

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Datasphere Analytic Model Series – Motivation ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-28-2023
11:39 PM

Introduction
The SAP Datasphere Analytic Model Series is intended to provide you with useful guidance on how to utilize the new Analytic Model to leverage the potential of your data landscape. The Analytic Model allows for rich analytical modelling in a targeted modelling environment and will be THE go-to analytic consumption entity for SAP Datasphere.
This article is the third in the blog post series and highlights the motivation for the new artifact and draws comparisons to the Analytical Dataset conceptually as well as w.r.t. feature details.
So far, the following blogs have been published:
- Blog Post #1: Introducing the Analytic Model in SAP Datasphere
- Blog Post #2: Data Model Introduction
- Blog Post #3: Motivation and Comparison with the Analytical Dataset (Current Post)
- Blog Post #4: Calculated and Restricted Measures
- Blog Post #5: Exception Aggregation
- Blog Post #6: Variable Usage
- Blog Post #7: Time Dependency for Dimensions and Texts
- Blog Post #8: Data Preview
- Blog Post #9: User Experience and Navigation Paradigm
- Blog Post #10: Multi Fact Model
Let’s start by taking a closer look at what an Analytical Dataset “really” is.
Properties of the Analytical Dataset (ADS)
Views modelled as a graphical or SQL view are initially always of the semantic usage “Relational Dataset”. This implies that upon deployment, a relational, SQL-consumable database view will be created in the HANA cloud database powering SAP Datasphere.
At some point in time, users can select to change the semantic usage to "Analytical Dataset". This enables some additional features in the view’s design-time that are important for subsequent consumption of the view by SAP Analytics Cloud. These new features consist of mainly:
- Classification of view columns as either attribute or measure (including its aggregation type)
- Possibility to add semantic type information to columns. This way, modelers can add a usage context that classifies a column for example as label, currency, unit, business date (relevant for time-dependency) etc.
- Adding of associations to other entities like text or dimension objects
For a good example of this, please load the example data model of the blog series and inspect its exact properties w.r.t. semantic types & associations between entities.
On deployment of the Analytical Dataset, there will now be TWO runtime artefacts generated on SAP HANA Cloud, namely
- An analytical, SAC-consumable star schema
- A relational, SQL-consumable database view

Figure 1: Runtime artefacts of Analytical Datasets
Both of them come under the name of the Analytical Dataset itself, but
- one allows for relational queries, typically via SQL (e.g. when using an OpenSQL schema) and “lives” on HANA’s SQL engine. Its data is displayed when you preview the Analytical Dataset in the View Builder
- the other one allows for analytical queries and “lives” on SAP HANA’s Multi-Dimensional Services (MDS) engine. It is queried by SAP Analytics Cloud via the Information Access (InA) protocol.
For the comparison with the Analytic Model, let’s focus on the analytical star-schema artefact only.
Since the focus of the Analytical Dataset was always to make analytical consumption of the underlying view data extremely simple, it needed to make sacrifices with regards to the complexity of the analytical modelling itself. Concretely, these are:
- Measures in Analytical Datasets always use standard aggregations only.
These are SUM, MAX, MIN, COUNT and NONE. Other, more complex measures can be built in SAP Analytics Cloud stories - Users cannot decide which columns and associations are provided.The system automatically exposes all measures & attributes of the Analytical Datasets and always includes all first-level dimensions into the star schema also. By first-level dimensions we mean dimensions that are directly associated to the Analytical Datasets. If those associated dimensions themselves bear associations to yet other dimensions, then these will not be included. We’ll look at example cases further down in the post.
Motivation of the Analytic Model
The Analytic Model now goes beyond the analytical capabilities of the Analytical Dataset and introduces a full-fledged modelling environment that allows for a richer, targeted modelling of the properties of the analytical consumption by SAP Analytics Cloud.
If we try to heal these shortcomings within the Analytical Dataset editor, the design-environment of the Analytical Dataset would become overly complex while further mixing relational and analytical modelling in the same object. SAP therefore consciously decided to fully separate relational from analytical modelling, which lead to the introduction of the Analytic Model. This provides unique capabilities and a targeted modelling environment, including:
- Modelling of calculated measures, restricted measures and count distinct measures
- Modelling of exception aggregation behaviour on source measures and restricted measures
- Explicit decision of which measures and attributes to include
- Explicit decision of which dimensions – first-level or nth level – to include
- Analytical Data Preview for immediate, integrated testing of the current state of modelling and data with full support for slicing & dicing, filtering, hierarchy support, pivoting & much more
- Name changes for attributes & dimensions
- Design of which information to collect from end-users via variable prompts
- Global filter support
- Etc.
Aggregation Behavior – Head-to-Head Comparison
While the Analytical Dataset provides base measures with base aggregation types only, Analytic Models allow for sophisticated modelling including calculations after aggregation, restricted measures, count distinct measures as well as exception aggregation.

Figure 2: Aggregation Behavior in Analytic Model (left) & Analytical Dataset (right)
Choice of Dimensions – Head-to-Head Comparison
The Analytical Dataset represents a “default cube”. It exposes all first-level dimensions automatically, but none of the deeper levels (in the screenshot: only MCT Products). By default, this is wise since nested dimensions lead to potentially long joins at runtime paths that can weigh heavy on performance. Since many models, particularly SAP standard models imported from SAP S/4 HANA include dozens to hundreds of dimensions, many of them nested, dedicated pruning is absolutely required.

Figure 3: Analytical Datasets only include first-level associations
Modellers of Analytic Models can indeed consciously select (“prune”) which dimensions and attributes to expose (in the screenshot: all). If selected, such nested dimensions are offered on the top-level of the SAP Analytics Cloud dimension dialog. Technically, this means that the snow flake schema is simplified to a star schema and that the system automatically takes care of the joins required to achieve this.
If associated dimensions are included, their node name is taken from the respective source field (in the screenshot: e.g. Product Manager in MCT Products or Manager in MCT Employees), however this can be adapted by the modeller in the details dialog of the dimension properties in the Analytic Model editor.

Figure 4: With Analytic Model, users can choose which reachable dimensions to include
Data Preview
Analytical Datasets only offer a relational data viewer (i.e. by record), forcing users to build a SAC story to check their data and modelling. Analytic Models, however, have a built-in analytical data viewer with rich attribute/measure selection, filtering and pivoting, hierarchy support and many more features.
The View Builder used for creating the Analytical Dataset includes a data preview, but it only shows the relational artefact of the Analytical Dataset. If users want to check the results of their analytical modelling (e.g. of the information around measures/attributes, semantic types and associations), they will typically build a story in SAP Analytics Cloud to see it.
The new Analytic Model however has a built-in analytical Data Preview that provides rich functions, such as:
- Flexibly choose relevant attributes & measures to place them in columns or rows; drag & drop to re-arrange
- Set flexible filters on any attribute or measure incl. value help
- Display of hierarchies or flat presentation
- Change sorting, filtering, totals, unbooked values & display behavior (e.g. ID and/or description, number formatting, etc.)
- Preview without need to deploy first
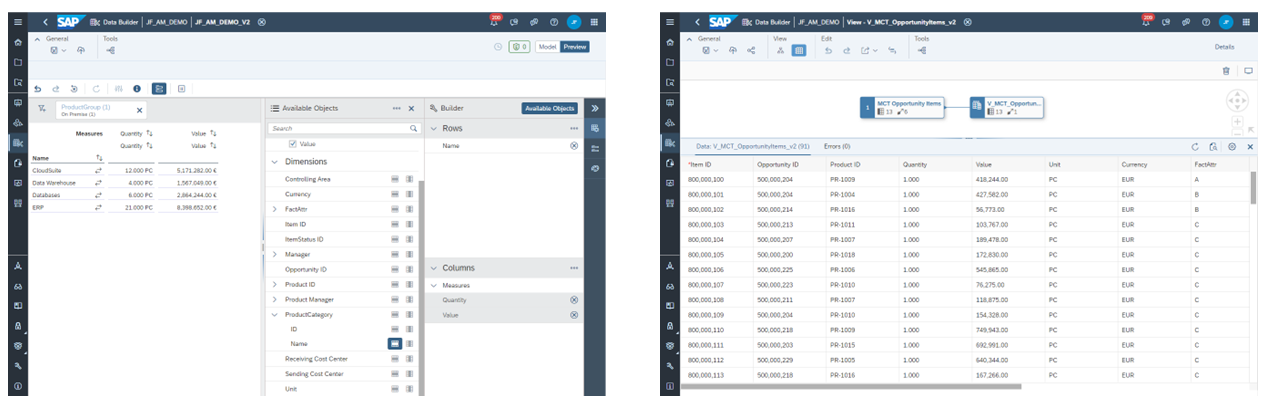
Figure 5: Data Preview Comparison in Analytic Model (left) & Analytical Dataset (right)
Terminology
For the terminology used in the Analytic Model, SAP chose to align with the terminology of SAP Analytics Cloud. This means that
- data collected from reporting users via prompts is called “Variables”. Analytical Datasets however talk about “Input Parameters” because they will eventually be parameters of the relational HANA view that is generated. Analytical Datasets have no equivalent to the Restricted Measure variables, Filter variables & Key Date variables of Analytic Models though.
- any column exposed by the Analytic Model for drill-down is a “Dimension” and this is also how they’ll be presented in SAP Analytics Cloud when choosing e.g. rows or columns of an SAC widget. In Analytical Datasets, the individual columns are known as “Attributes” and dimensions are the entities that are associated from it.
We understand that the terminology difference is subtle, but it is due to the position of the Analytic Model as a mediator between the worlds of relational artefacts (and their terminology) and their analytical consumption in SAP Analytics Cloud (with its slightly different terminology).
Analytical Datasets or Analytic Models – which one should I choose?
With Analytic Models being the cleaner and more feature-rich way of exposing data for analytics, SAP is clearly positioning Analytic Models as THE go-to alternative for analytic consumption. You should definitely try them out for yourself and start experimenting to experience their benefits. Since Analytical Datasets will not go away in the near future, however, there is no immediate rush regarding this.
To make messaging and modelling even clearer, SAP will very soon introduce a new semantic usage, "Fact", that looks and feels identically to an ADS in the design-time. The core difference is though that Facts will only deploy as relational objects and not as analytical objects. The analytical part should be modelled on top in the form of Analytic Models.
Once Facts are introduced, SAP will increasingly discourage the usage of Analytical Datasets also in the modelling environment. For example, warnings will be issued when new Analytical Datasets are created with information to instead use the combinations of Facts (for the relational part) and Analytic Models (for the analytical portion). The SAP Help Documentation will give additional guidance here.
Conclusion
This blog introduced how the Analytic Model differs from Analytical Datasets, with its superior functionality in many regards, but especially in the realms of measure modelling, dimension modelling, user interaction and data previewing. Many thanks to jan.fetzer for the collaboration on this blogpost.
Thanks for reading! I hope you find this post helpful. For any questions or feedback just leave a comment below this post. Feel free to also check out the other blogposts in the series.
Best wishes,
Philine
Further Links
- Blog: Analytic Model Series #1 – Introducing the Analytic Model in SAP Datasphere
- Blog: Analytic Model Series #2 – Data Model Introduction
- Blog: Analytic Model Series #4 – Calculated and Restricted Measures
- Blog: Analytic Model Series #5 – Exception Aggregation
- Blog: Analytic Model Series #6 – Using Variables
- Blog: Analytic Model Series #7 – Time Dependency
- Blog: Analytic Model Series #8 – Data Preview
- Blog: Analytic Model Series #9 – User Experience and Navigation Paradigm
- Blog: Analytic Model Series #10 – Multi Fact
- Analytic Model Documentation in SAP Help Portal

Find more information and related blog posts on the topic page for SAP Datasphere.
- SAP Managed Tags:
- SAP Datasphere
Labels:
8 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
274 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
327 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
405 -
Workload Fluctuations
1
Related Content
- Sneak Peek in to SAP Analytics Cloud release for Q2 2024 in Technology Blogs by SAP
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- SAP Analytics Cloud - Multiple version in Chart for Comparison in Technology Q&A
- CDS View: Time comparison in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.03 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |