
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP HANA Cloud Migration: Common Code Remediations...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-15-2023
12:03 PM
Attention: The content of this blog was not created by SAP. It was written by a non-SAP consultant, Arvind Lachhireddy (HANA Consultant, Pythian) to help your migration journey to the cloud. Therefore, please keep in mind that it might take some more time to get answer for your question in case you leave any to this blog.
The SAP HANA XS Advanced Migration Assistant tool is used to convert XS ''classic'' code and SAP HANA Repository database content (e.g., Calc Views) to the format and syntax for XS Advanced (XSA) and SAP HANA Deployment Infrastructure (HDI). However, several common issues may be encountered when deploying the converted objects to SAP BTP Cloud Foundry and SAP HANA Cloud.
This article describes how to update your converted artifacts to remediate some of these common issues before deploying the converted code into the target environment. In the sections and screenshots below, we are using SAP Business Application Studio (BAS) to make the required code changes.
If your original content in the SAP HANA Repository was organized under multiple packages and sub-packages, you might choose to split the conversion into chunks at the package level when you run the XSA migration utility. This will result in splitting your content across multiple separate HDI containers which will have an impact on data source references in the converted code.
All calculation views are dependent on various other database objects such as tables, views, procedures, functions, and so on. The first thing we need to check is whether the namespace for the calculation view is the same as in the dependent object(s) that have been migrated and deployed.
Here, package1.SchemaName:: is the schema reference generated by the XSA migration utility. Please check on the object name as in the database (along with namespace if configured). If there is a change in the object reference the view will throw an error of missing objects during deployment.
Alternatively, you can use the text editor in BAS to change the reference. Locate the resource URI XML tag and find the package reference. Then change it appropriately according to the namespace (if used).

In addition, if there is any date() function used in the calculation in Calculation Views and Table Functions, those need to be replaced with the daydate() function, since the date() function is not supported in SAP HANA Cloud.
In SAP HANA Cloud, the UPDATE ... FROM <table> SQL syntax is not supported. Instead, the MERGE INTO syntax (added as of SAP HANA 2.0) can be used for any update scenario that was previously implemented using the UPDATE FROM syntax. For more information, see MERGE INTO Statement (Data Manipulation).
In some scenarios, a developer may have chosen to use the TRUNCATE statement to perform a delete of all data in a table or partition (Note: TRUNCATE should be used with caution because it is irreversible and cannot be rolled back if the transaction fails). If the objects you are truncating are in the same HDI container as the procedure, then the TRUNCATE statement will work and no adjustment is needed.
However, if you're using a synonym to reference a table in another HDI container or external schema, then TRUNCATE will not work and will throw an error. So, you will then need to modify your code accordingly.
In this case, if you replace the TRUNCATE statement with the DELETE FROM statement, as shown below, then the deployment will be successful.
NOTE: The DELETE FROM statement can be a reasonable replacement for TRUNCATE on small and mid-sized tables. However, if you have specific reasons for using the TRUNCATE statement and require its use, then you can instead create a procedure within the target HDI container or schema (i.e., where the table is present) to execute the TRUNCATE statement there. Then you can call the custom truncate procedure remotely using a synonym from your container and procedure.
Typically, there are few complications or issues when deploying migrated table functions and scalar functions. However, these objects are often dependent on other objects such as tables, calculation views, and/or procedures. So, you must deploy the dependent objects with the proper namespace referenced in the table function.
In the below example, as we see in calculation views, the function uses a schema reference. This needs to be corrected by referring to the appropriate database object names in the migrated environment to avoid ''unknown object'' errors during deployment
To correct the invalid reference, remove the old (''classic'') package namespace from the object name and replace the object name with the exact object name present in the migrated database.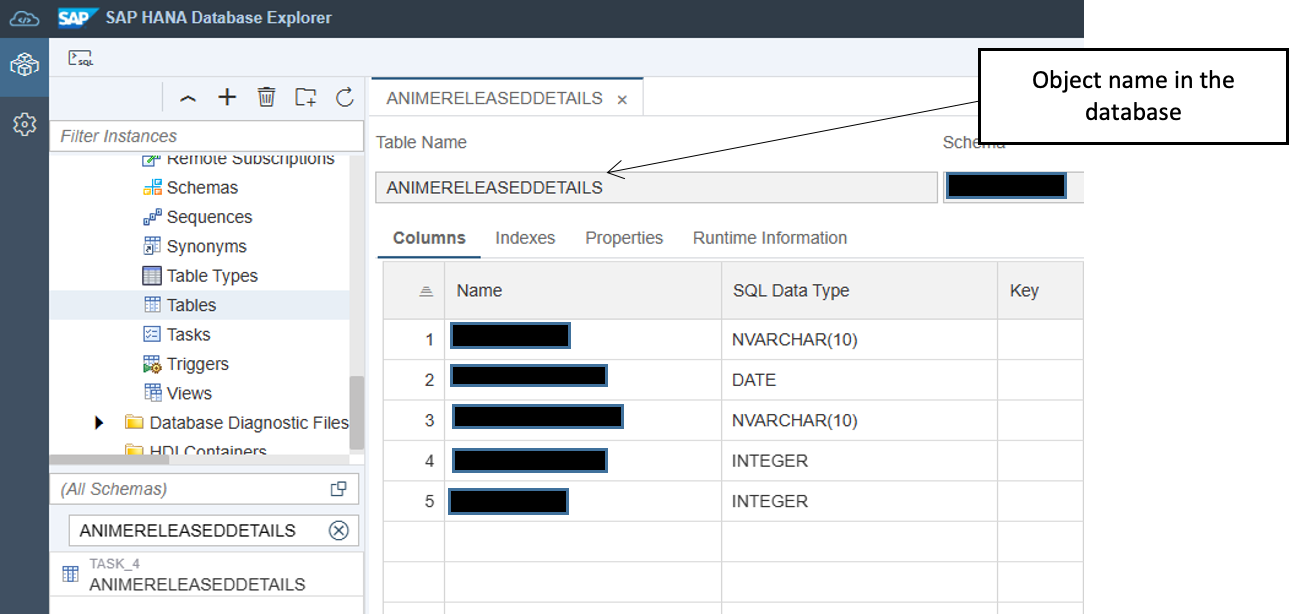
To illustrate the scenario we can see the source and converted codes below.
If the remote source is available but the reptask is not connected to it, this can be an issue with the access privileges. Access has to be granted to the remote source by adding the missing remote source in the grants file and deploying it.
These are just a few tips and hints to help you with the migration of your ''classic'' SAP HANA database content for deployment to SAP HANA Cloud.
Please feel free to leave any comments/questions. It might take some time as this content is not from SAP, but we will do our best to get back to you with accurate and reliable information.
The SAP HANA XS Advanced Migration Assistant tool is used to convert XS ''classic'' code and SAP HANA Repository database content (e.g., Calc Views) to the format and syntax for XS Advanced (XSA) and SAP HANA Deployment Infrastructure (HDI). However, several common issues may be encountered when deploying the converted objects to SAP BTP Cloud Foundry and SAP HANA Cloud.
This article describes how to update your converted artifacts to remediate some of these common issues before deploying the converted code into the target environment. In the sections and screenshots below, we are using SAP Business Application Studio (BAS) to make the required code changes.
1. Calculation Views
If your original content in the SAP HANA Repository was organized under multiple packages and sub-packages, you might choose to split the conversion into chunks at the package level when you run the XSA migration utility. This will result in splitting your content across multiple separate HDI containers which will have an impact on data source references in the converted code.
All calculation views are dependent on various other database objects such as tables, views, procedures, functions, and so on. The first thing we need to check is whether the namespace for the calculation view is the same as in the dependent object(s) that have been migrated and deployed.
Here, package1.SchemaName:: is the schema reference generated by the XSA migration utility. Please check on the object name as in the database (along with namespace if configured). If there is a change in the object reference the view will throw an error of missing objects during deployment.
For changing the schema reference, open the calculation view in the development tool (e.g., BAS, WEB IDE) with the calculation view editor. Select the data source node that needs to change and right-click on the node it gives the options as shown below. Then, choose to replace it with the Data Source option to point to the correct source object in the database.
Changing the package reference in the calculation view editor
Alternatively, you can use the text editor in BAS to change the reference. Locate the resource URI XML tag and find the package reference. Then change it appropriately according to the namespace (if used).
Example of changing the package reference in the code editor
In addition, if there is any date() function used in the calculation in Calculation Views and Table Functions, those need to be replaced with the daydate() function, since the date() function is not supported in SAP HANA Cloud.
Example of changing date() to daydate() function
2. Stored Procedures
UPDATE FROM
In SAP HANA Cloud, the UPDATE ... FROM <table> SQL syntax is not supported. Instead, the MERGE INTO syntax (added as of SAP HANA 2.0) can be used for any update scenario that was previously implemented using the UPDATE FROM syntax. For more information, see MERGE INTO Statement (Data Manipulation). The DML statement in the screenshot above using the UPDATE FROM syntax is not supported in SAP HANA Cloud and will give the error shown below:
The DML statement in the screenshot above using the UPDATE FROM syntax is not supported in SAP HANA Cloud and will give the error shown below: To address this, the UPDATE FROM statement must be replaced by MERGE INTO as shown below.
To address this, the UPDATE FROM statement must be replaced by MERGE INTO as shown below.
TRUNCATE TABLE
In some scenarios, a developer may have chosen to use the TRUNCATE statement to perform a delete of all data in a table or partition (Note: TRUNCATE should be used with caution because it is irreversible and cannot be rolled back if the transaction fails). If the objects you are truncating are in the same HDI container as the procedure, then the TRUNCATE statement will work and no adjustment is needed.
However, if you're using a synonym to reference a table in another HDI container or external schema, then TRUNCATE will not work and will throw an error. So, you will then need to modify your code accordingly.
The simplest solution is to replace the TRUNCATE statement with a DELETE FROM statement. See the below example.
Original code
Here ''EMPSALARY'' is an object (table) from a synonym reference. The original code using TRUNCATE will return an error on deployment as illustrated below:

Modified code
In this case, if you replace the TRUNCATE statement with the DELETE FROM statement, as shown below, then the deployment will be successful.
NOTE: The DELETE FROM statement can be a reasonable replacement for TRUNCATE on small and mid-sized tables. However, if you have specific reasons for using the TRUNCATE statement and require its use, then you can instead create a procedure within the target HDI container or schema (i.e., where the table is present) to execute the TRUNCATE statement there. Then you can call the custom truncate procedure remotely using a synonym from your container and procedure.
3. Functions
Typically, there are few complications or issues when deploying migrated table functions and scalar functions. However, these objects are often dependent on other objects such as tables, calculation views, and/or procedures. So, you must deploy the dependent objects with the proper namespace referenced in the table function.
In the below example, as we see in calculation views, the function uses a schema reference. This needs to be corrected by referring to the appropriate database object names in the migrated environment to avoid ''unknown object'' errors during deployment
Example showing schema reference in the file
To correct the invalid reference, remove the old (''classic'') package namespace from the object name and replace the object name with the exact object name present in the migrated database.
Object name in the database
4. SDI Flowgraphs
In some scenarios, the SDI flowgraphs converted by the XSA Migration Assistant may have incorrect mappings. We can make changes in the mappings of the flowgraphs by using the SDI flowgraph editor. After importing the converted code into your project in the development tool (e.g., BAS, WEB IDE), open the file in the flowgraph editor.
To illustrate the scenario we can see the source and converted codes below.
XSC Flowgraph
 Attribute mapping in the filter node of flowgraph is with double quotes ''Filter5_Input''.''User Name''. But the converted code from the XSA Migration Assistant tool sometimes misses this. The filter node is not available in SAP HANA Cloud so the filter node is converted to a projection and sometimes the mappings come without any reference to the node and without double quotes like below.
Attribute mapping in the filter node of flowgraph is with double quotes ''Filter5_Input''.''User Name''. But the converted code from the XSA Migration Assistant tool sometimes misses this. The filter node is not available in SAP HANA Cloud so the filter node is converted to a projection and sometimes the mappings come without any reference to the node and without double quotes like below.
Available nodes in a Flowgraph - HANA Cloud

Missing references in XSA converted code
This needs to be corrected manually and redeployed. This scenario might not error while you deploy the code but while executing the flowgraphs the missing mapping reference causes errors. Remapping the columns with the correct reference and quoting will rectify this issue.
Manually corrected code
5. Replication Tasks
Replication tasks are tightly coupled with remote sources such that the remote source must be properly configured and referenced in the target environment. The replication tasks converted using the XSA Migration Assistant tool can be imported into the development tool (e.g., BAS, WEB IDE). The SDI Reptask editor gives the details of the configuration i.e., the associated remote source, table details, replication behavior, etc. If the reptask is not connected to the remote source then you first need to check if the remote source is available in the database and if the required privileges have been assigned (e.g., in the grants file).
The remote source in the database
If the remote source is available but the reptask is not connected to it, this can be an issue with the access privileges. Access has to be granted to the remote source by adding the missing remote source in the grants file and deploying it.

Grants file example
Once the grants file is deployed then check the remote source in the reptask file. If the remote source connection is available as shown, deploy the reptask file.
During deployment, it will generate a procedure that needs to be executed for the initial load and activation of the Replication task for capturing active changes (depending on the replication behavior configured in the replication task).
6. Conclusion
These are just a few tips and hints to help you with the migration of your ''classic'' SAP HANA database content for deployment to SAP HANA Cloud.
Please feel free to leave any comments/questions. It might take some time as this content is not from SAP, but we will do our best to get back to you with accurate and reliable information.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA Cloud, SAP HANA database
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
295 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- BW Bridge: migration of calculation view, are there any news? in Technology Q&A
- Cloud Integration: Manually Encrypt/Decrypt XML payload based on XML-Enc Standard in Technology Blogs by SAP
- A Tale of Fusion Development with SAP Build: The Conclusion in Technology Blogs by SAP
- Sierra’s InFocus: SAP Datasphere Readiness Assessment in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 36 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |