
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Working with SAP Predictive Analytics and Big Data...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member19
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-18-2016
12:35 AM
Let’s review Hadoop and SAP Predictive Analytics features in details and how these solutions can be utilized in the scenario below.
In this scenario customer’s online interaction with the various products needs to be captured from several weblogs to build predictive models for product recommendation in the future to the right group of customers. To harness the power of Big Data, one is required to have an infrastructure that can manage and process huge volumes of structured and unstructured data in real-time, and can protect data privacy and security.
In the above scenario the weblog dataset can be stored in a Hadoop environment. So, what is Hadoop? Let’s have a look at this technology first.
Data storage: Hadoop |
Hadoop is an open-source, Java-based programming framework that supports the processing of large data sets in a distributed computing environment (clusters). It is part of the Apache project sponsored by the Apache Software Foundation. Hadoop is becoming widely popular among the big data user community mainly because of:
High Reliability:
Hadoop makes it possible to run applications on systems with thousands of nodes analyzing terabytes of data. It’s distributed file system facilitates rapid data transfer among nodes and allows the system to continue operating uninterrupted in the case of a node failure. This approach lowers the risk of catastrophic system failure, even if a significant number of nodes become inoperative.
Massive parallel processing:
Hadoop has been a game-changer in supporting the enormous processing needs of big data. A large data procedure which may take hours of processing time on a centralized relational database system, may only take few minutes when distributed across a large Hadoop cluster of commodity servers, as processing runs in parallel.
Distributive Design:
Hadoop is not a single product, it is an ecosystem. Same goes for Spark. Let’s cover them one by one.
Source: -Wikipedia

Hadoop Distributed File system
Hadoop Distributed File System (HDFS) is a Java-based file system that provides scalable and reliable data storage that is designed to span large clusters of commodity servers.
YARN
Part of the core Hadoop project, YARN is a next-generation framework for Hadoop data processing extending MapReduce capabilities by supporting non-MapReduce workloads associated with other programming models.
HCatalog
A table and metadata management service that provides a centralized way for data processing systems to understand the structure and location of the data stored within Apache Hadoop.

MapReduce Framework (MR)
MapReduce is a framework for writing applications that process large amounts of structured and unstructured data in parallel across a cluster of thousands of machines, in a reliable and fault-tolerant manner.
Hive
Built on the MapReduce framework, Hive is a data warehouse that enables easy data summarization and ad-hoc queries via an SQL-like interface for large datasets stored in HDFS.
Source: Hortonworks
Key Advantages of implementing Big Data projects using SAP Predictive Analytics
Easy to use Automated Analytics
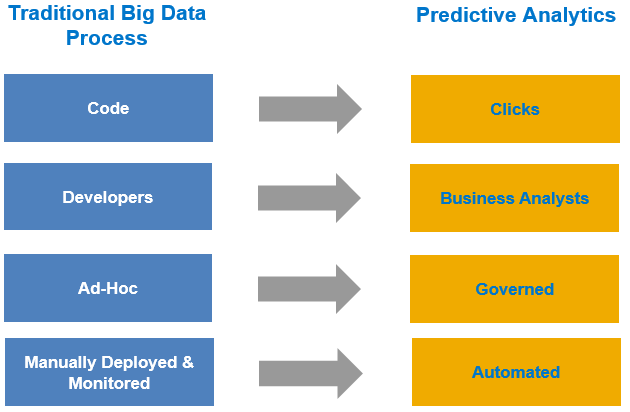
- Business users can generate predictive models in just a few clicks using Automated Analytics.
- Predictive Models on top of Big Data can be managed through Model Manager
- Deployment of the Predictive Models in Big Data systems can be automated using both Automated Analytics (Code generation or SQL generation)
- You can monitor model performance and robustness automatically through the auto generated graphical summary reports in Automated Analytics.
Connect SAP Predictive Analytics to Big Data
Using Hive ODBC driver you can connect SAP Predictive Analytics to Hadoop.
Hive ODBC connector:
Apache Hive is the most popular SQL-on-Hadoop solution, including a command-line client. Hive server compiles SQL into scalable MapReduce jobs. Data scientists or expert business users having good SQL knowledge can build analytical data set in Hive metastore (service which stores the metadata for Hive tables and partitions in a relational database) by joining multiple Hive tables. Users can then connect to Hadoop system through Automated Analytics Hive Connector for building predictive models using the analytical datasets (already persisted in Hadoop).
DataDirect ODBC driver for Hive is prepackaged with the SAP Predictive Analytics installation and lets you connect to a Hive server without the need to install any other software. Hive technology allows you to use SQL statements on top of a Hadoop system.
- From the user desktop you can open the ODBC console to create a new Hive ODBC connection.
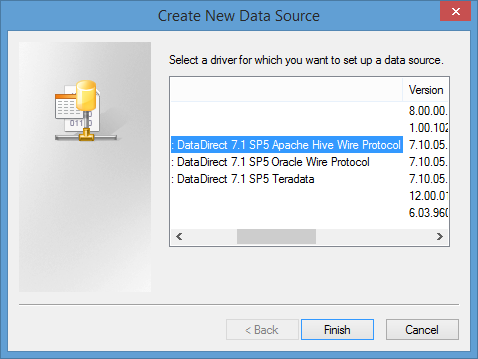
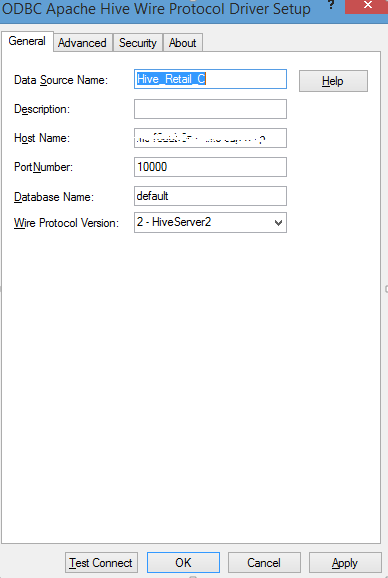
- You will need to input the host name of the Hive Server, default port number is 10000 and the Wire protocol version (2- Hive Server 2).
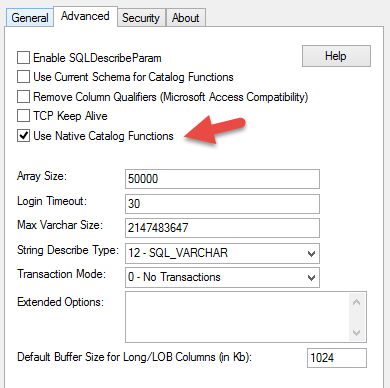
- In the general tab, check the option “Use Native Catalog Functions”. Then click “Test Connection” to make sure the connection is working.
For detailed information on how to set up your Hive connectivity, see the Hive section in the Connecting to your Database Management System on Windows or Connecting to your Database Management System on UNIX guide on the SAP Help Portal.
Predictive Modelling Process on HIVE
Create very wide datasets using Data Manager
The options below enable users to prepare datasets in Hadoop for predictive modelling.
- The Data Manager allows you to prepare your data so it can be processed in Automated Analytics. It offers a variety of data preparation functionalities, including the creation of analytical records and time-stamped populations.

An analytical dataset can be prepared by joining multiple Hadoop tables via Data Manager in Automated Analytics. Using Hive ODBC connector SAP Predictive Analytics can connect to Hive data store and you can build predictive models on Hive table dataset.
· To create an analytical dataset, open SAP Predictive Analytics application and click on the Data Manager section. Then select the Hive connection to connect to the Hadoop server.

· Select the Hive tables and join them with the keys to create the analytical dataset.

- An aggregate has been added in Data Manager for example to know number of clicks for a node/page .

Improve operational performance of predictive modelling
- Automated Analytics provides you with flexibility to scale up the performance of the model linearly with respect to the number of variables through a user friendly self-guided screen.
- In Automated Analytics Modeler - a predictive model can be trained and in-database scores can be generated directly on the Hadoop server on Hive tables (Use Direct Apply in the Database option should be checked).

Hadoop support in SAP Predictive Analytics
1. Supports full end to end operational predictive life-cycle on Hadoop .
2. (Data preparation through Data Manager->model development through Modeler ->deployment through generating SPARK/Hive SQL, Java code).
3. Automated Analytics support – through HIVE and SPARK SQL ODBC drivers. No coding required.
4. Expert Analytics support through Hive connectivity.
5. Technical details:
• Support of Hive
• Supports data preparation & scoring directly in Hadoop (no data transfer).
With new release of SAP predictive analytics, model training can be performed on spark. .
For more details on this topic please stay tuned for the upcoming blog by my colleague Priti Mulchandani.
- SAP Managed Tags:
- SAP Predictive Analytics
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
85 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
269 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
10 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
317 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
389 -
Workload Fluctuations
1
Related Content
- ML- Linear Regression definition , implementation scenarios in HANA in Technology Blogs by Members
- SAP Sustainability Footprint Management: Q1-24 Updates & Highlights in Technology Blogs by SAP
- Planning Professional vs Planning standard Capabilities in Technology Q&A
- What’s New in SAP Analytics Cloud Release 2024.07 in Technology Blogs by SAP
- What are the use cases of SAP Datasphere over SAP BW4/HANA in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 11 | |
| 11 | |
| 9 | |
| 9 | |
| 9 | |
| 9 | |
| 8 | |
| 8 | |
| 7 |