
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Dirigible - To Replicate or Not To Replicate
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-19-2014
4:56 PM
The existential question, which only seems to offer two equal and yet feasible options.
The first time we face such a question in a distributed environment (typical in the context of cloud applications) we’ll have a hard time finding the “right” answer …hmm the second time as well? The actual problem is that we cannot give a universal solution just by definition, but have to go through case by case each time. Such scenarios could be transferring data between two legacy or 3-thd party systems, between a legacy system and our custom extension, even between the different extension applications that we could have. There could be different boundary conditions depending mainly on the source and target systems’ capabilities for external communication. Sometimes, additional intermediate component could be required to cope with the integration between the systems. Hence, we need to deeply investigate the pros & cons for the given scenario, personas and components and to take concrete conscious decisions for the architectural patterns, which can be used. We have to consider also aspects like the performance for direct synchronous calls between remote systems, scalability of the source system itself, lack of tailored interfaces for our brand new use-cases, preserving the security model e.g. identity propagation, need of preliminary cache and other non-functional requirements, we often reach to the well-known situation (after taking the red pill) when – “the choice has already been made, and now you have to understand it”.
The perfect solution, no doubt, would be to avoid distributed landscapes at all, hence to extend the existing business systems in place. Unfortunately, not so many technology platforms provide full-fledged development environment for “in-system programming”, like Dirigible does. Not so many also have already built-in or bundled Dirigible. …the world is not perfect… yet. If you already have eliminated all the easy-win options for your scenario, and the only one remaining is - replication, the natural question is – let me guess – “How can Dirigible help me also in this kind of situation?” Right? Well, let’s see…
The simplified view on the replication scenario would consist of two parties, which have to transfer data one another. Let’s first answer the question: - Is it possible for the source system to be the active party, i.e. to use a “push” communication pattern? If the push pattern is possible, probably you would prefer it; hence let’s see what needs to be done at the cloud application side.
I. Push
To implement the push case, we’ll do the following:
- Create an Entity Service in JavaScript, which will consume the message – parses the incoming data and stores it in the target database table(s), according to the database schema layout of the cloud application.
Scenario Details:
1. Create a blank project


2. Create Data Structures – for the Employees

sfrepl_employees.table
{
"tableName":"SFREPL_EMPLOYEES",
"columns":
[
{
"name":"EMPLOYEE_ID",
"type":"INTEGER",
"length":"",
"notNull":"true",
"primaryKey":"true",
"defaultValue":""
}
,
{
"name":"EXTERNAL_ID",
"type":"VARCHAR",
"length":"128",
"notNull":"true",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"FIRST_NAME",
"type":"VARCHAR",
"length":"40",
"notNull":"false",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"LAST_NAME",
"type":"VARCHAR",
"length":"40",
"notNull":"false",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"REPLICATION_ID",
"type":"INTEGER",
"length":"0",
"notNull":"false",
"primaryKey":"false",
"defaultValue":""
}
]
}
3. Create an Entity Service
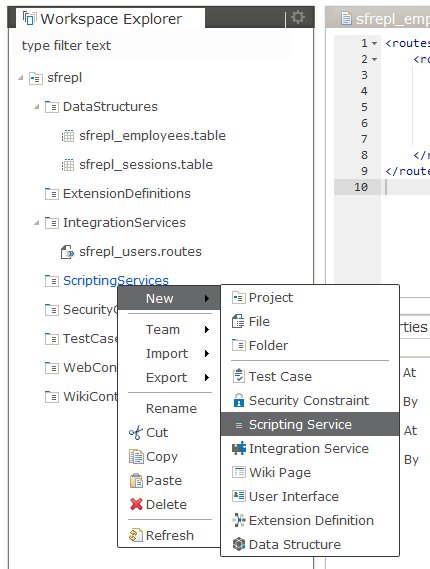
4. Select “Entity Service on Table” and…
5. … select ”SFREPL_EMPLOYEES” table
6. Give name e.g. “employees_entity_service.js”
7. Activate and Publish the project
8. Find and select the service in the Workspace Explorer
9. Take the “public” URL from the Preview

10. Use the RESTClient of your choice to send a test POST request

11. You can check the actual insert via the SQL Console at the Database Perspective
II. Pull
If we cannot use the push communication pattern above, we have to make the cloud application party active. This can be achieved by scheduling a background job, which will trigger a service, which will “pull” the needed data from the external/backend system for a given period of time. Dirigible has a micro ESB built-in, based on Apache Camel. It supports limited number of use cases and EIPs compared to the ones supported in general by Camel. Fortunately, this use case is supported by the Dirigible’s built-in ESB.
- Create an Integration Service (route), which will schedule a job by “cron” expression using Quartz underneath.
- Create Scripting Services, which will call an external OData endpoint using Destination Configuration.
- The same as above – Entity Service to store the incoming data to the target database table.
- Create optional Entity Service for storing Replication Sessions log will be useful in this case
Scenario Details:
1. Create a blank project and a table from the employees as following the steps from above
2. Create Data Structures – for the Employees and for the Replication Sessions
sfrepl_sessions.table
{
"tableName":"SFREPL_SESSIONS",
"columns":
[
{
"name":"SESSION_ID",
"type":"INTEGER",
"length":"0",
"notNull":"true",
"primaryKey":"true",
"defaultValue":""
}
,
{
"name":"SESSION_TYPE",
"type":"VARCHAR",
"length":"64",
"notNull":"true",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"SESSION_STARTED",
"type":"TIMESTAMP",
"length":"0",
"notNull":"true",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"SESSION_FINISHED",
"type":"TIMESTAMP",
"length":"0",
"notNull":"false",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"SESSION_STATUS",
"type":"INTEGER",
"length":"0",
"notNull":"true",
"primaryKey":"false",
"defaultValue":""
}
,
{
"name":"SESSION_DESC",
"type":"VARCHAR",
"length":"128",
"notNull":"false",
"primaryKey":"false",
"defaultValue":""
}
]
}
3. Activate the project
4. Create an Integration Service



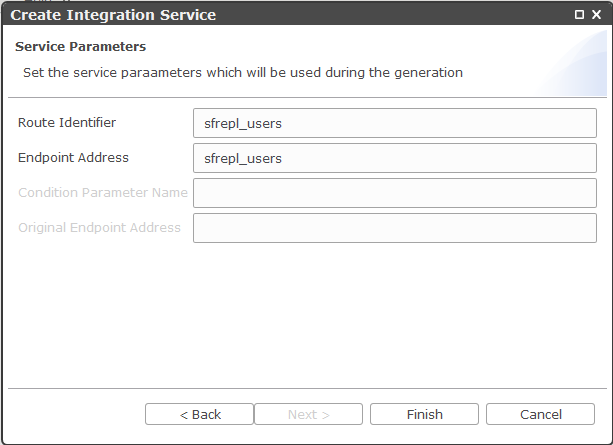
The generated service should looks like:
<routes xmlns="http://camel.apache.org/schema/spring">
<route id="sfrepl_users">
<from uri="timer://sfrepl_users?period=10000&repeatCount=10&fixedRate=true" />
<to uri="sfrepl_users"/>
</route>
</routes>
It uses the standard timer functionality. For our case we prefer to use Quartz job leveraging cron expression. Hence, replace the source code with the following:
<routes xmlns="http://camel.apache.org/schema/spring">
<route id="sfrepl_users">
<from uri="quartz://sfrepl/users?cron=0+0+0+*+*+?" />
<setHeader headerName="serviceName"><constant>/sfrepl/sfrepl_users.js</constant></setHeader>
<to uri="bean:js?method=process"/>
</route>
</routes>
Where:
* the expression “0+0+0+*+*+?” means the job will be triggered at every midnight.
* /sfrepl/sfrepl_users.js – is the path to the service to be executed
5. Let’s create the actual service now


The source code is as follows:
var systemLib = require('system');
var odata_dest = require('sfrepl/odata_dest');
var odata_call = require('sfrepl/odata_call');
var repl_manager = require('sfrepl/replication_manager');
var employees = require('sfrepl/replication_employees');
try {
var replId = repl_manager.startReplication("Users");
var replicatedCount = 0;
if (replId > 0) {
try {
var destinationPropeties = odata_dest.getODataDest();
var url = destinationPropeties.get("URL");
var user = destinationPropeties.get("User");
var password = destinationPropeties.get("Password");
var data = odata_call.callOData(url + "User?$select=userId,username,firstName,lastName", user, password);
var inserted = 0;
var updated = 0;
var failed = 0;
try {
for(var i in data.d.results) {
if (data.d.results[i].userId !== null) {
if (employees.find_employeesEntity(data.d.results[i].userId) === null) {
var id = employees.create_employees(
data.d.results[i].userId,
data.d.results[i].firstName,
data.d.results[i].lastName,
replId);
if (id !== null) {
inserted++;
} else {
failed++;
systemLib.println("Error on replicating entry: " + JSON.stringify(data.d.results[i]));
}
} else {
var id = employees.update_employees(
data.d.results[i].userId,
data.d.results[i].firstName,
data.d.results[i].lastName,
replId);
if (id !== null) {
updated++;
} else {
failed++;
systemLib.println("Error on replicating entry: " + JSON.stringify(data.d.results[i]));
}
}
}
}
} catch (e) {
systemLib.println("Error on replicating: " + e.message);
repl_manager.failReplication(replId, e.message);
} finally {
employees.purgeDeleted_employees(replId);
}
} catch (e) {
systemLib.println("Error on getting destination parameters: " + e.message);
repl_manager.failReplication(replId, e.message);
} finally {
var msg = "Replicated: " + (inserted + updated + failed) + ". Inserted: " + inserted + ". Updated: " + updated + ". Failed: " + failed + ".";
systemLib.println(" Replication ID: " + replId + " " + msg);
repl_manager.finishReplication(replId, msg);
}
}
} catch (e) {
systemLib.println("Error on checking active replication session: " + e.message);
}
- There are several important details on which we have to focus:
- Getting the destination for SuccessFactors OData API
The library module is:
odata_dest.jslib
exports.getODataDest = function() {
var ctx = new javax.naming.InitialContext();
var configuration = ctx.lookup("java:comp/env/connectivityConfiguration");
var destinationConfiguration = configuration.getConfiguration("sfodata");
var destinationPropeties = destinationConfiguration.getAllProperties();
return destinationPropeties;
};
Where the name of the destination is sfodata. More info on how to create the destination via HANA Cloud Platfrom Cockpit can be found here: https://help.hana.ondemand.com/help/frameset.htm?60735ad11d8a488c83537cdcfb257135.html
Execute the HTTP request against the SuccessFactors endpoint:
odata_call.jslib
var systemLib = require('system');
var ioLib = require('io');
exports.callOData = function(url, user, password) {
var getRequest = http.createGet(url);
var httpClient = http.createHttpClient(true);
var credentials = http.createUsernamePasswordCredentials(user, password);
var scheme = http.createBasicScheme();
var authorizationHeader = scheme.authenticate(credentials, getRequest);
getRequest.addHeader(http.createBasicHeader("Accept", "application/json"));
getRequest.addHeader(authorizationHeader);
var httpResponse = httpClient.execute(getRequest);
var entity = httpResponse.getEntity();
var content = entity.getContent();
var input = ioLib.read(content);
http.consume(entity);
var data = JSON.parse(input);
return data;
};
Do not forget – once replicated, the ownership and the responsibility of the data technically becomes yours! Alignment with the security model of the source system is a must.
Enjoy!
References:
The project site: http://www.dirigible.io
The source code is available at GitHub - http://github.com/SAP/cloud-dirigible
Forum: http://forum.dirigible.io
Twitter: https://twitter.com/dirigible_io
Youtube: https://www.youtube.com/channel/UCYnsiVQ0M9iQLqP5DXCLMBA/
Help: http://help.dirigible.io
Samples: http://samples.dirigible.io
Google Group: https://plus.google.com/111171361109860650442/posts
Blog: http://dirigible-logbook.blogspot.com/
Dirigible on SAP HANA Cloud Platform
Dirigible - Extensions vs Configurations
Dirigible is the fast track to your HCP HANA DB instance
- SAP Managed Tags:
- SAP Business Technology Platform
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
427 -
Workload Fluctuations
1
Related Content
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- Python RAG sample for beginners using SAP HANA Cloud and SAP AI Core in Technology Blogs by SAP
- Does having many replication flows increase compute/storage costs in Technology Q&A
- SAP Datasphere Replication Flow Partition Issue in Technology Q&A
- Is it possible to ignore Textcollection from BusinessPartnerReplicationIn? in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 41 | |
| 25 | |
| 17 | |
| 14 | |
| 9 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |