
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- SAP CPI: CI/CD from from zero to hero
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
nunomcpereira
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-02-2023
8:31 PM
The purpose of these blog series is to describe possible approaches for SAP Cloud Integration (aka CPI) CI/CD addressing some of what I consider pitfalls or limitations. If you're aware of SAP standard internal mechanisms to deal with it just let me know. Each of the topics below will be linked when the blog part is available. After each section I try to highlight the motivation and value added from each feature/development done.
Just a disclaimer, each observation I make on these series is my personal opinion and of course is very debatable, so I encourage you to comment on alternatives or possible issues with the approaches I took.
When I first joined my current employer, we we're just starting to use SAP CPI, so I had the chance to influence, propose and implement some ideas in regards to CI/CD and also to establish some ground for future processes. Nowadays we have around 400 integration flows running so there's definitely some governance needed.
Some context information:
I'll now present how we addressed the following topics:
Each one of these areas will be an in-depth explanation with most of the steps to help you creating a similar platform. When we started this, project piper was still on early stages, from my understanding it would only run on linux and we had a windows VM. There was always the option to use Docker, but using Docker totally free would mean run it without Docker Desktop which we assumed (perhaps wrongly) that would be a big effort to configure it so despite we use some of the same platforms as used in piper (like Jenkins, we're not using the official project piper implementation)
We started this initiative as kind of a PoC to play a bit with CI/CD and see how could we benefit from it, therefore we tried to stick to open source and no costs whenever possible. Crucible came later to the game and we decided that the licensing cost was totally worth it so we ordered it.
Special thanks to antonio_jorge_vaz, who contributed to this solution on most of these topics.
Cloud integration is a great tool that allows you to create integrations using a simple UI. It has the concept of versions, but those versions are freely created by developers using freely naming convention. While this is great in regards to flexibility is not that great in regards to consistency since each developer will follow their own version convention. We decided to use the semver model but even then, there's no impediment for a developer to create the same semver all over again, or even worse which is creating outdated semver versioning creating a big mess in the end. On top of that, all of your code is only "saved" on SAP servers, so if you delete your integration suite tenant by mistake, there's no way for you to recover any of your work (trust me, I've been through that...).
Our landscape has currently 4 environments (DEV, TEST, PREPROD and PROD).
So since my early days of joining that I wanted to have backups for our binaries (packages) as well as for the iflows source code. We've asked for a new on premise server (windows) and we installed on this server:
Idea was to have a pipeline scheduled on Jenkins and synchronize on a daily basis (per environment). The code uses CPI API to retrieve all packages binaries and stores them into git. What we realized then was that if a package has iflows in Draft status, you can't download the full package, so we went to download every binary possible for the package (at the time we developed only value mappings and integration flows were supported).
As the end result, all our CPI binaries would be stored as zip files inside git. The advantage is that if you need to restore it would be quite easy to import the zip files again. The disadvantage is that for source control itself and history tracking of changes, binary files are not optimal for analysis. Therefore we thought that it would be interesting to have not a single backup pipeline for everything but also a pipeline per cpi package running package specific checks and logic.
Next step was in regards to security: we wanted to be able to versioning the keystore and security materials, so using CPI API we were able to download all the certificates from all environments and also to synchronize all our security materials with a keepass file. We then "gitted" all of these on our binaries repository per environment.
In order to save some disk space we only keep track of the latest 5 builds. We run it daily at 2 AM. For confidentiality reasons I changed our internal urls into dummy one, but you get the idea
We're basically instructing Jenkins to execute file admin_SAPCPIBackup_DEV that is located in a Jenkins repository stored inside git. This file contains the instructions to use a coded pipeline with multiple stages.
We based our code on the following basic recipe from axel.albrecht (@axel.albrecht)
Link to the complete blog from him here
Easy restore in case we lose an instance
Next logical step would be to find a way to automatically create Jenkins pipelines for each package and make them execute similar checks. Each of our pipeline would reference a git repository and their respective JenkinsFile inside it containing the logic to run for that package..
So idea of this job was to pick all cpi package list and check if a new jenkinsFile would need to be created on our git and a respective jenkins pipeline with the same name of the cpi package.
<Package specific pipeline>
All our generated jenkinsFile followed the same structure which was:
The Jenkinsfile's were generated based on a template containing placeholders that was just replaced when the synchronization job is running. In case the template change since we want to introduce a new functionality, all we need to do is to delete all the jenkins file from git and this job would be able to regenerate them and commit them to git again.
if some developer started working on a new cpi package, without he even noticing, there is a job collecting the source code and binaries for his new cpi package and starting to store this on our git repository. If for instance the source code was not following our development guidelines the responsible would be notified to check it.
You may realize that for each package we identify a package responsible. This is needed since we want to have the concept of ownership and responsibility. Ultimately it's the goal of the team to make sure all packages are ok, but if we have one package responsible it would help a lot.
The package responsible is the person that receives emails notifications in case the package wasn't built successfully. How do we calculate it?
We get the most recent date from the following evaluations:
For each of the dates above there's a user associated with it. We consider the user as the package responsible. We implemented a delegation table by package regular expression and considering begin dates and end dates so that we could accommodate absences from the package responsible.
Another failsafe mechanism we did was that if a package fails for 10 consecutive days, we send the email not only to the package responsible but we cc the whole team DL as well so that someone can act on it.
We always have a main contact per package. It can be that this is not the most familiar person with the package but at least is a person who lastly interacted with it.
In this first part, we introduced the CI/CD tools we used, we highlighted the importance of using backups, how to get these backups, what quality measures are we enforcing to all CPI packages, what is currently being documented and how do we calculate a package responsible. On the next part we'll discuss in more detail what we did in regards to quality control
I would invite you to share some feedback or thoughts on the comments sections. You can always get more information about cloud integration on the topic page for the product.
Just a disclaimer, each observation I make on these series is my personal opinion and of course is very debatable, so I encourage you to comment on alternatives or possible issues with the approaches I took.
When I first joined my current employer, we we're just starting to use SAP CPI, so I had the chance to influence, propose and implement some ideas in regards to CI/CD and also to establish some ground for future processes. Nowadays we have around 400 integration flows running so there's definitely some governance needed.
Some context information:
- Our company uses 4 system landscape (dev, test, preprod and prod)
- We use cloud foundry instances only (no neo)
I'll now present how we addressed the following topics:
- Backup Binaries and Source Code (explained in this page)
- Code inspection and quality control
- Release management
- Certificates expiration
- Automated Testing
- Documentation
- Code Review
Each one of these areas will be an in-depth explanation with most of the steps to help you creating a similar platform. When we started this, project piper was still on early stages, from my understanding it would only run on linux and we had a windows VM. There was always the option to use Docker, but using Docker totally free would mean run it without Docker Desktop which we assumed (perhaps wrongly) that would be a big effort to configure it so despite we use some of the same platforms as used in piper (like Jenkins, we're not using the official project piper implementation)
We started this initiative as kind of a PoC to play a bit with CI/CD and see how could we benefit from it, therefore we tried to stick to open source and no costs whenever possible. Crucible came later to the game and we decided that the licensing cost was totally worth it so we ordered it.
- Jenkins - We can think of Jenkins as just a scheduler, a trigger for our automations
- Gitea - Our source control repository on premise. If you don't have any issues to store your code on cloud, maybe github is a better option for you since it supports github actions
- Crucible - A tool from Atlassian to allow you to create and implement code reviews on your source code
Special thanks to antonio_jorge_vaz, who contributed to this solution on most of these topics.
Backup Binaries and Source Code
Cloud integration is a great tool that allows you to create integrations using a simple UI. It has the concept of versions, but those versions are freely created by developers using freely naming convention. While this is great in regards to flexibility is not that great in regards to consistency since each developer will follow their own version convention. We decided to use the semver model but even then, there's no impediment for a developer to create the same semver all over again, or even worse which is creating outdated semver versioning creating a big mess in the end. On top of that, all of your code is only "saved" on SAP servers, so if you delete your integration suite tenant by mistake, there's no way for you to recover any of your work (trust me, I've been through that...).
Our landscape has currently 4 environments (DEV, TEST, PREPROD and PROD).
So since my early days of joining that I wanted to have backups for our binaries (packages) as well as for the iflows source code. We've asked for a new on premise server (windows) and we installed on this server:
- Jenkins
- Gitea
- Crucible

Main general architecture
Binaries Backup
Idea was to have a pipeline scheduled on Jenkins and synchronize on a daily basis (per environment). The code uses CPI API to retrieve all packages binaries and stores them into git. What we realized then was that if a package has iflows in Draft status, you can't download the full package, so we went to download every binary possible for the package (at the time we developed only value mappings and integration flows were supported).
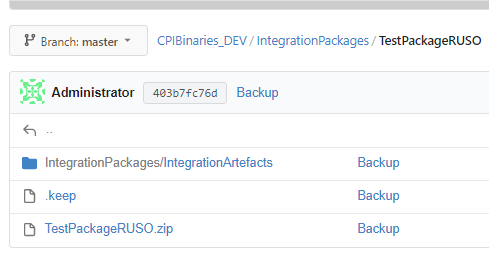
Package binary file stored on git as a zip file

Iflows and value mappings zip files inside the package
As the end result, all our CPI binaries would be stored as zip files inside git. The advantage is that if you need to restore it would be quite easy to import the zip files again. The disadvantage is that for source control itself and history tracking of changes, binary files are not optimal for analysis. Therefore we thought that it would be interesting to have not a single backup pipeline for everything but also a pipeline per cpi package running package specific checks and logic.
Next step was in regards to security: we wanted to be able to versioning the keystore and security materials, so using CPI API we were able to download all the certificates from all environments and also to synchronize all our security materials with a keepass file. We then "gitted" all of these on our binaries repository per environment.
Some technical details
In order to save some disk space we only keep track of the latest 5 builds. We run it daily at 2 AM. For confidentiality reasons I changed our internal urls into dummy one, but you get the idea
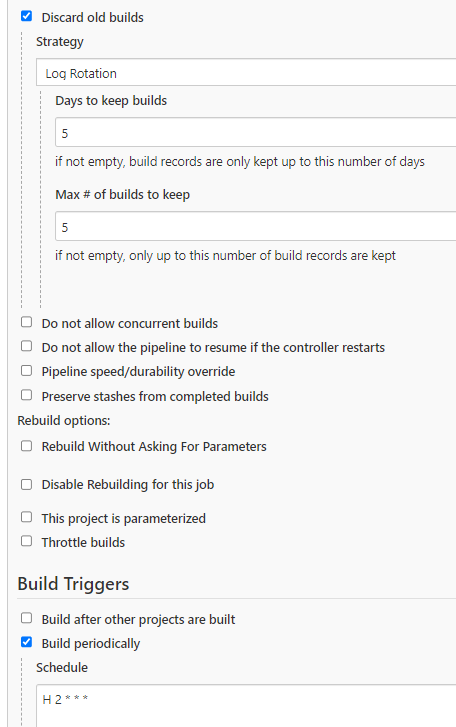
Jenkins pipeline details

Jenkins pipeline details
We're basically instructing Jenkins to execute file admin_SAPCPIBackup_DEV that is located in a Jenkins repository stored inside git. This file contains the instructions to use a coded pipeline with multiple stages.
import groovy.json.JsonSlurper
def GitBranch = "master"
def GitComment = "Backup"
def GitFolder = "IntegrationPackages"
def CertificatesFolder = "Keystore"
def packageResponsible = "testdummy@domain.com"
pipeline {
agent any
options {
skipDefaultCheckout()
}
stages {
stage('Download integration artefacts and store it in git for CPI DEV') {
steps {
script {
We based our code on the following basic recipe from axel.albrecht (@axel.albrecht)
Link to the complete blog from him here
Value added
Easy restore in case we lose an instance
Synchronization of packages to pipelines
Next logical step would be to find a way to automatically create Jenkins pipelines for each package and make them execute similar checks. Each of our pipeline would reference a git repository and their respective JenkinsFile inside it containing the logic to run for that package..
So idea of this job was to pick all cpi package list and check if a new jenkinsFile would need to be created on our git and a respective jenkins pipeline with the same name of the cpi package.

Sync all packages on Cloud Integration creating a pipeline per package
<Package specific pipeline>

Pipeline configuration retrieving the code to execute from a git repository
All our generated jenkinsFile followed the same structure which was:
- Backing up the source code for that particular cpi package into a git repository. If no git repository was yet created, a new one was created using gitea API
- Create a crucible repository, connect it to the gitea git repository, create a crucible project and a crucible code review to make sure we keep track of unreviewed files
- Crawl through the source iflows trying to find MessageMappings. When found, submit them to an extraction tool which would generate a cool html report with syntax coloring for mappings done there (this would serve for documentation purposes)

- Automatic markdown generation for git repository containing all package information, all iflows there, description per iflows, screenshot of the iflow as well as the message mapping documentation table. Example:

- Running CPI Lint (discussed in detail later)

- Automatically running unit testing for regular groovy files of your iflows, xspec for xslt unit testing as well as unit testing for message mappings (discussed in detail later)

- Email notifications to the package responsible in case of any issues found on any steps above
The Jenkinsfile's were generated based on a template containing placeholders that was just replaced when the synchronization job is running. In case the template change since we want to introduce a new functionality, all we need to do is to delete all the jenkins file from git and this job would be able to regenerate them and commit them to git again.
Value added
if some developer started working on a new cpi package, without he even noticing, there is a job collecting the source code and binaries for his new cpi package and starting to store this on our git repository. If for instance the source code was not following our development guidelines the responsible would be notified to check it.
Package Responsible
You may realize that for each package we identify a package responsible. This is needed since we want to have the concept of ownership and responsibility. Ultimately it's the goal of the team to make sure all packages are ok, but if we have one package responsible it would help a lot.
The package responsible is the person that receives emails notifications in case the package wasn't built successfully. How do we calculate it?
We get the most recent date from the following evaluations:
- Last modified date on the package level
- Last deploy made on one of the artifacts of the package (iflow, value mappings, ...)
- Package creation date
For each of the dates above there's a user associated with it. We consider the user as the package responsible. We implemented a delegation table by package regular expression and considering begin dates and end dates so that we could accommodate absences from the package responsible.
Another failsafe mechanism we did was that if a package fails for 10 consecutive days, we send the email not only to the package responsible but we cc the whole team DL as well so that someone can act on it.
Value added
We always have a main contact per package. It can be that this is not the most familiar person with the package but at least is a person who lastly interacted with it.
Summary
In this first part, we introduced the CI/CD tools we used, we highlighted the importance of using backups, how to get these backups, what quality measures are we enforcing to all CPI packages, what is currently being documented and how do we calculate a package responsible. On the next part we'll discuss in more detail what we did in regards to quality control
I would invite you to share some feedback or thoughts on the comments sections. You can always get more information about cloud integration on the topic page for the product.
- SAP Managed Tags:
- SAP Integration Suite,
- Cloud Integration,
- SAP BTP, Cloud Foundry runtime and environment
17 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
12 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
3 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
General Splitter
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
GraphQL
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
2 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
21 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
6 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
14 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Elevate your performance with the synergy of data, AI, & Strategic planning with SAP Solutions in Technology Blogs by Members
- Introducing UI5 linter in Technology Blogs by SAP
- Demystifying CI/CD Pipelines for SAP Cloud Integration Projects in Technology Blogs by Members
- Not Jewel, Juul, Jules but Joule in Technology Blogs by SAP
- Process modeling lifecycle – a comprehensive view derived from multiple case studies in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 5 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 |