
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Datasphere Intelligent Lookup Series – Harmoni...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-24-2023
6:46 AM
Introduction
The SAP Datasphere Intelligent Lookup Series is intended to provide you with useful guidance on how to utilize the Intelligent Lookup to leverage the potential of your data landscape. In order to design business processes efficiently and satisfy customers, a very high master data quality is essential. Often, this is not the case in-house. Fortunately, there are external providers who make optimized master data (e.g. organizational data and address data) available. For successful use of these, they have to be linked with internal data. SAP Datasphere provides Intelligent Lookup, a solution to match external data with internal data that semantically fits together even if there is no common key between these data.
This article is the first in the blog post series and sets the stage by showing how to successfully implement an Intelligent Lookup with a five-phase sequence model using a real-world example scenario.
We plan to release a new blog every Friday for the coming weeks. These blogs have been released so far:
- Harmonize your internal datasets with external data (this blog)
- How filtering and sorting enhances your work with Intelligent Lookup
- How to integrate an Intelligent Lookup in your existing data landscape
- What is a fuzzy match and why should I care?
- Up for a (Data) Challenge?
Please note: All data shown in this blogpost is sample data.
Table of Contents
- Sequence Model for the Intelligent Lookup
- Phase 0 – Analyze data issues
- Phase 1 – Identify external dataset
- Phase 2 – Prepare both datasets
- Phase 3 – Tune the Intelligent Lookup
- Phase 4 – Report with enriched dataset
- Conclusion
- Further Links
Sequence Model for the Intelligent Lookup
Since there are recurring problems which can be solved with an Intelligent Lookup, a standardized sequence model is presented which consists of 5 phases. The model is shown in the following figure:

Figure 1: Sequence Model (Source: Own Image)
- In Phase 0, a data problem is detected within an internal data set, which can potentially be solved by an Intelligent Lookup. Typical problems include data quality issues in the master data, and missing dimensions required for reporting that cannot be provided by internal data. In these situations, the use of Intelligent Lookup should be considered.
- In the first phase, data sources are searched that can enrich the internal data. Such a data source should offer additional fields or provide better data quality for existing fields. This data source should fit semantically so that it can be matched to the internal data via an Intelligent Lookup. The SAP Datasphere Data Marketplace can be leveraged to identify an external data source.
- In the second phase, the two data sets are prepared for the implementation of the Intelligent Lookup. It is ensured that both data sets have a primary key. In addition, it is determined which data set is to serve as input and which as lookup. Furthermore, data from both datasets can be standardized for matching, e.g. street suffixes are abbreviated in a standardized way, and new features are generated, e.g. legal form is extracted into a new field.
- Phase 3 is the setup of the Intelligent Lookup artifact. Here, the rules of the intelligent lookup are set up based on best practices (exact matching and fuzzy matching). Furthermore, confidence values for the different rules are tuned. Review cases and multiple matches can be resolved manually in this phase.
- In the last phase 4, the mapped data from the Intelligent Lookup is used to enrich the reporting. For this purpose, the Intelligent Lookup is embedded in Views and Analytic Models in the Data Builder.
Phase 0 – Analyze data issues
In our example scenario, the company utilizes two internal data sets (which are stored in SAP Datasphere) to visualize its sales reporting in SAP Analytics Cloud. One data set contains internal customer data (customer ID, company name, address data, partially German registration ID) and the other contains sales data per customer (date, revenue, customer ID) for the first half of 2022. With the available data it is possible to display the revenue per country and the revenue per customer in SAP Analytics Cloud.
These datasets can be downloaded from Data Marketplace to follow the example (Name: 'Intelligent Lookup Sample Customer Data', Data Provider: 'OPEN DATA connected by SAP'). The following is an excerpt from the internal customer master dataset.

Figure 2: Sample of internal customer master dataset (Source: Own Image)
The company has additional reporting requirements. Sales per region of the customer, sales per headquarters city of the customer and sales per legal form of the customer must be reported (the requirements are shown in the following figure). This data is currently not available within the company. In addition, the address data of the internal data set partially has errors and it is required that the data quality is improved. These requirements (additional fields and poor master data quality) are a typical case for the usage of the Intelligent Lookup. For this purpose, an external data set must be identified and mapped to the internal customer ID.

Figure 3: Reporting Requirements (Source: Own Image)
The current status of the SAP Analytics Cloud Story is displayed in the following figure:

Figure 4: Analytics Cloud Story As-Is (Source: Own Image)
Phase 1 – Identify external dataset
In the first phase, an external data set is targeted that meets the requirements and adds additional fields or better quality to the data. In our scenario, this must be a data set that contains master data on organizations (company name, address) and fits semantically to the internal data set. In addition, the data set must be maintained by a higher-level unit and must be legally usable without any problems. One place to go to find such a data set and also make it easy to use is the Data Marketplace of SAP Datasphere. It helps data providers and data consumers to exchange data in clicks, not projects - to greatly reduce the data integration efforts which currently costs time, budget & motivation in analytics projects.
For our use case, the Legal Entity Identifier (LEI) dataset managed by the Global Legal Entity Identifier Foundation (GLEIF) is suitable. It contains over 2 million legal entities worldwide that participate in financial transactions. The LEI dataset is characterized by openness, standardization and high data quality. More information can be found here. The LEI dataset can be integrated free of charge via the Data Marketplace (Name: 'Global Legal Entity Identifier (LEI) Index v2', Data Provider: 'OPEN DATA connected by SAP', see following figure). In our example, the data set is loaded into the dedicated Datasphere space at the click of a button.
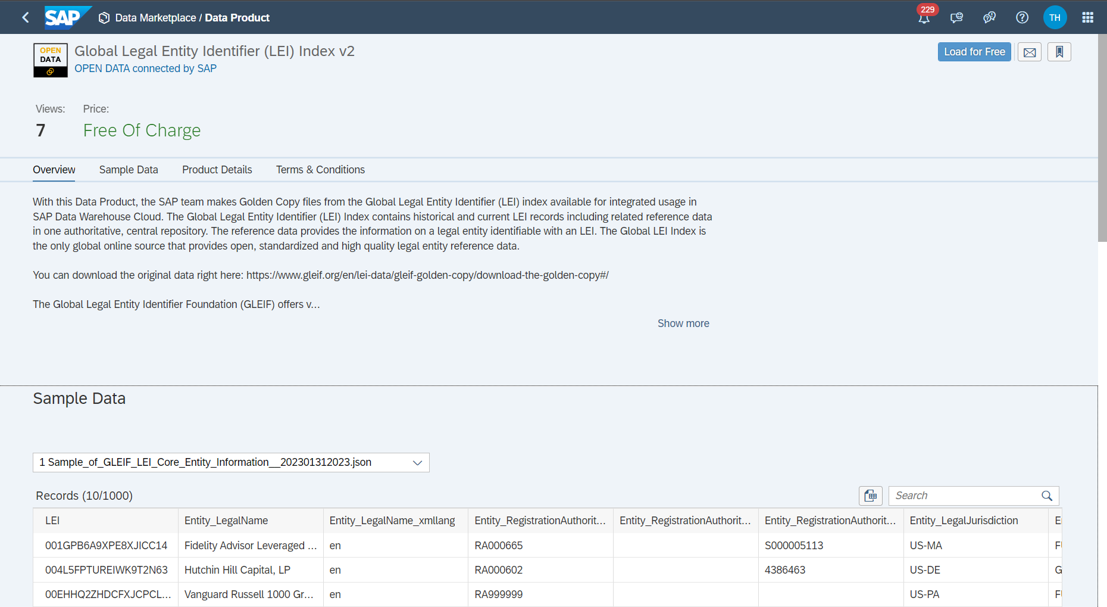
Figure 5: External Dataset in Data Marketplace (Source: Own Image)
Phase 2 – Prepare both datasets
In phase 2, now that we have identified both records, we need to prepare the data to build the Intelligent Lookup. Since both datasets need a primary key, we build one Graphical View per dataset on-top, which defines a key and also includes the data preparation (CUSTOMER_ID is the key in the internal data source and LEI is the key in the external data source). For each view we start with a projection node to rename the fields of the respective data source in a more speaking and unique way and to hide fields that are not needed. We define which data record serves as the input data record and which as the lookup. Since the company wants to use the internal customer master record for further evaluations in the future and we only want data about the customers in our system (and not all two million companies from the LEI database), we want this data set to be the input. So the external record becomes the lookup view and we add the LEI (as unique ID from this record) as lookup column to the output of the Intelligent Lookup.
Since the internal dataset contains a field for the street name and the street number and the external dataset only contains the address line, we add a computed dimension that concatenates the two fields to one address line. The following figure shows the view.

Figure 6: Graphical View for preparing internal dataset (Source: Own Image)
Since the external dataset consists of multiple tables, an inner join of multiple tables is first added to the view. As it is helpful to break a large problem into several smaller sub-problems (and smaller Intelligent Lookups), the LEI view is filtered only for German entities (Legal Jurisdiction = 'DE'). To optimize matching, two new calculated dimensions are added. In terms of standardization, the company name is cleaned without storing the legal form. Furthermore, a new feature is generated: the German Registration ID is extracted into a field for German entities to be able to match with the German Registration ID from the internal dataset. The expressions of the two new fields are shown below:
CD_German_Registration_ID (String 5000):
CASE
WHEN Legal_Jurisdiction = 'DE' AND Registration_Authority_Entity_ID LIKE 'HRB %'
THEN SUBSTR_AFTER(Registration_Authority_Entity_ID, 'HRB ')
ELSE NULL
ENDCD_Name_without_Legal_Form (String 5000):
CASE
WHEN Legal_Name LIKE '% SE%'
THEN SUBSTR_BEFORE(Legal_Name, ' SE')
WHEN Legal_Name LIKE '% AG%'
THEN SUBSTR_BEFORE(Legal_Name, ' AG')
WHEN Legal_Name LIKE '% N.V.%'
THEN SUBSTR_BEFORE(Legal_Name, ' N.V.')
WHEN Legal_Name LIKE '% N.A.%'
THEN SUBSTR_BEFORE(Legal_Name, ' N.A.')
WHEN Legal_Name LIKE '% KGaA%'
THEN SUBSTR_BEFORE(Legal_Name, ' KGaA')
WHEN Legal_Name LIKE '% Aktiengesellschaft%'
THEN SUBSTR_BEFORE(Legal_Name, ' Aktiengesellschaft')
WHEN Legal_Name LIKE '% AKTIENGESELLSCHAFT%'
THEN SUBSTR_BEFORE(Legal_Name, ' AKTIENGESELLSCHAFT')
WHEN Legal_Name LIKE '% Kommanditgesellschaft%'
THEN SUBSTR_BEFORE(Legal_Name, ' Kommanditgesellschaft')
WHEN Legal_Name LIKE '% GmbH%'
THEN SUBSTR_BEFORE(Legal_Name, ' GmbH')
WHEN Legal_Name LIKE '% e.V.%'
THEN SUBSTR_BEFORE(Legal_Name, ' e.V.')
ELSE Legal_Name
END
The view of the external LEI data can be seen below.
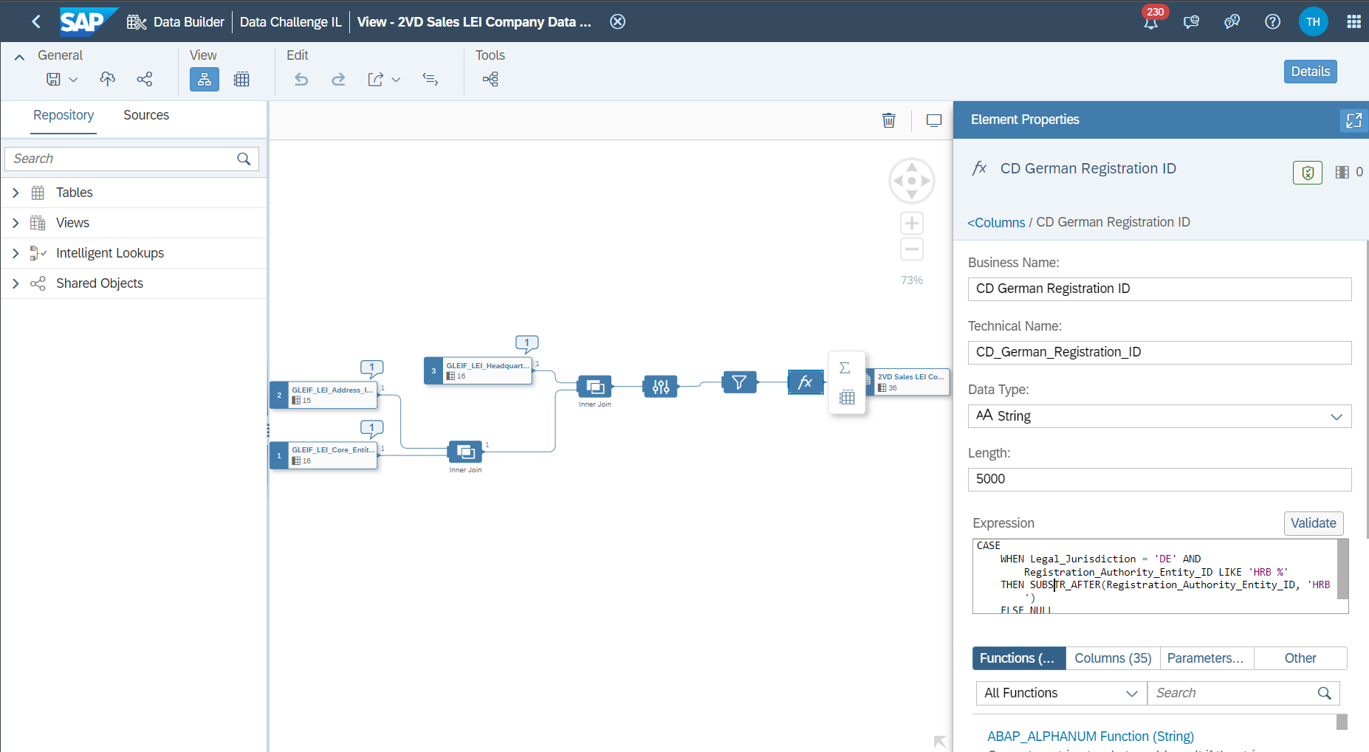
Figure 7: Graphical View for preparing external dataset (Source: Own Image)
Phase 3 – Tune the Intelligent Lookup
In phase 3, the Intelligent Lookup is built and customized. Since more blogposts on this phase will follow, including best practices, we will refrain from a detailed description here. However, it should be mentioned that the Pareto principle should be followed: with 20% of the work, 80% of the cases can be covered. It makes sense that the rules should evolve from general to detailed. At first, exact match rules are used and as the work progresses, fuzzy match nodes are implemented. Since in some entries on both sides a registration ID is maintained, it makes sense to start with an exact match on this ID and then design the further paths.
In our example, the Intelligent Lookup reaches a depth of 14 nodes, as shown in the following figure. Depending on the needs, the depth can vary, usually more nodes mean less manual effort to check multiple matches and unmatched entries, but also a higher maintenance effort and complexity level.

Figure 8: Intelligent Lookup Example (Source: Own Image)
It is also useful to continuously check the review cases and multiple match cases manually and to try different confidence values for matches and review cases. Reasonable confidence values should not be too low, but exact numbers are very dependent on the format of the data. In the following we will show how multiple match cases and review cases are resolved in our example.

Figure 9: Resolving Multiple Match Cases (Source: Own Image)
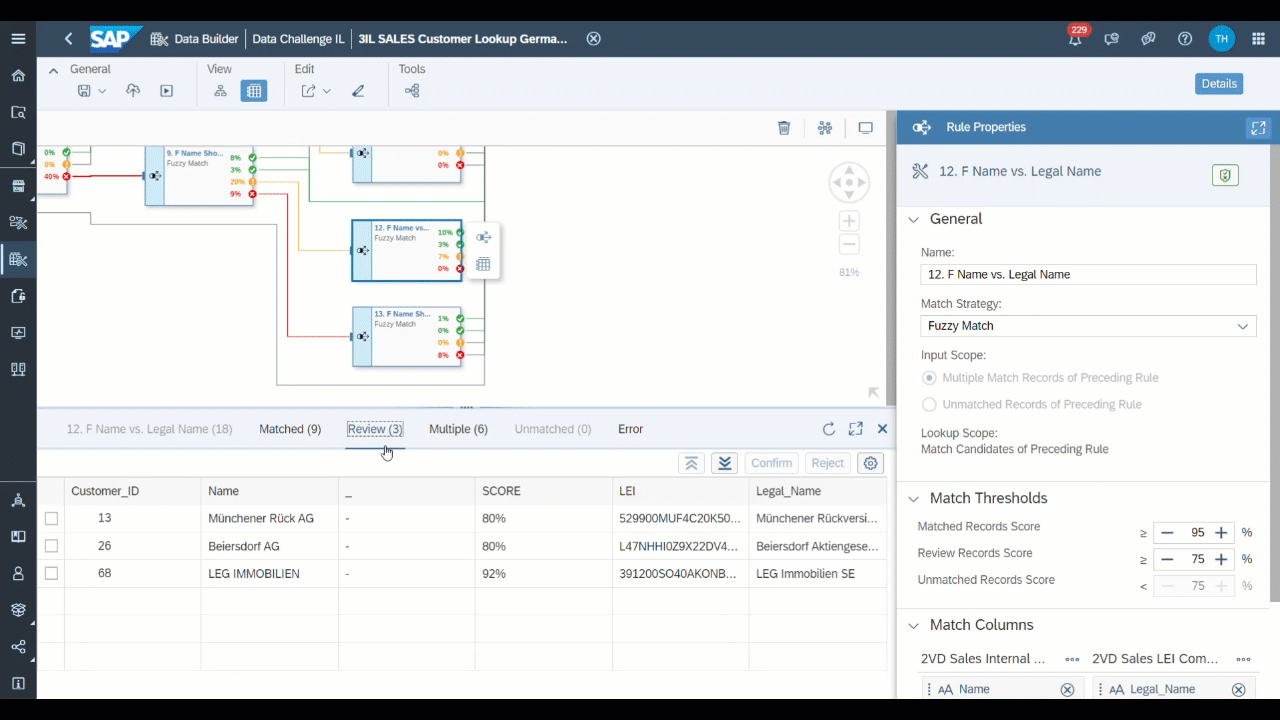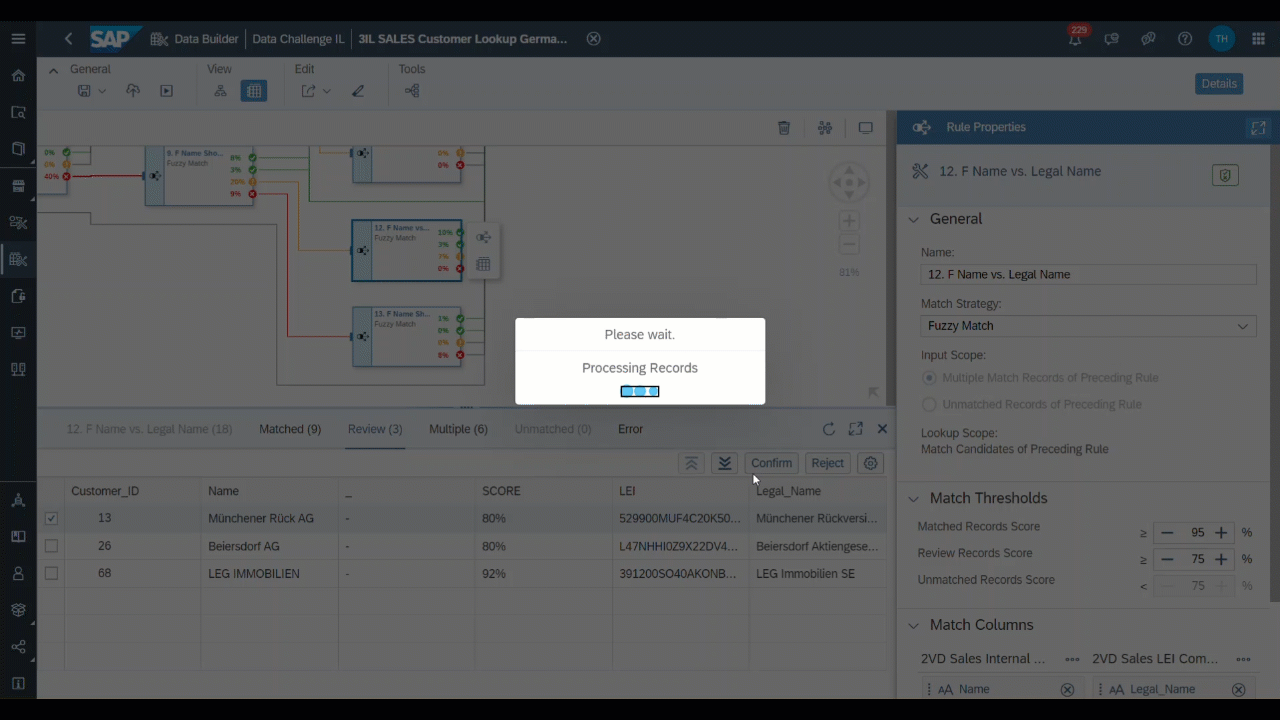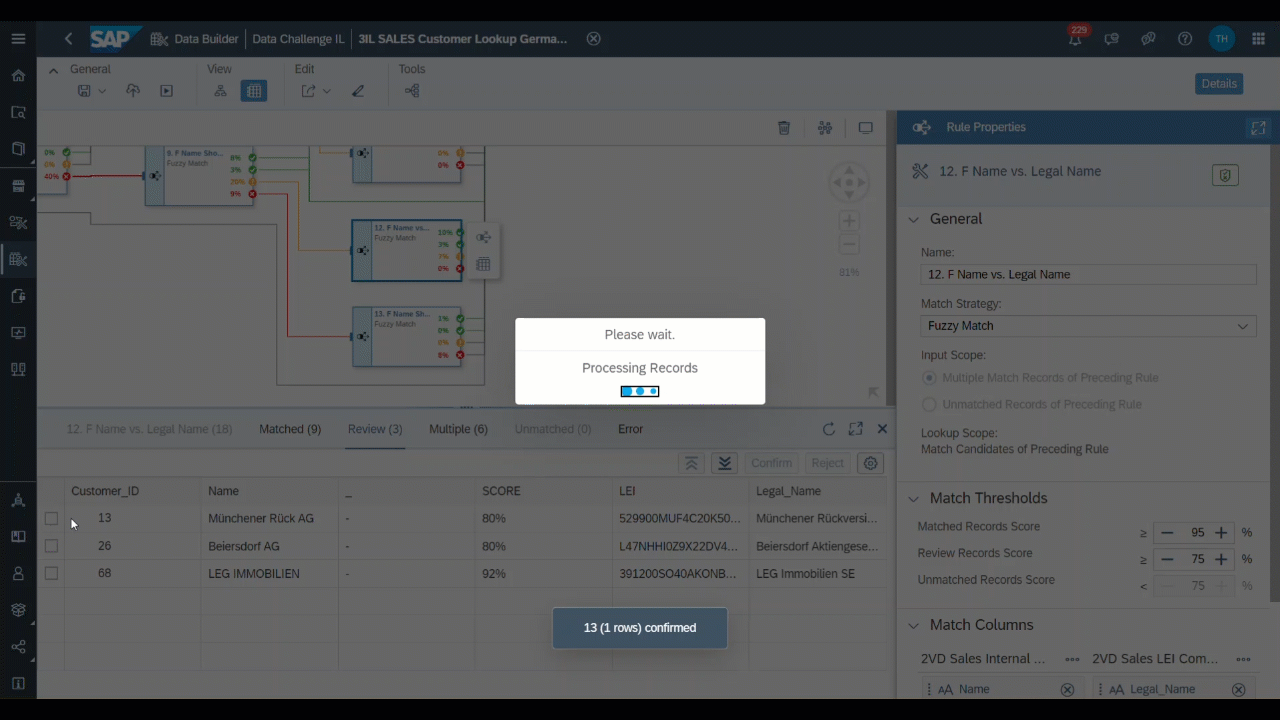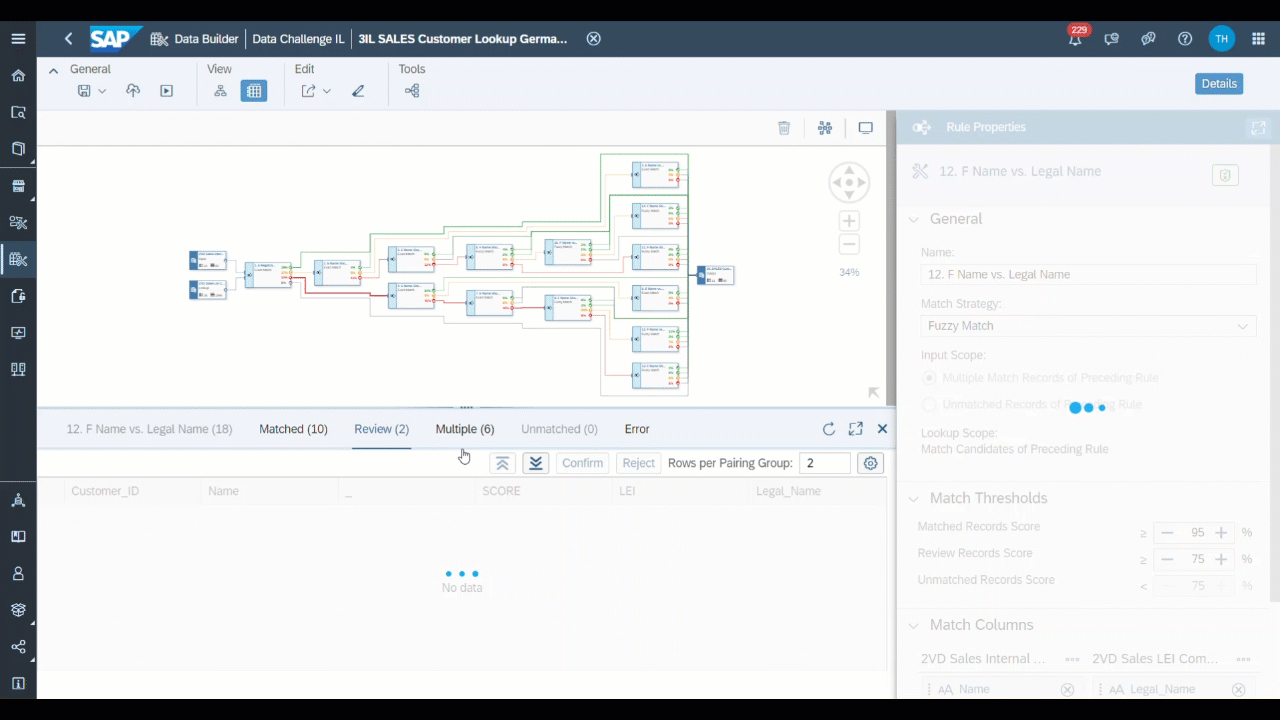
Figure 10: Resolving Review Cases (Source: Own Image)
To document the results of the Intelligent Lookup, it is recommended to create a table that summarizes the results. The table should describe the configurations of the rules, how these rules are linked, and specify the results per node. The following table summarizes the results of our example cases. In our example, 20% of the data was manually classified (using Review and Multiple suggestions) and a total of 8% of the data could not be classified. These 8% are entries that have maintained an address outside of Germany. Since we filtered the external LEI data set to Germany (see phase 2), these entries could not be matched on purpose.

Figure 11: Result Table Intelligent Lookup (Source: Own Image)
Phase 4 – Report with enriched dataset
In the last phase 4, we can finally extend the reporting in SAP Analytics Cloud as the Intelligent Lookup has been built. To do this, we construct an Analytic Model that associates customer data from the internal dataset with data from the Lookup dataset (LEI dataset) and links both to sales data from the first half of 2022. We associate two further datasets: To additionally drill down to year/quarter/month in reporting, a standardized time dimension is connected. In order to be able to display the texts per legal form (in the LEI dataset the entity legal form code from ISO 20275 is represented) we associate an ISO 20275 table. The artifacts used in our example case are shown with their dependencies in the following figure.

Figure 12: Data Model of the Sales Reporting Example (Source: Own Image)
In detail: In our example, the Intelligent Lookup contains the LEI column from the external dataset view (the primary key). Therefore, we build a dimension view on-top, which merges the internal customer data from the Intelligent Lookup with the LEI record (via a left outer join). Additionally, we join with a table containing the names of legal forms to an ISO code. In a view of type Analytical Dataset, we join the sales data with the customer dimension and also associate a time dimension. From this Analytical Dataset view, we generate an Analytic Model, which becomes our interface for the SAP Analytics Cloud Story.
The customized SAP Analytics Cloud Story can be seen in the following figure. Now, analyses are possible per region, per legal form and per headquarters city.

Figure 13: Analytics Cloud Story To-Be (Source: Own Image)
Conclusion
In this blog post, it was shown that SAP Datasphere, with Intelligent Lookup and Data Marketplace, provides two exciting tools to enrich your master data with external data to optimize your processes and increase customer satisfaction:
- Data sets without a common key can be assigned to each other
- External data can be integrated by clicking a button
- Extended data analyses are possible through the incorporation of new fields
- The master data quality can be improved
A five-phase sequence model was presented to successfully build Intelligent Lookups. Each phase was explained by means of an example.
Thanks for reading! I hope you find this post helpful. For any questions or feedback just leave a comment below this post. Feel free to also check out the other blogposts in the series. I would like to thank my colleagues carolivia, florian91, josef.georg.hampp, and he-rima for collaborating on the blogpost series.
Best wishes,
Tim
Further Links
- One-Stop-Shop to Intelligent Lookup in SAP Datasphere
- End2End Walk Through – Intelligent Lookup
- Intelligent Lookup Documentation in SAP Help Portal
- A deeper look into how SAP Datasphere Enables a Business Data Fabric

Find more information and related blog posts on the the topic page for SAP Datasphere
- SAP Managed Tags:
- SAP Datasphere,
- SAP Business Technology Platform
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
294 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- SAP Datasphere インテリジェントルックアップ : 名寄せ機能のご紹介 in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Customers and Partners are using SAP BTP to Innovate and Extend their SAP Applications in Technology Blogs by SAP
- What are the use cases of SAP Datasphere over SAP BW4/HANA in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 14 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 4 | |
| 4 |