
- SAP Community
- Products and Technology
- Additional Blogs by Members
- Unicode - Episode 1.000: The Final Chapter (Update...
Additional Blogs by Members
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
JimSpath
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-12-2008
4:14 AM
We Did IT!
Summary: Our second 6 Terabyte Weekend is complete. One business day later, no surprises have been reported. The plan was executed to successful completion, with a slow start but on time delivery.
We set a new land speed record for Unicode conversion!
The first installment of this Unicode blog series was posted prior to SAP Tech '07 Las Vegas, where I did a Community Day session on Unicode ("Unicode Free-For-All. Covers MDMP, TU-UC and more"), and then presented on our first R/3 and BW conversion earlier in 2007. Later episodes are linked below. In the spirit of Community Day, here are just a few who helped us during our project (in alphabetical order):
- Rich Bernat - Chevron - see his TechEd '06 slides on single code page conversion
- Brenda Buehl
- Nils Bürckel
- Kristen Chester - Microsoft
- Alexander Davidenkoff - see his TechEd '06 slides .
- Brad Dillingham - i18n
- Jeff Duly - Dow Corning
- Mike Eacrett - e.g., Re: combined upgrade and unicode conversion
- matt.kangas/blog
- Paul Loos - Oracle
- peter.mcnulty/blog
- Dick Mondy - Nibco
- Atul Patankar - Discovery
- Michaela See
- Mike Vergara - was with Guidant
- Hideki Yamamoto - see his TechEd '05 slides - HP
Nils and Alexander have a book "Unicode in SAP Systems" (German and English) with Detlef Werner. If not otherwise listed, names above are with SAP.
And of course, gratitude to all the team members at Black & Decker, who accomplished the following:
- Converted 16 SAP systems to Unicode, including EMEA R/3, NAPT R/3, BW, and SCM
- Moved over 20 Terabytes of data
- Built over 20 temporary SAP systems
- Leveraged IBM server virtualization to shorten conversion times and downtimes for the users
- Migrated 8 systems to Oracle 10 from Oracle 9
- Identified and retired over 300 custom SAP programs no longer in use
Team members spent a sleepless weekend so that business users were able to log on Monday morning with no noticeable difference. At the risk of forgetting someone, my sincere thanks to Bob, Donna, Chris, Kirsten, Maria, Evelyn, Jim C., Gary, Sandra, Rusty, Craig, Mike, Ian, Lou, John and all the operations and infrastructure teams.
Breaking Throughput Records
In earlier trials, we were able to move a 5TB system in around 12 hours. Our previous conversion of a 3TB production system was also around 12 hours, so we had already made improvements using such techniques as the ROWID, increased network bandwidth, and better package splitting. The rule of thumb we had been told for R3LOAD throughput was 100 MB per hour, perhaps 200 MB per hour maximum. On the other hand, I challenged our teams to move the R/3 system to a new Unicode database in 6 hours. We blew the doors and roof off prior conversions, pushing over 500 GB per hour from export start to import finish.
R/3 conversion
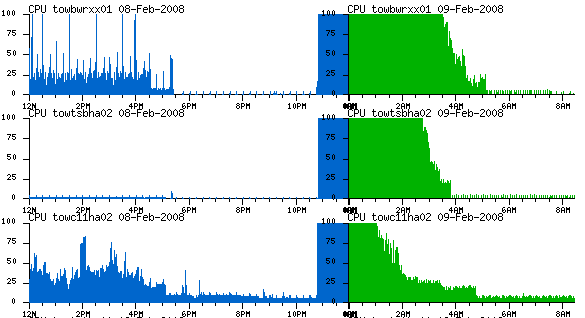

SCM conversion

COEP
COEP is one of our largest tables, so could have driven the critical path. On the first practice conversion, it took about 13 hours to export, using 2 packages. On the quality conversion (the second practice), the complete export and import was under 12 hours.This time, COEP was split into 20 packages. All 20 exports began right at the start (22:51 Friday) and the last export finished at 1:34 Saturday, 2 hours, 43 minutes. Imports began as soon as the first package ended around 10 after midnight. The final import finished at 2:34 AM, for an end-to-end time of under 4 hours. Index builds then started, which took another 4 hours.
The extra time for secondary index builds is a "cushion" we debated saving tiill later in the time line, but did not change. Further tuning might have been possible to disable some less-used secondary indexes.
Our COEP table was over 300GB before Unicode, and is now around 200GB, with the decrease a result of the database reorganization. The table has over 500 million rows.
Getting users off the system
The plan called for conversions to start after business hours Friday. However, I learned that some users were not completing transactions and logging off, so there was a significant delay there. On Sunday, as we were performing final acceptance tests, we had users connecting in Mexico, so one of our Basis team members posted this system message:
Por favor abstengase de trabajar en este sistema!!!
That worked, and we were able to continue with our checklists. For future projects where the system needs to come down, we should have a handy list of messages in different languages ready to deploy.
The other delays getting started were with the Unicode and R3Load tools. The ROWID splits didn't always seem to generate the number of packages it was told to produce, adding time and uncertainty to this step that must be done after the application is down. The other time lost was with the NAMETAB generation, which failed twice and in all 3 cases ransignificantly longer than prior tests. We still don't know why. Faults like these near the conversion start add stress to all involved, hinder the careful time line planning with multiple resource dependencies, and add uncertainty to the announced service times.
Pedal, meet Metal
To achieve the throughputs required to move 6TB in less than 12 hours, we leveraged 2 infrastructure components heavily. The first is CPU and memory virtualization, so we could increase the resources available to each application server that was part of the conversion, and dynamically move those resources to the nodes getting bottlenecks.
The second leverage was discrete network paths from source to app server, and also from app server to target. There is a chart in the quality conversion blog showing source, target and 3 app servers, along with the network cards and paths. Here's the chart for R/3 production, showing source, target and 4 app servers.

Testing teams
We had a "phone-tree" established to report testing results up to a single person authorized to give the go/no-go decision on Sunday. Despite a rough start stabilizing the environments prior to turnover to the testers, the majority reported successful completion within a couple hours. Only 1 or 2 issues surfaced that needed to be addressed. One turned out to be PC desktops with an older SAP GUI (620 not 640) which interfered with a small set of functions. As the client push is automated, and the fix known, we pushed that off until Monday. The second issue was data causing an interface program to fail. While this was identified in quality testing, data entered since the last copyback was generating faults. The interface program is old and inefficient, so we all waited around as it was run and re-run until all data were cleaned up. We believe this has a simple root cause of "cut-and-paste" where multiple dashes are turned into a single dash, which is no longer ASCII data.Database shrinkage
Our R/3 database went from 5.7 TB allocated, to 3.9 TB. Tables went from 2.4 TB size, to 1.8 TB, and indices went from 1.4 TB to 0.8 TB. As noted in prior blogs, the database size doesn't double, it usually shrinks. We got back a huge amount of space as we archived aggressively. I'll post more details if anyone requests them.
Performance Tuning
So how was performance Monday? Great. No complaints. See my recent performance blog looking at manufacturing transactions. Yesterday, we had over 13,000 dialog steps with MB51, and an average response time of 1.6 seconds.
Overall dialog response time was under 1.0 seconds yesterday, but database time is up slightly from prior weeks. This is unsurprising, as we have updated statistics on every table in the system, and it will be a few weeks as we work through to make sure these generate the SQL plans we want.
Table buffers are acting fine at the 250 MB size (generic), but I found a few fully buffered tables that are now over 5MB. We will switch these to partially buffered to save space and more quickly load useful rows.
New things we found
SAP note updates - Oracle 9 "not supported". Note 1043380 - Efficient Table Splitting for Oracle Database. We found a problem (Paul found it!) during our quality conversion where the rowid split has a couple Oracle 10 specific function calls to write log information. Paul removed these calls from the script and our conversions worked. However, the note now says Oracle 10.2 and above, which is a bit unfair, in my view.
The migration tools stumbled at the end, so a couple packages were restarted manually. This means we don't have the nice summary tables from prior conversions, and I can't easily display the export import times.
Previous Episodes
- 0.001 - [Destroyed by space pirates]
- 0.002 - Community Day and Onward
- 0.003 - Revenge of The Space Monster
- 0.004 - Children of Murphy
- 0.005 - Journey to the Edge of Quality
- 0.006 - The Calm Before the Storm of Quality
- 0.007 - Passage to Production
- 0.008 - Unicode The Final Descent
- 1.000 - The Final Chapter
[All opinions expressed are mine, not my employer's]
By the way, our Scout troop finished the Klondike sled race out of the top 3, took second place in the skills competition, and 1st place in the 2 person saw station.
Update: 18-Feb-2008
I've looked at ST03 in R/3 and in SCM during the days after the Unicode conversion and see different synptoms than our prior R/3 project. Last time, we saw CPU time on the app servers drop after Unciode, this time we are seeing a slight increase.
Here is the CPU part of dialog response time for the past several weeks, most recent first:
150.6103.0112.8110.2108.3113.3130.7
I am now looking at the top 30 transactions to see how each has changed. So far, MIGO_GR shows the biggest increase in average run time. Our overal dialog response time has been between 600 and 750 ms for the past month; after Unicode it was 824. But given we also upgraded to Oracle 10 and tuning for that has just begun in earnest, I feel we are in good shape.
[CPU charts]
February 2008 Unicode conversion - R/3 instance - app servers

May 2007 Unicode conversion - R/3 instance - app servers

Here's the Solution Manager generated "Early Watch" report for R/3 response time going back to October 2007. Again, noticeable but not worrisome upticks in these values.

12 Comments
Related Content
- Vendor Invoice Screen 'Payment' tab screen field 'DTWS1' update in Technology Q&A
- SAP Business Network For Logistics - Carrier Side ANSI-X12 EDI Setup and Testing for Road in Supply Chain Management Blogs by SAP
- SAP Solution Manager System Availability Reports in Technology Q&A
- How to open kep file - windows 10 in Enterprise Resource Planning Q&A
- SAP Signavio Process Navigator turning 1-year old today! in Enterprise Resource Planning Blogs by SAP