
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Intelligence – What’s New in DI:2007
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-08-2020
7:49 AM
SAP Data Intelligence, cloud edition DI:2007 is now available.
Within this blog post, we combine updates on the latest enhancements for DI:2005/2006/2007. We want to share and describe the new functions and features of SAP Data Intelligence for the August 29th release.
This section will give you only a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
This topic area focus mainly on all kinds of connection and integration capabilities which are used across the product - for example in the Metadata Explorer or on operator level in the Pipeline Modeler.
Support of SAP HANA Cloud in the Metadata Explorer, Connection Management, Pipeline Modeler (incl. SAP HANA, Connectivity, Flowagent and Structured Data Operators) which allows to consume and persist data in SAP HANA Cloud and the data lake.
Now you can connect to on premise SAP Business Warehouse (SAP BW, SAP BW on HANA and SAP BW/4 HANA) systems that are running behind a firewall using the SAP Cloud Platform, Cloud Connector.
New Structured File Consumer and Structured Table Consumer operators now provide an option to preview the data of a chosen file or table within the Pipeline Modeler:
In this topic area you will find all features dealing with discovering metadata, working with it and also data preparation functionality. Sometimes you will find similar information about newly supported systems. The reason is that people only having a look into one area, do not miss information as well as there could be also some more information related to the topic area.
Increase your return on investment in SAP Information Steward by accessing metapedia terms from SAP Data Intelligence. Support a federated solution approach for SAP Information Steward and SAP Data Intelligence.
Regain data management investment made in SAP Information Steward to add value to SAP Data Intelligence for product cost savings and efficiencies.
Increase efficiency with automation of extraction of lineage and publishing to the catalog. Enrich catalog with lineage information in the datasets processed by pipeline and data preparation.
Associate all functionalities related to metadata explorer including fact sheets, rules, and lineages with the business glossary, which is the common vocabulary used for business.
It now allows merging of multiple datasets with UNION ALL option.
Feature parity with agile data preparation. Increased functionality for business users and business analysts to perform data preparation in Data Intelligence
Support businesses with more than glossaries, which are collections of categories (which are collections of business terms). Feature parity with Information Steward and flexibility to define business glossary across Line of Business.
Join a preparation with another preparation (no self-join) while retaining all of the records of the right preparation even if unmatched, such as with a right outer join.
Union a preparation with another preparation (no self-union) while removing duplicate records, such as with distinct union.
New support preview of JSON, PDF and image files in factsheet.
The screen below shows preview of a JSON file:
This topic area covers new operators or enhancements of existing operators. Improvements or new functionality of the Pipeline Modeler and the development of pipelines.
New enhanced capabilities of the graph snippets to support more concepts of design-time configuration of a graph and to simplify the creation process including:
Now users can change an operator and save it as a new version. Multiple versions of the same operator can exist and statuses for versions can be identified as active or deprecated. This lets operator owners release new versions to users, while keeping the option of using the deprecated operators.
Users can now run a pipeline in Debug Mode to be able to see the messages between operators. In Debug Mode, the pipeline runtime view shows tracepoints for each edge in the pipeline graph that allows to open a Wiretab (message viewer) to see the edge traffic.
User can now directly import and export files from the Data Pipelines Modeler repository browser. It is also possible to directly export solutions.
Several usability improvements in existing Machine Learning applications have been implemented:
As part of conducted Model trainings which usually comes with multiple runs and with respective groupings under specific run collections, it is now possible to run all objects grouped under a specific run collection.
It is possible to deploy and run multiple models in a model server (in a single node). As a consequence, the end user can save inference costs. Moreover, sharing of GPU resources is possible as well.
Content template packages are collections of DI resources (pipelines and notebooks) that can be imported into a DI tenant using standard import capabilities in SAP Data Intelligence. Content template packages can be used to speed up implementation for ML scenarios.
This topic area includes all services that are provided by the system - like administration, user management or system management.
Users can now be granted resource quotas for pipelines and application usage to allow for fair resource distribution among the users. The following resources can be limited for users and groups using the policy framework:
New resources have been added to the policy framework to permit access to the individual SAP Data Intelligence applications (Connection Manager, Pipeline Modeler, Meta-data Explorer, etc.). This allows administrators to create new roles of users with specific permissions to use applications.
Users can now authenticate to vsystem with the System Command-line Client (vctl) using their credentials from an external Identify Provider (IdP).
The Launchpad and System Management application do now need less system resources when used by several of users by sharing the underlying instances to all tenant users.
Applications in SAP Data Intelligence can now be re-started, if needed, instead of stopping and starting them on demand. It is also ensured that only a single logical instance is running per tenant or user (depending on the type of the application).
Within this focus area, all functions and features which are dealing with the setup process, installation or deployment will be described.
Lower TCO: Minimum cluster size is now 2 dynamic nodes (down from 3).
These are the new functions, features and enhancement for SAP Data Intelligence, cloud edition DI:2007 release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
Within this blog post, we combine updates on the latest enhancements for DI:2005/2006/2007. We want to share and describe the new functions and features of SAP Data Intelligence for the August 29th release.
Overview
This section will give you only a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.

Connectivity & Integration
This topic area focus mainly on all kinds of connection and integration capabilities which are used across the product - for example in the Metadata Explorer or on operator level in the Pipeline Modeler.
Connectivity to SAP HANA Cloud
Support of SAP HANA Cloud in the Metadata Explorer, Connection Management, Pipeline Modeler (incl. SAP HANA, Connectivity, Flowagent and Structured Data Operators) which allows to consume and persist data in SAP HANA Cloud and the data lake.
Support SAP BW connection through cloud connector
Now you can connect to on premise SAP Business Warehouse (SAP BW, SAP BW on HANA and SAP BW/4 HANA) systems that are running behind a firewall using the SAP Cloud Platform, Cloud Connector.
Data Preview on Consumer Operators
New Structured File Consumer and Structured Table Consumer operators now provide an option to preview the data of a chosen file or table within the Pipeline Modeler:

Metadata & Governance
In this topic area you will find all features dealing with discovering metadata, working with it and also data preparation functionality. Sometimes you will find similar information about newly supported systems. The reason is that people only having a look into one area, do not miss information as well as there could be also some more information related to the topic area.
Import metapedia terms from SAP Information Steward into the business glossary of SAP Data Intelligence
Increase your return on investment in SAP Information Steward by accessing metapedia terms from SAP Data Intelligence. Support a federated solution approach for SAP Information Steward and SAP Data Intelligence.
Import rules from SAP Information Steward into SAP Data Intelligence
Regain data management investment made in SAP Information Steward to add value to SAP Data Intelligence for product cost savings and efficiencies.
Automate the extraction of lineage information from pipeline and data preparation
Increase efficiency with automation of extraction of lineage and publishing to the catalog. Enrich catalog with lineage information in the datasets processed by pipeline and data preparation.
Link Metadata Explorer artifacts with business glossary
Associate all functionalities related to metadata explorer including fact sheets, rules, and lineages with the business glossary, which is the common vocabulary used for business.
Support UNION ALL in data preparation
It now allows merging of multiple datasets with UNION ALL option.
Support aggregation of values in a column in data preparation
Feature parity with agile data preparation. Increased functionality for business users and business analysts to perform data preparation in Data Intelligence
Support multiple glossaries to match SAP Information Steward
Support businesses with more than glossaries, which are collections of categories (which are collections of business terms). Feature parity with Information Steward and flexibility to define business glossary across Line of Business.

Support right outer join in data preparation
Join a preparation with another preparation (no self-join) while retaining all of the records of the right preparation even if unmatched, such as with a right outer join.
Support union to remove duplicates in data preparation
Union a preparation with another preparation (no self-union) while removing duplicate records, such as with distinct union.
Data preview of JSON, PDF and Image files
New support preview of JSON, PDF and image files in factsheet.
The screen below shows preview of a JSON file:

Pipeline Modelling
This topic area covers new operators or enhancements of existing operators. Improvements or new functionality of the Pipeline Modeler and the development of pipelines.
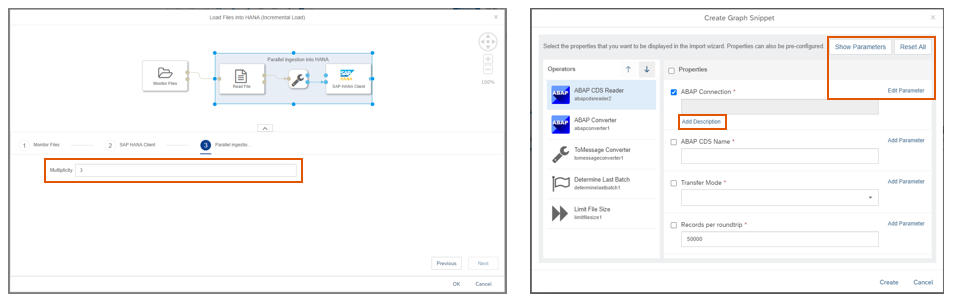
Enhanced Graph Snippet functionality
New enhanced capabilities of the graph snippets to support more concepts of design-time configuration of a graph and to simplify the creation process including:
- Support for editing existing graph snippets
- Support for group configuration in a snippet, e.g. group multiplicity
- Support to use a SVG image file as an icon for a graph snippet
- Support for adding an additional description next to parameters
- Resetting all configuration parameters
- Definition of shared parameters that can be used by multiple operator configurations of the same graph snippet
Operator Versioning
Now users can change an operator and save it as a new version. Multiple versions of the same operator can exist and statuses for versions can be identified as active or deprecated. This lets operator owners release new versions to users, while keeping the option of using the deprecated operators.
Run Pipeline in Debug Mode
Users can now run a pipeline in Debug Mode to be able to see the messages between operators. In Debug Mode, the pipeline runtime view shows tracepoints for each edge in the pipeline graph that allows to open a Wiretab (message viewer) to see the edge traffic.

Import/Export files from Data Pipelines Modeler
User can now directly import and export files from the Data Pipelines Modeler repository browser. It is also possible to directly export solutions.

Intelligent Processing
Usability Improvements in Machine Learning applications
Several usability improvements in existing Machine Learning applications have been implemented:
- Show run tags in Metrics Explorer (see screenshots below)
- Show run name in Metrics Explorer
- Improve Error Message for Duplicate Scenarios in Machine Learning Scenario Manager

Tracking SDK: Fetch Runs under Run Collection
As part of conducted Model trainings which usually comes with multiple runs and with respective groupings under specific run collections, it is now possible to run all objects grouped under a specific run collection.
Multi-Model Serving Capabilities
It is possible to deploy and run multiple models in a model server (in a single node). As a consequence, the end user can save inference costs. Moreover, sharing of GPU resources is possible as well.
Content Templates for Content Delivery
Content template packages are collections of DI resources (pipelines and notebooks) that can be imported into a DI tenant using standard import capabilities in SAP Data Intelligence. Content template packages can be used to speed up implementation for ML scenarios.
SAP HANA Python Client API for Machine Learning Algorithms: support for Time Series algorithms
- HANA ML operators now offer integration with SAP HANA's PAL (Predictive Analytics Library) and APL (Automated Predictive Library) Time Series analysis tasks for selected algorithms. In addition, requests to the HANA ML inference operator can now include inference parameters when applicable.
- The new HANA ML Forecast operator enables the use of Time Series algorithms from SAP HANA's PAL (Predictive Analytics Library) and APL (Automated Predictive Library) in a combined fit and predict step, without persisting trained models.
Administration
This topic area includes all services that are provided by the system - like administration, user management or system management.
User Resource Quotas
Users can now be granted resource quotas for pipelines and application usage to allow for fair resource distribution among the users. The following resources can be limited for users and groups using the policy framework:
- CPU consumption
- Memory consumption
- Number of Kubernetes Pods

Application Start Policies
New resources have been added to the policy framework to permit access to the individual SAP Data Intelligence applications (Connection Manager, Pipeline Modeler, Meta-data Explorer, etc.). This allows administrators to create new roles of users with specific permissions to use applications.

IdP Support for System Command-line Client (vctl)
Users can now authenticate to vsystem with the System Command-line Client (vctl) using their credentials from an external Identify Provider (IdP).
Improved Resource Efficiency of System Applications
The Launchpad and System Management application do now need less system resources when used by several of users by sharing the underlying instances to all tenant users.
Simplified Application Lifecycle
Applications in SAP Data Intelligence can now be re-started, if needed, instead of stopping and starting them on demand. It is also ensured that only a single logical instance is running per tenant or user (depending on the type of the application).

Deployment & Delivery
Within this focus area, all functions and features which are dealing with the setup process, installation or deployment will be described.
Deployment of SAP Vora is now optional when creating a new SAP Data Intelligence cluster
Lower TCO: Minimum cluster size is now 2 dynamic nodes (down from 3).
These are the new functions, features and enhancement for SAP Data Intelligence, cloud edition DI:2007 release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
- SAP Managed Tags:
- SAP Data Intelligence
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
178 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
416 -
Workload Fluctuations
1
Related Content
- What’s new in Mobile development kit client 24.4 in Technology Blogs by SAP
- AI Core - on-premise Git support in Technology Q&A
- What is the preferred way of data fetch from HANA view in ABAP Program in Technology Q&A
- what is the standard page to display employee Username in SuccessFactors : IAS or Spotlight? in Technology Q&A
- Behind the compatibility - What are the compatibility means between GRC and the plugins in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 30 | |
| 23 | |
| 10 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |