
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hana Smart Data Integration - The writer types, an...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-23-2016
4:51 PM
Mode "Replication"
In the most simple case the goal is a 1:1 replication. The source table and the target tables are identical in structure and content.
The easiest way to accomplish that is via creating a RepTask object.in the WebIDE of Hana and keeping the Load Behavior set to "Replication".

If the "initial load only" flag is deselected, a realtime subscription for each replicated table is created as well.

During the execution, the subscription is activated and all current data copied so that the source and target table contain the very same data.
Source
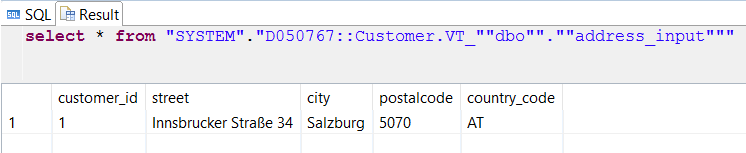
Target
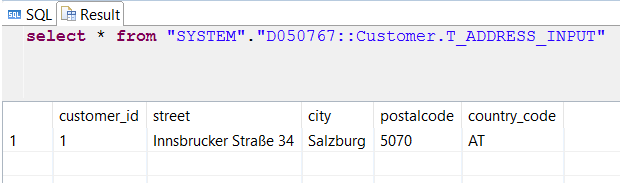
Whatever changes are made in the source, they are redone in the target as well, for example executing the commands against the source table
insert into "D050767::Customer.VT_""dbo"".""address_input"""
values ('2', 'North 1st Street', 'San Jose', '????', 'US');
insert into "D050767::Customer.VT_""dbo"".""address_input"""
values ('3', 'Hill Rd Drive 532', 'LA', '90003', 'US');
update "D050767::Customer.VT_""dbo"".""address_input"""
set "postalcode" = '95121' where "customer_id" = '2';
delete from "D050767::Customer.VT_""dbo"".""address_input"""
where "customer_id" = '1';
will cause the source to contain this data

and the target follows suit.

Mode "Replicate with logical delete"
As the adapter does send change data, Hana knows what kind of change had been made on the source system. And when loading those changes, it can apply this information plus the time the change was received. That is a quite nice feature as now the user can see what records have been recently changed. Except for deletes, it is hard to see the change information for a record which no longer exists. Therefore the feature "Replicate with logical delete" was added, where a record is not physically deleted but marked as deleted.
If a user wants to see the current data, all he has to do is to filter the records where _CHANGE_TYPE = 'D'. If the user wants to know all changes since a given time, he queries the data based on the _CHANGE_TIME.

Using above example, initially the table is loaded with all the current rows from the source and the _CHANGE_TYPE is 'I' for insert, the _CHANGE_TIME is the time of the execution of the initial load.

And after running above sequence of changes with insert, update and delete the target table looks just like above, but with record customer_id=1 being marked as 'D' for delete instead of being physically removed.

This feature is very important when it comes to loading change data in batch. A source usually does not have any change indicator. That is what makes ETL processes so complex. But with this feature the adapter is sending the changes in realtime into a replica table of Hana and is adding the change type and timestamp columns in addition. Now the batch processes can read from that table as if the source does have a delete marker and a change timestamp for each row.
And to be complete, why does the insert row have a _CHANGE_TYPE of 'A' meaning AutoCorrect Load or upsert? Because a row might have been deleted and then inserted again. The delete would not delete it but mark it as a delete-row. And if a row is inserted after, a primary key violation would be triggered, So instead of executing an insert for insert rows an upsert statement is executed.
And an expert question: Why is the update row an 'A' row? For performance reasons an update is executed as delete followed by an insert. And inserts show up as 'A' rows as stated above.
Mode "Preserve all"
In the most extreme version, the user does want to see all changes being made to a row, not just the latest version like above. This is the Preserve All mode.
This adds the _CHANGE_TYPE and _CHANGE_TIME columns but in addition a _CHANGE_SEQUENCE column as well. The latter is required as within one transaction the same row can be modified multiple times and if such change sequence would be an insert followed by an update 1 and update 2, the order is necessary to replay those changes.
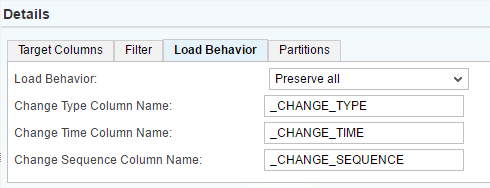
When running the initial load, all rows are copied and the _CHANGE_TYPE is 'I', the _CHANGE_TIME the current time of the start and the _CHANGE_SEQUENCE is irrelevant - one row per source primary key.

After applying the changes to the source table, the target table does look like this

Record with customer_id = 1 got deleted, record customer_id = 2 got inserted and then updated - note the adapter did send a before and after image with the identical _CHANGE_TIMESTAMP. The row with customer_id = 3 inserted.
Attention: Be very careful when using such table. This essentially dumps the information Hana gets from the adapter into a table. An adapter is not required to send a before image row, only if the source provides that information.
But more important, there are more _CHANGE_TYPEs than Insert/Update/Delete/Beforeimage/AutocorrectLoad. See Hana Smart Data Integration - The magic behind Adapter Opcodes for details.
Above modes in FlowGraphs
When using Flowgraphs to model data transformations, the same options are available. They are just presented differently.
In the Data Sink object, the target table, there is a Load Type setting. By default it is empty meaning it is a regular loader which does insert insert records, update update records etc.
Setting that to Upsert is what the "Replicate with logical delete" mode does.
And setting it to Insert means writing out all changes in the form of a change log, the "Preserve all" mode.
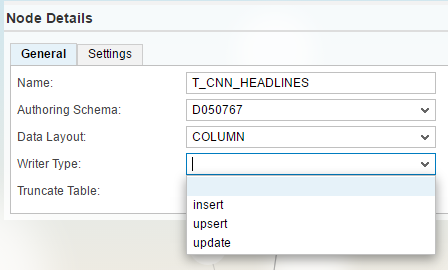
The columns for the _CHANGE_TYPE and _CHANGE_TIME are available in the second tab. Although these are optional, from a logical point of view they are needed for sure. A logical delete without the information that this row was deleted, so without a change type, makes little sense.

Time for an expert question again: Where is the _CHANGE_SEQUENCE column? (The sequence column in above screen is something else, that is an optional surrogate key)
The Flowgraph cannot cope with multiple changes within one transaction, like the insert-update-update of a single row. The Flowgraph gets an aggregated set of data always, so in this example an insert row with the final update's value.
- SAP Managed Tags:
- SAP HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
178 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
337 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
415 -
Workload Fluctuations
1
Related Content
- Lowest SAP ECC version that can be integrated with SAP BTP through Cloud Connector in Technology Q&A
- how to read the name of groovy script sap cloud integration cpi in Technology Q&A
- How to host static webpages through SAP CPI-Iflow in Technology Blogs by Members
- How to use AI services to translate Picklists in SAP SuccessFactors - An example in Technology Blogs by SAP
- Personalization for tables in HTML Container for SAP UI5 application in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 29 | |
| 21 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |