
- SAP Community
- Products and Technology
- Additional Blogs by SAP
- BW 7.30: Semantically Partitioned Objects
Additional Blogs by SAP
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Former Member
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-11-2010
3:22 AM
Abstract
SAP NetWeaver BW 7.30 introduces the concept of semantic partitioning. The following article explains how you can use semantically partitioned DataStores or InfoCubes to efficiently manage large data volumes and reduce the TCD/TCO.
Motivation
Enterprise Data Warehouses are the central source for BI applications and are faced with the challenge of efficiently managing constantly growing data volumes. A few years ago, Data Warehouse installations requiring terabytes of space were a rarity. Today the first installations with petabyte requirements are starting to appear on the horizon.
In order to handle such large data quantities, we need to find modeling methods that guarantee the efficient delivery of data for reporting. Here it is important to consider various aspects such as the loading and extraction processes, the index structure and data activation in a DataStore object. The Total Cost of Development (TCD) and the Total Cost of Ownership (TCO) are also very important factors.
Here is an example of a typical modeling scenario. Documents need to be saved in a DataStore object. These documents can come from anywhere in the world and are extracted on a country-specific basis. Here each request contains exactly one country/region.

If an error occurs (due to invalid master data) while the system is trying to activate one of the requests, the other requests cannot be activated either and are therefore initially not available for reporting. This issue becomes even more critical if the requests concern country-specific, independent data.
Semantic partitioning provides a workaround here. Instead of consolidating all the regions into one DataStore object, the system uses several structurally identical DataStore objects or “partitions”. The data is distributed between the partitions, based on a semantic criterion (in this example, "region").

Any errors that occur while requests are being activated now only affect the regions that caused the errors. All the other regions are still available for reporting. In addition, the reduced data volume in the individual partitions results in improved loading and administration performance.
However, the use of semantic partitioning also has some clear disadvantages. The effort required to generate the metadata objects (InfoProviders, transformations, data transfer processes) increases with every partition created. In addition, any changes to the data model must be carried out for every partition and for all dependent objects. This makes the change management more complex. Your CIO might have something to say about this, especially with regards to TCO and TCD!
Examples of semantically partitioned objects
Here you can set the semantically partitioned DataStores or InfoCubes (abbreviated to “SPO”: semantically partitioned object) introduced in SAP NetWeaver BW 7.30. It is now possible to use SPOs to generate and manage semantically partitioned data models with minimal effort.
SPOs provide you with a central UI that enables you to perform the one-time maintenance of the structure and partitioning properties. During the activation stage, the required information is retrieved for generating the partitions. Changes such as adding a new InfoObject to the structure are performed in the same on the SPO and are automatically applied to the partitions. You can also generate DTPs and process chains that match the partitioning properties.
The following example demonstrates how to create a semantically partitioned DataStore object. The section following the example provides you with an extensive insight into the new functions.
DataStore objects and InfoCubes can be semantically partitioned. In the Data Warehousing Workbench, choose “Create DataStore Object”, for example, and complete the fields in the dialog box. Make sure that the option “Semantically Partitioned” is set.


A wizard (1) guides you through the steps for creating an SPO. First, define the structure that are used to using for standard DataStore objects (2). Choose "Maintain Partitions".

In the next dialog box, you are asked to specify the characteristics that you want to use as partitioning criteria. You can select up to 5 characteristics. For this example, select "0REGION". The compounded InfoObject "0COUNTRY" is automatically included in the selection.

You can now maintain the partitions. Choose the button (1) to add new partitions and change their descriptions (2). Use the checkbox (3) to decide whether you want to use single values or value ranges to describe the partitions. Choose “Start Activation”. You have now created your first semantically partitioned DataStore object.


In the next step, you connect the partitions to a source. Go to step 4: “Create Transformation” and configure the central transformation using the relevant business logic.

Now go to step 5: “Create Data Transfer Processes” to generate DTPs for the partitions. On the next screen, you see a list of the partitions and all available sources (1). First, choose “Create New DTP Template” (2) to create a parameter configuration.
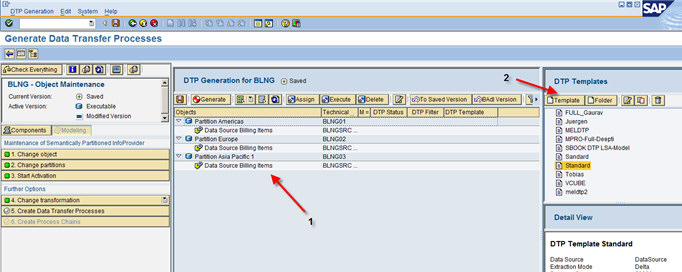
A parameter configuration/DTP template corresponds to the settings that can be configured in a DTP. These settings are applied when DTPs are generated.

Once you have created the DTP template, drag it from the Template area and drop it on a free area under the list of partitions (1). This assigns a DTP to every source-target combination. If you need different templates for different partitions, you can drag and drop a template onto one specific source-target combination.
Once you have finished, select all the DTPs (2) and choose “Generate”.

The last step is to generate a process chain in order to execute the DTPs. Go to step 6 in the wizard: “Create Process Chains”. In the next screen, select all the DTPs and drag and drop them to the lower right screen area: “Detail View (1)”. You use the values "path" and “sequence” to control the parallel processing of DTPs. DTPs with the same path are executed consecutively.

Choose “Generate” (3). The following process chain is created.

Summary
In this article, you learned how to create a semantically partitioned object. Using the central UI of an SPO it's now possible to create and maintain complex partitioned data models with minimal effort. In addition, SPOs guarantee the consistency of your metadata (homogenous partitions) and data (filtered according to the partition criterion).
Once you have completed the 6 steps, you will have created the following components:
- An SPO with three partitions (DataStore objects)
- A central transformation for business logic implementation
- 3 data transfer processes
- 1 process chain
Further Articles
Are you interested in more SAP NetWeaver BW 7.30 news? Check out the SAP BW Developers SDN Blog Series Accompanying the BW 7.3 Ramp-Up Phase
Disclaimer
http://www.sdn.sap.com/irj/sdn/index?rid=/webcontent/uuid/b0b72642-0fd9-2d10-38a9-c57db30b522e
8 Comments
Related Content
- Advanced Event Mesh Connectors and Easy Event-Driven Example of S/4HANA with Amazon S3 Integration in Technology Blogs by Members
- Recap — SAP Data Unleashed 2024 in Technology Blogs by Members
- Is it allowed to have 2 line items on the list page which have the same semantic object behind? in Financial Management Q&A
- Graph intro series, part 3: Construct and explore a Business Data Graph in Technology Blogs by SAP
- Navigating the depths of Data Aging in S/4 HANA in Technology Blogs by Members