
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Replicate Data from SAP HANA HDI Container using R...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-24-2023
6:25 PM
In this blog post, I will talk about preparing SAP HANA Deployment Infrastructure (HDI) Container to replicate data using Replication Flow in SAP Data Intelligence or SAP Dataphere. As you may know, Replication Flow was introduced in SAP Data Intelligence Cloud in February 2022 and in SAP Datasphere in March 2023. Replication Flow let you replicate multiple datasets from a source to a target in real time with built-in resiliency. There are many great articles about it on SAP Community so I encourage you to read about them.
If you are new to SAP Business Application Studio, you can refer to various articles such as these blog posts and Developers Tutorial.
First you will create a new Dev Space for SAP HANA Native Application.
To build a HDI container, you can deploy your project in your workspace.
Now you can go to SAP BTP Cockpit. In your space, you can see your HDI container you just built in the Instances tab. You can create a Service Key here that can be used to connect from SAP Data Intelligence or SAP Datasphere. If you want to use the underline HANA Cloud in SAP Datasphere, you can refer to this nice blog post.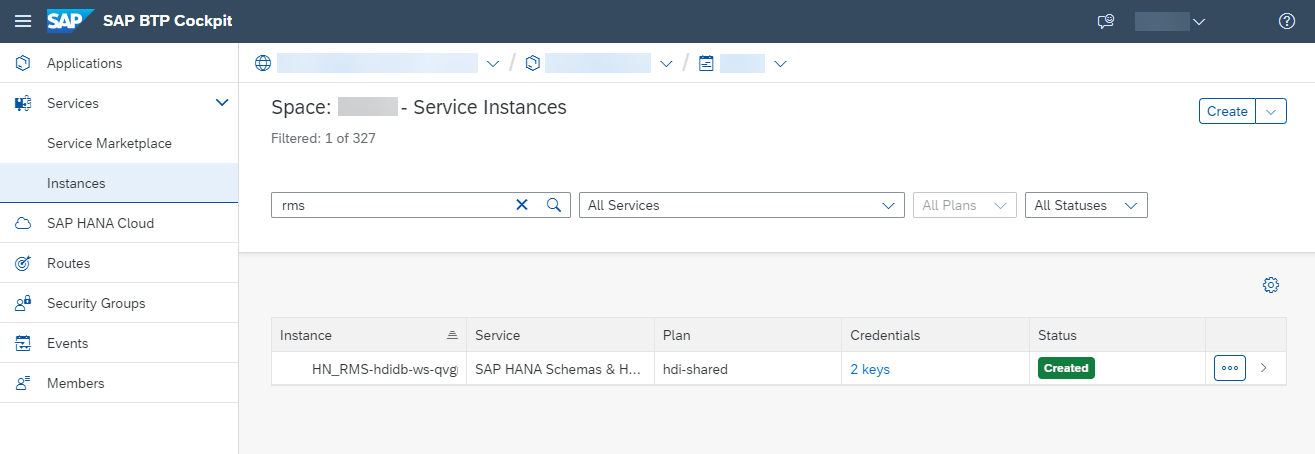
When you enable Delta load type, Replication Flow creates some necessary objects in the source system to keep track of delta changes.
To properly manage these objects, the user that is used to connect from SAP Data Intelligence or SAP Datasphere needs to be granted with the proper privileges. You can refer to HDI Reference to gain the understanding of HDI administration.
Although this is not Replication Flow specific, I will add some sample SQL statements for administrator creations as a prerequisite to the next step. You can run this on your HANA Cloud database using Database Explore. Replace the schema 'MYSCHEMA_1' with your schema name.
Replication Flow will create the triggers in the HDI container schema. It needs TRIGGER privilege to properly clean them up when the replication flow is undeployed. To allow granting the privilege to the user, we first need to set the HDI configuration parameter “api.enable_flowgraph_access” to true, which you can find in the documentation SAP HDI Configuration Parameters. Then you can grant the schema privilege to the user.
To create a connection in SAP Data Intelligence, go to Connection Management. Using the credentials you obtained from the SAP BTP Cockpit above, create a connection and click Test Connection to verify it.
Similarly, to create a connection in SAP Datasphere, go to Connections. Enter the connection details and save the connection. You can also verify the connection after saving.
To create a replication flow in SAP Data Intelligence, go to Modeler. Create a Replication Flow, select the source and target properties and create a task with your dataset.
You can deploy the replication flow, run it, and go to Monitoring from the top toolbar to view the status.
Similarly, to create a replication flow in SAP Datasphere, go to Data Builder. Create a Replication Flow, select the source and target properties with your dataset.
You can deploy the replication flow, run it, and go to Data Integration Monitor from the top toolbar.
When you run the Replication Flow with Delta load type enabled, some internal objects are created in your source system. These objects are cleaned up when you undeploy the replication flow in SAP Data Intelligence or stop it in SAP Datasphere. Please refer to the documentation Clean Up Source Artifacts for additional information.
In this article, I have walked through the steps to setup a HDI container and consumed in Replication Flow in SAP Data Intelligence and SAP Datasphere. For additional information about supported connections, you can refer to the product documentation for SAP Data Intelligence and SAP Datasphere.
Replication Flow works similarly in SAP Data Intelligence and SAP Datasphere but there are some differences. Please refer to the SAP Note and SAP Datasphere Roadmap to see the planned future enhancements. As always, if you have questions, you can post your questions on SAP Community.
Prepare a HDI Container using SAP Business Application Studio
If you are new to SAP Business Application Studio, you can refer to various articles such as these blog posts and Developers Tutorial.
First you will create a new Dev Space for SAP HANA Native Application.
SAP Business Application Studio Dev Space Creation
To build a HDI container, you can deploy your project in your workspace.
SAP Business Application Studio Workspace
Now you can go to SAP BTP Cockpit. In your space, you can see your HDI container you just built in the Instances tab. You can create a Service Key here that can be used to connect from SAP Data Intelligence or SAP Datasphere. If you want to use the underline HANA Cloud in SAP Datasphere, you can refer to this nice blog post.
SAP BTP Cockpit Instances
Grant Privileges to the HDI Container Schema
When you enable Delta load type, Replication Flow creates some necessary objects in the source system to keep track of delta changes.
To properly manage these objects, the user that is used to connect from SAP Data Intelligence or SAP Datasphere needs to be granted with the proper privileges. You can refer to HDI Reference to gain the understanding of HDI administration.
Create HDI Administrators
Although this is not Replication Flow specific, I will add some sample SQL statements for administrator creations as a prerequisite to the next step. You can run this on your HANA Cloud database using Database Explore. Replace the schema 'MYSCHEMA_1' with your schema name.
-- #### Create Administrators ####
-- Create a Container Group Admin
CREATE USER GROUPADMIN PASSWORD "Welcome1" NO FORCE_FIRST_PASSWORD_CHANGE;
-- Create a Container Admin
CREATE USER CONTAINERADMIN PASSWORD "Welcome2" NO FORCE_FIRST_PASSWORD_CHANGE;
-- #### Create HDI Container Group Admin ####
-- Grant Container Group Privileges to Container Group Admin
CREATE LOCAL TEMPORARY COLUMN TABLE #PRIVILEGES LIKE _SYS_DI.TT_API_PRIVILEGES;
INSERT INTO #PRIVILEGES (PRINCIPAL_NAME, PRIVILEGE_NAME, OBJECT_NAME) SELECT 'GROUPADMIN', PRIVILEGE_NAME, OBJECT_NAME FROM _SYS_DI.T_DEFAULT_CONTAINER_GROUP_ADMIN_PRIVILEGES;
CALL _SYS_DI.GRANT_CONTAINER_GROUP_API_PRIVILEGES('BROKER_CG', #PRIVILEGES, _SYS_DI.T_NO_PARAMETERS, ?, ?, ?);
DROP TABLE #PRIVILEGES;
-- #### Create HDI Container Admin ####
-- Connect as Container Group Admin
CONNECT GROUPADMIN PASSWORD "Welcome1";
-- Grant Container Privileges to Container Admin
CREATE LOCAL TEMPORARY COLUMN TABLE #PRIVILEGES LIKE _SYS_DI.TT_API_PRIVILEGES;
INSERT INTO #PRIVILEGES (PRINCIPAL_NAME, PRIVILEGE_NAME, OBJECT_NAME) SELECT 'CONTAINERADMIN', PRIVILEGE_NAME, OBJECT_NAME FROM _SYS_DI.T_DEFAULT_CONTAINER_ADMIN_PRIVILEGES;
CALL _SYS_DI#BROKER_CG.GRANT_CONTAINER_API_PRIVILEGES('MYSCHEMA_1', #PRIVILEGES, _SYS_DI.T_NO_PARAMETERS, ?, ?, ?);
DROP TABLE #PRIVILEGES;
Grant Schema Privileges to the User Connecting from SAP Data Intelligence / SAP Datasphere
Replication Flow will create the triggers in the HDI container schema. It needs TRIGGER privilege to properly clean them up when the replication flow is undeployed. To allow granting the privilege to the user, we first need to set the HDI configuration parameter “api.enable_flowgraph_access” to true, which you can find in the documentation SAP HDI Configuration Parameters. Then you can grant the schema privilege to the user.
-- #### Set HDI Configuration Parameter ####
-- Connect as Container Admin
CONNECT CONTAINERADMIN PASSWORD "Welcome2";
-- Prepare configuration parameters table
CREATE TABLE MY_CONFIG_PARAMETERS like _SYS_DI.TT_PARAMETERS;
INSERT INTO MY_CONFIG_PARAMETERS(KEY, VALUE) values ('api.enable_flowgraph_access', 'true');
-- Prepare parameters table
CREATE TABLE MY_PARAMETERS like _SYS_DI.TT_PARAMETERS;
-- Call procedure
CALL MYSCHEMA_1#DI.CONFIGURE_CONTAINER_PARAMETERS(MY_CONFIG_PARAMETERS, MY_PARAMETERS, ?, ?, ?);
DROP TABLE MY_CONFIG_PARAMETERS;
DROP TABLE MY_PARAMETERS;
-- #### Grant Schema Privilege to HDI Container User ####
-- Grant TRIGGER privilege to the container user as Container Admin
CREATE LOCAL TEMPORARY COLUMN TABLE #PRIVILEGES LIKE _SYS_DI.TT_SCHEMA_PRIVILEGES;
INSERT INTO #PRIVILEGES ( PRIVILEGE_NAME, PRINCIPAL_SCHEMA_NAME, PRINCIPAL_NAME ) VALUES ( 'TRIGGER', '', 'MYSCHEMA_1_3GYDEAR6R1Q6FRX4TXAZI4NPU_RT' );
CALL MYSCHEMA_1#DI.GRANT_CONTAINER_SCHEMA_PRIVILEGES( #PRIVILEGES, _SYS_DI.T_NO_PARAMETERS, ?, ?, ?);
DROP TABLE #PRIVILEGES;Create a Connection to the HDI Container in SAP Data Intelligence / SAP Datasphere
To create a connection in SAP Data Intelligence, go to Connection Management. Using the credentials you obtained from the SAP BTP Cockpit above, create a connection and click Test Connection to verify it.
SAP Data Intelligence SAP HANA Connection
Similarly, to create a connection in SAP Datasphere, go to Connections. Enter the connection details and save the connection. You can also verify the connection after saving.
SAP Datasphere SAP HANA Connection
Deploy and Run the Replication Flow
To create a replication flow in SAP Data Intelligence, go to Modeler. Create a Replication Flow, select the source and target properties and create a task with your dataset.
You can deploy the replication flow, run it, and go to Monitoring from the top toolbar to view the status.
Replication Flow Editor in SAP Data Intelligence Modeler
Similarly, to create a replication flow in SAP Datasphere, go to Data Builder. Create a Replication Flow, select the source and target properties with your dataset.
You can deploy the replication flow, run it, and go to Data Integration Monitor from the top toolbar.
Replication Flow Editor in SAP Datasphere Data Builder
When you run the Replication Flow with Delta load type enabled, some internal objects are created in your source system. These objects are cleaned up when you undeploy the replication flow in SAP Data Intelligence or stop it in SAP Datasphere. Please refer to the documentation Clean Up Source Artifacts for additional information.
Triggers created in HDI Container for Replication Flow
Summary
In this article, I have walked through the steps to setup a HDI container and consumed in Replication Flow in SAP Data Intelligence and SAP Datasphere. For additional information about supported connections, you can refer to the product documentation for SAP Data Intelligence and SAP Datasphere.
Replication Flow works similarly in SAP Data Intelligence and SAP Datasphere but there are some differences. Please refer to the SAP Note and SAP Datasphere Roadmap to see the planned future enhancements. As always, if you have questions, you can post your questions on SAP Community.
Labels:
10 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
117 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
75 -
Expert
1 -
Expert Insights
177 -
Expert Insights
358 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
15 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
398 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
493 -
Workload Fluctuations
1
Related Content
- SAP Datasphere Wish List (05/2024) in Technology Q&A
- Replication flow in DataSphere not showing the extraction enabled ABAP CDS views in Technology Q&A
- Tracking HANA Machine Learning experiments with MLflow: A conceptual guide for MLOps in Technology Blogs by SAP
- Replication Flow Blog Part 6 – Confluent as Replication Target in Technology Blogs by SAP
- Create SAP S/4HANA External GL Account Hierarchy within SAP Datasphere using standard CDS Views in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 20 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |