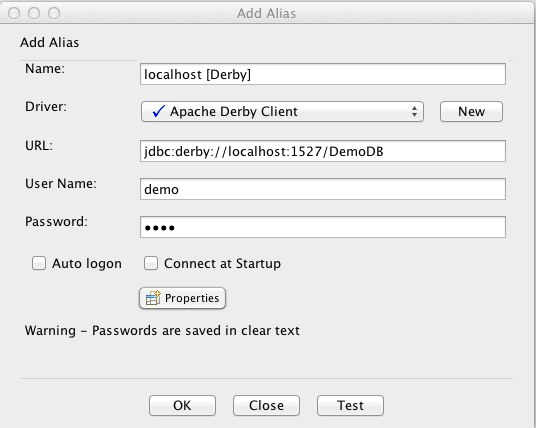
- You may want to test the connection prior to saving it to make sure all is fine! If everything works as expected, you can click OK and voilà - we are done!
With that, I leave you alone for the day... have fun coding!
