
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Technical architecture for native cloud applicatio...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-21-2023
6:27 PM
This is the 2nd part of the 4 blog posts about the technical architecture of native cloud applications:
In the previous blog post we performed a very short review of the different software architecture trends. This post will detail how to build a scalable, reliable, and performant large-scale application step-by-step. Starting with a basic architecture, we'll apply patterns to scale it up to millions of users and we will explain how these patterns are also used by SAP to develop our own applications.
There is a well-known maxim in software engineering "Premature optimization is the root of all evil" , it means that trying to optimize code before it's necessary can lead to wasted time and effort, and may even make the code more complex and harder to maintain.
Starting with a monolithic application is a valid approach for building simple applications with a small user base. Deploying a monolith on a hyperscaler can provide immediate benefits such as scalability, high availability, and reduced maintenance costs.
There are plenty of famous examples of huge applications that started as very simple and tiny monoliths, probably one of the most well know example is the origins of Google and their first server made of Legos but also many of the SAP SaaS applications like Concur started as a simple monolith.
In this initial monolithic phase, the front-end layer, application layer, and database layer all run on the same server.

Let’s say you want to scale up to 1000 users... A simple approach would be to split the different layers of ourmonolith into different VMs or containers moving towards a 3-tier architecture.
This will allow you to scale vertically (a.k.a scale-up) each layer independently and allocate resources where they are needed most, while keeping costs under control. For a startup company using open source software maybe it’s not so relevant but for enterprise software, this is particularly important since it is often licensed by cores, and dedicating too many cores can result in overspending.
Hyperscalers offer various types of virtual machines (VMs) based on your computing requirements, such as general purpose, compute-optimized, memory-optimized, and storage-optimized. This allows you to tailor your resource allocation even further for each layer of your application.
At this early stage, relational databases still offer several advantages and are a sufficient solution compared to other more specialized database types like hierarchical, key-value or document databases (also known as NoSQL - Not Only SQL). While these specialized databases have their own advantages, they may not provide the flexibility required for the current needs of the application.
This is particularly important for enterprise software, such as an ERP, where leveraging the ACID principles of relational databases is crucial to ensuring data consistency.

Merely scaling up the different layers will not suffice as current hardware performance does not scale linearly. Moreover, application servers typically cannot take advantage of extremely large servers/VMs, and the majority of applications will offer better performance/price ratios on smaller VMs or commodity Intel/AMD 2-socket servers
In this case, a scale-out approach for the application layer is the next step, which involves adding more VMs or containers instead of increasing the size of the existing ones.
A desirable collateral effect of additional application servers is that it improves the reliability of your application by eliminating a Single Point of Failure (SPOF). However, this improvement comes at a cost. You will need a Load Balancer to distribute the workload among multiple application servers.
There are mainly three types of load balancers, depending on the OSI Network level they filter (Layer 3, Layer 4 or Layer 7). At this stage, we need an Application Load Balancer (Layer 7) to route all the application traffic (HTTP) and act as a reverse proxy.
Some popular choices for Application Load Balancers are Azure FrontDoor, Amazon Elastic LB, NGINX, and SAP WebDispatcher (which we usually use at SAP).
if you are still looking for scalability, the first critical decision yo will need to take as an architect is which type of application you are going to design: Stateless vs Stateful.
Stateless applications are flexible, scalable, and easy to maintain. However, managing sessions and implementing complex business logic can be complex. In addition, they have limited options for data sharing and transactionality since any necessary data or state cannot be stored on the application server and must be stored elsewhere, typically at the database level.
On the other hand, stateful applications can implement complex business logic and transactional processes, but require more resources, session management, and have limited caching options. They are also less flexible in terms of architecture and deployment and more difficult to scale.
For quite a long time, Web architects had the perception that scalability required stateless request handlers. Statelessness means that every HTTP request happens in complete isolation, no dependencies with previous requests or sessions. And this idea continue working very well presently with the RESTFul Web Services and containers:
An example of a stateless application could be a Web search on a Web search engine like Google or Bing. Each search is independent of any other previous search from the same user, and there is no context to be stored.
On the other hand, stateful applications are better for implementing complex business requirements that require transactional processing. Such applications involve multiple steps that must be completed, and if there is a failure at any point in this process chain, the entire transaction must be gracefully reverted.
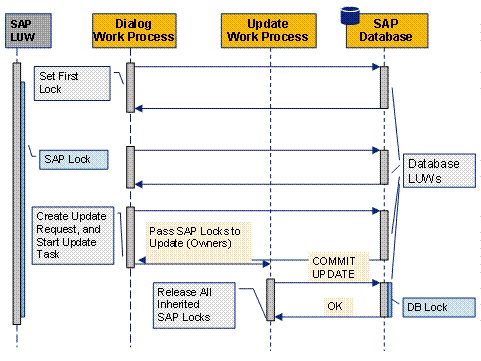
Scaling stateful applications, particularly complex ERP systems, can pose significant challenges. However, SAP applications servers despite being stateful have demonstrated the ability to scale effectively due to the implementation of the Logical Unit of Work (LUW) concept and asynchronous updates. The SAP processes may involve multiple steps, locks, and temporary data storage in various buffers and tables. Asynchronous update processes are used to persist data into the database, involving multiple database transactions to complete the SAP process.
Stateless applications offer much better scalability, but implementing them requires significant design efforts to divide business processes into simple logic blocks that can be managed independently in complete isolation.
Being stateless means that any data or state that needs to be stored cannot be stored on the application server; it must be stored elsewhere, typically in a database. However, relational databases do not scale well and introduce high latency in stateless applications if every data or state must be temporarily stored at the database level.
The solution is simple, use a cache to minimize contention at the database level.
These are just a few examples of the many types of caching patterns. The choice of caching strategy depends on the specific requirements of the application and the underlying infrastructure:
As an example, Write-Back cache improves performance by reducing database writes, as it involves writing data only to the cache and then asynchronously to the database. By the way, this approach is quite similar to the approach used by SAP with their asynchronous update.
Another popular approach is to use the cache-Aside pattern. This pattern involves fetching data from the cache when requested, and if the data is not found in the cache, it is fetched from the database, and then stored in the cache for subsequent requests.
A better approach could be to use REDIS to decouple this requirement to an external cache and use efficient data structures like "Sorted Set" and use commands like ZADD, ZINCRBY, and ZRANGE to store the leader board data structure in memory and manipulate it.
Another popular use case is to use REDIS to store User sessions and User preferences for your stateless web application using HashSets:
A Content Delivery Network (CDN) is a geographically distributed network of servers that work together to provide faster and more reliable delivery of content over the internet.
CDNs store cached versions of static content, such as images, videos, and documents, in multiple locations around the world, so that users can access them from a server that is geographically closer to them. This reduces the latency and improves the speed of content delivery, especially for users who are located far away from the origin server.
CDNs also help to reduce the load on the origin server by distributing the traffic across multiple edge servers. Some examples of popular CDNs include Azure CDN, Cloudflare, Akamai, and Amazon CloudFront.
So far, our focus has been on scalability, but it's important to consider factors like resilience and availability when designing a truly robust cloud application.
Hyperscalers can be especially useful in this regard, as they offer out-of-the-box support of multiple regions and availability zones to provide the desired level of resiliency and scalability. However, traditional relational databases use an Active-Passive replication model which only allow you to implement a Disaster Recovery solution across regions.
Notice how the Azure reference architecture for Multi-Tier Web applications depicted below closely resembles our generic architecture diagram. By utilizing this Azure reference architecture, you can easily implement resilient cloud applications that offer high availability and disaster recovery capabilities across multiple regions
Also, for those of you who are not familiar with SAP architecture, you can check the Azure architecture center. You'll notice that the reference architecture for deploying SAP S/4HANA on Azure mirrors the same patterns:
Until the mid-2000s, achieving 10,000 concurrent users presented a significant engineering challenge. Very few on-premise applications and hardware architectures were capable of managing such workloads.
According to the official SAP Benchmarks, the first SAP system certified to support ~15,000 concurrent users was SAP R/3 3.1H running on Sun Fire 10000 server with Oracle 8i in 1998. This was an early demonstration of the solid foundation of the SAP architecture and its stability and scalability.
Nowadays, building scalable, reliable, and performant large-scale cloud applications to support 10K users (and much more!) can be done out-of-the-box thanks to the distributed infrastructure of the hyperscalers and the techniques described in this blog post.
In our upcoming blog post, we will continue to discuss how to scale applications to reach up to 100K users and explore approaches to overcome the limitations of relational database systems.
Brought to you by the SAP S/4HANA Customer Care and RIG
- Part 1 – Software architecture trends
- Part 2 – How to build a scalable application - From 1 to 10K users (this blog post)
- Part 3 – How to build a scalable application - From 10K to 100.000K users
- Part 4 – How to build a scalable application - Up to Million users
In the previous blog post we performed a very short review of the different software architecture trends. This post will detail how to build a scalable, reliable, and performant large-scale application step-by-step. Starting with a basic architecture, we'll apply patterns to scale it up to millions of users and we will explain how these patterns are also used by SAP to develop our own applications.
How to build a scalable application - From 1 to 10K users
There is a well-known maxim in software engineering "Premature optimization is the root of all evil" , it means that trying to optimize code before it's necessary can lead to wasted time and effort, and may even make the code more complex and harder to maintain.
Version 1.0 - A simple monolithic application
Starting with a monolithic application is a valid approach for building simple applications with a small user base. Deploying a monolith on a hyperscaler can provide immediate benefits such as scalability, high availability, and reduced maintenance costs.
There are plenty of famous examples of huge applications that started as very simple and tiny monoliths, probably one of the most well know example is the origins of Google and their first server made of Legos but also many of the SAP SaaS applications like Concur started as a simple monolith.
In this initial monolithic phase, the front-end layer, application layer, and database layer all run on the same server.
Version 1.1 - Split the different layers (3-Tier architecture)
Let’s say you want to scale up to 1000 users... A simple approach would be to split the different layers of ourmonolith into different VMs or containers moving towards a 3-tier architecture.
This will allow you to scale vertically (a.k.a scale-up) each layer independently and allocate resources where they are needed most, while keeping costs under control. For a startup company using open source software maybe it’s not so relevant but for enterprise software, this is particularly important since it is often licensed by cores, and dedicating too many cores can result in overspending.
Hyperscalers offer various types of virtual machines (VMs) based on your computing requirements, such as general purpose, compute-optimized, memory-optimized, and storage-optimized. This allows you to tailor your resource allocation even further for each layer of your application.
At this early stage, relational databases still offer several advantages and are a sufficient solution compared to other more specialized database types like hierarchical, key-value or document databases (also known as NoSQL - Not Only SQL). While these specialized databases have their own advantages, they may not provide the flexibility required for the current needs of the application.
This is particularly important for enterprise software, such as an ERP, where leveraging the ACID principles of relational databases is crucial to ensuring data consistency.
Version 1.2 - Vertical vs Horizontal scalability
Merely scaling up the different layers will not suffice as current hardware performance does not scale linearly. Moreover, application servers typically cannot take advantage of extremely large servers/VMs, and the majority of applications will offer better performance/price ratios on smaller VMs or commodity Intel/AMD 2-socket servers
In this case, a scale-out approach for the application layer is the next step, which involves adding more VMs or containers instead of increasing the size of the existing ones.
A desirable collateral effect of additional application servers is that it improves the reliability of your application by eliminating a Single Point of Failure (SPOF). However, this improvement comes at a cost. You will need a Load Balancer to distribute the workload among multiple application servers.
There are mainly three types of load balancers, depending on the OSI Network level they filter (Layer 3, Layer 4 or Layer 7). At this stage, we need an Application Load Balancer (Layer 7) to route all the application traffic (HTTP) and act as a reverse proxy.
Some popular choices for Application Load Balancers are Azure FrontDoor, Amazon Elastic LB, NGINX, and SAP WebDispatcher (which we usually use at SAP).

Scale-out and Load Balancing
Version 2.0 - Stateless vs Stateful
if you are still looking for scalability, the first critical decision yo will need to take as an architect is which type of application you are going to design: Stateless vs Stateful.

Stateless vs Stateful
Stateless applications are flexible, scalable, and easy to maintain. However, managing sessions and implementing complex business logic can be complex. In addition, they have limited options for data sharing and transactionality since any necessary data or state cannot be stored on the application server and must be stored elsewhere, typically at the database level.
On the other hand, stateful applications can implement complex business logic and transactional processes, but require more resources, session management, and have limited caching options. They are also less flexible in terms of architecture and deployment and more difficult to scale.
For quite a long time, Web architects had the perception that scalability required stateless request handlers. Statelessness means that every HTTP request happens in complete isolation, no dependencies with previous requests or sessions. And this idea continue working very well presently with the RESTFul Web Services and containers:
- RESTful Web Services relies on stateless, client-server architecture, typically HTTP.
- In the container world, your containers could be immutable.
- But also can be ephemeral/disposable (if there is a problem, destroy the container and create a new one)
An example of a stateless application could be a Web search on a Web search engine like Google or Bing. Each search is independent of any other previous search from the same user, and there is no context to be stored.
On the other hand, stateful applications are better for implementing complex business requirements that require transactional processing. Such applications involve multiple steps that must be completed, and if there is a failure at any point in this process chain, the entire transaction must be gracefully reverted.
Scaling stateful applications, particularly complex ERP systems, can pose significant challenges. However, SAP applications servers despite being stateful have demonstrated the ability to scale effectively due to the implementation of the Logical Unit of Work (LUW) concept and asynchronous updates. The SAP processes may involve multiple steps, locks, and temporary data storage in various buffers and tables. Asynchronous update processes are used to persist data into the database, involving multiple database transactions to complete the SAP process.
Version 2.1 - Cache is King!
Stateless applications offer much better scalability, but implementing them requires significant design efforts to divide business processes into simple logic blocks that can be managed independently in complete isolation.
Being stateless means that any data or state that needs to be stored cannot be stored on the application server; it must be stored elsewhere, typically in a database. However, relational databases do not scale well and introduce high latency in stateless applications if every data or state must be temporarily stored at the database level.
The solution is simple, use a cache to minimize contention at the database level.
These are just a few examples of the many types of caching patterns. The choice of caching strategy depends on the specific requirements of the application and the underlying infrastructure:
- Write-Through Cache
- Cache-Aside
- Write-Back Cache
- Read-Through Cache
- Read-Ahead Cache
- Distributed Cache

Cache patterns
As an example, Write-Back cache improves performance by reducing database writes, as it involves writing data only to the cache and then asynchronously to the database. By the way, this approach is quite similar to the approach used by SAP with their asynchronous update.
Another popular approach is to use the cache-Aside pattern. This pattern involves fetching data from the cache when requested, and if the data is not found in the cache, it is fetched from the database, and then stored in the cache for subsequent requests.
Caches can be implemented with Key-Value stores like Redis, which is an open-source, in-memory data structure store. Redis stores data as key-value pairs and offers various data structures, including strings, hashes, lists, sets, and sorted sets that can be manipulated with specific commands. Unlike relational databases, Redis does not use generic SQL syntax.
Redis is simple, fast and efficient and can be used to make your application stateless acting as a cache to store user sessions, preferences, and other ephemeral data. It can also implement features like leaderboards, visit counters, and job message queues.
Suppose you want to add a leader board for a popular mobile game where users can see the top scores. If you use SQL, you would need to create a leader board table and use SELECT, INSERT and UPDATE statements to update the scores. However, this approach could create a bottleneck at the database level.
A better approach could be to use REDIS to decouple this requirement to an external cache and use efficient data structures like "Sorted Set" and use commands like ZADD, ZINCRBY, and ZRANGE to store the leader board data structure in memory and manipulate it.

REDIS vs relational SQL
Another popular use case is to use REDIS to store User sessions and User preferences for your stateless web application using HashSets:

REDIS - user session store via Hash Sets
Version 2.2 - Use Content Delivery Network (CDN)
A Content Delivery Network (CDN) is a geographically distributed network of servers that work together to provide faster and more reliable delivery of content over the internet.
CDNs store cached versions of static content, such as images, videos, and documents, in multiple locations around the world, so that users can access them from a server that is geographically closer to them. This reduces the latency and improves the speed of content delivery, especially for users who are located far away from the origin server.
CDNs also help to reduce the load on the origin server by distributing the traffic across multiple edge servers. Some examples of popular CDNs include Azure CDN, Cloudflare, Akamai, and Amazon CloudFront.

Offload static content via CDN
So far, our focus has been on scalability, but it's important to consider factors like resilience and availability when designing a truly robust cloud application.
Hyperscalers can be especially useful in this regard, as they offer out-of-the-box support of multiple regions and availability zones to provide the desired level of resiliency and scalability. However, traditional relational databases use an Active-Passive replication model which only allow you to implement a Disaster Recovery solution across regions.
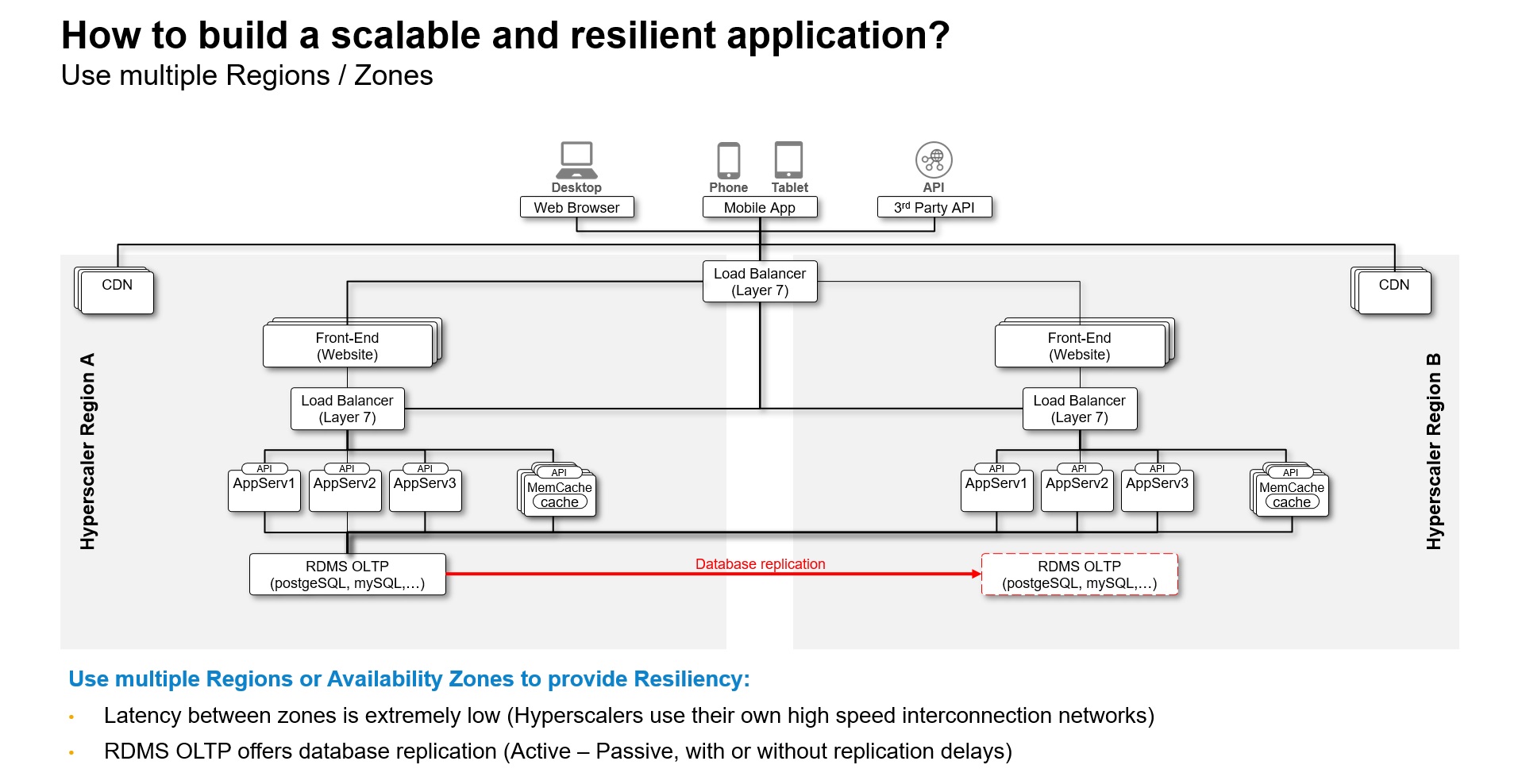
Multi Region support
Notice how the Azure reference architecture for Multi-Tier Web applications depicted below closely resembles our generic architecture diagram. By utilizing this Azure reference architecture, you can easily implement resilient cloud applications that offer high availability and disaster recovery capabilities across multiple regions

Azure - Reference architecture for Multi-Tier Web applications with HA/DR
Also, for those of you who are not familiar with SAP architecture, you can check the Azure architecture center. You'll notice that the reference architecture for deploying SAP S/4HANA on Azure mirrors the same patterns:

Azure - Reference architecture for SAP S/4HANA with HA/DR
Final thoughts and next steps
Until the mid-2000s, achieving 10,000 concurrent users presented a significant engineering challenge. Very few on-premise applications and hardware architectures were capable of managing such workloads.
According to the official SAP Benchmarks, the first SAP system certified to support ~15,000 concurrent users was SAP R/3 3.1H running on Sun Fire 10000 server with Oracle 8i in 1998. This was an early demonstration of the solid foundation of the SAP architecture and its stability and scalability.
Nowadays, building scalable, reliable, and performant large-scale cloud applications to support 10K users (and much more!) can be done out-of-the-box thanks to the distributed infrastructure of the hyperscalers and the techniques described in this blog post.
In our upcoming blog post, we will continue to discuss how to scale applications to reach up to 100K users and explore approaches to overcome the limitations of relational database systems.
Stay tuned for more!
Brought to you by the SAP S/4HANA Customer Care and RIG
- SAP Managed Tags:
- SAP BTP, Kyma runtime,
- SAP S/4HANA
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
271 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
323 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
396 -
Workload Fluctuations
1
Related Content
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.08 in Technology Blogs by SAP
- SAP Document and Reporting Compliance - 'Colombia' - Contingency Process in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 |