
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Copying/Migrating data in SAP HANA Cloud
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-26-2023
1:33 PM
Introduction
This blogpost is part of a larger series, please visit the overview post by Volker Saggau here:
At the end of this you will be able to create a copy from a cloud foundry managed SAP HANA Cloud system. This will include:
- Full modeling capabilties in the new copy
- Cloud foundry managed (visible in BTP)
- Easily update the new system with data using cloud existing cloud storage capabilties
I'll make use of the SAP HANA Cloud: Federation template scenario i described here:

Overview

What i will cover is the green and the purple path in the above picture that includes:
- Exporting catalog data from the Production System into a Cloud Storage (AWS in this case) using SQL EXPORT API
- Pre-HDI-Deployment: Create non-hdi managed artifacts (Users [Remote, SAC, ...], Roles, privileges, remote sources(optional)
- Recreate Cloud Foundry services that the applications consume
- HDI-Deployment: Deploy HDI container without data to the database
- Post-HDI-Deployment: Assign HDI-Container generated roles to roles created in Pre-HDI-Deployment
- [SAC]: Create connection to PreProd system
- [SAC]: Create/Copy Story from production to preproduction
- Import data from the cloud storage into the system.
However once the PreProduction system is setup (runtime & designtime objects) the process simply includes:
- Export catalog data from production into a cloud storage that is in the same region as your database
- Import catalog data from cloud storage into the pre-production database
- Deploy the latest productive version of the code
Exporting catalog data from the production system into a cloud storage on SAP BTP (AWS in this case) using SQL EXPORT API
In the code below you can see the sql queries i executed against the productionDB, just to show you which tables where inside the db schema JOERMUNGANDR_DATA_FOUNDATION. These objects will be exported next into an S3 bucket
--Production system (export)
--show the current table content of schema 'JOERMUNGANDR_DATA_FOUNDATION'
select * from m_tables where schema_name = 'JOERMUNGANDR_DATA_FOUNDATION';
-- SQL Result
/**
SCHEMA_NAME; TABLE_NAME; RECORD_COUNT; TABLE_SIZE
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_MIDGARD_SERPENT; 5000000; 10928
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_NORTHWIND; 91; 10992
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_ORDERS; 1000980; 1480444
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_ORDER_DETAILS; 2155; 87796
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_PRODUCTS; 77; 10976
JOERMUNGANDR_DATA_FOUNDATION; dl.df.joermungandr.data::TG_SALES_BY_CATEGORIES;77; 10880
**/
Add Object Store to your BTP account
Object Store documentation here.
Go into your BTP subaccount and space where you want to create the Object Store.
( thats the Database Space for me, as we split the database for Development / Quality / Production away from the app development spaces)
And select "Service Marketplace" where you search for "Object Store"
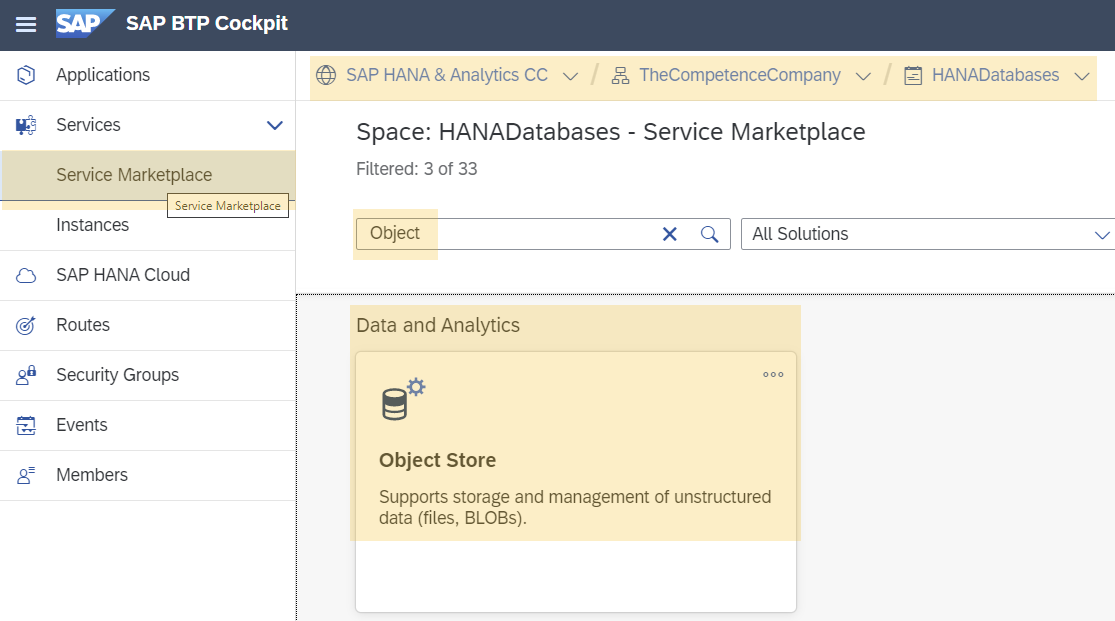
Create a new Instance/Subscription, below is what i used for this demo.

Upon creation of the Object Store you will be able to see important credentials necessary for logging into your storage.
Check the contents of the Object Store, as mentioned in my case it's an S3 bucket and it is empty.
Once we execute the export command, excluding remote data, the S3 bucket will be filled.
-- executed in production with a data admin user
EXPORT ALL HAVING
schema_name = 'JOERMUNGANDR_DATA_FOUNDATION' AND
object_type = 'TABLE' AND -- only of type table e.g. no views
object_name like 'dl.df.joermungandr.data%' AND -- export only objects within this namespace
object_name not like '%dl.df.joermungandr.data::VT%' -- exclude virtual tables
as binary raw -- binary type as supposed to be the fastest for large exports
INTO 's3-<region>://<access_key>:<secret_key>@<bucket_name>/<object_id>'
no remote data -- this will not fetch remote data (virtual table contents) into the export
;CAUTION: If the "no remote data" syntax is not added, the export command would request ALL source data from virtual tables which can lead to massive amounts of data.
NOTE: If this sql query fails with an SSL_VALIDATION error, make sure that the certifcates are added to the HANADB and to a certificate collection, read more here.

S3 bucket after executing the export query in production
And inside the folder you'll see the catalog export structure

And inside the index and schema folder you'll find the table data
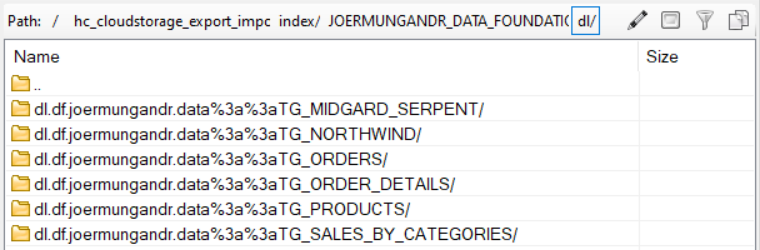
But as of now there is no place to import this data into, so head into your Cloud Foundry BTP account and create a CF space & hana cloud database.
Pre-HDI-Deployment: Create non-hdi managed artifacts (Users [Remote, SAC, ...], Roles, privileges, remote sources(optional)
Assuming you created the new CF space and DB let's continue in it.
As we want to access the data from SAP Analytics cloud dashboard, we'll need a technical user to connect to preproduction database.
That reporting user will also need privileges to consume the objects inside the reporting HDI container, which we cannot assign now as they are only existing Post-HDI deployment.
--Execute in PreProd
-------------------------------------------------------
CREATE USER SAC_PREPROD password ********;
-- Empty Shell -> Read role grants access to all scenario HDI containers, but will be granted the rights --- only post hdi-container deployment
CREATE ROLE EDEN_REPORTING_READ;
GRANT EDEN_REPORTING_READ to SAC_PREPROD;Recreate Cloud Foundry services that the applications consume
Services necessary for the application can be seen and obtained from the Business Application Studio from the SAP HANA Projects tab or from the mta.yaml file.
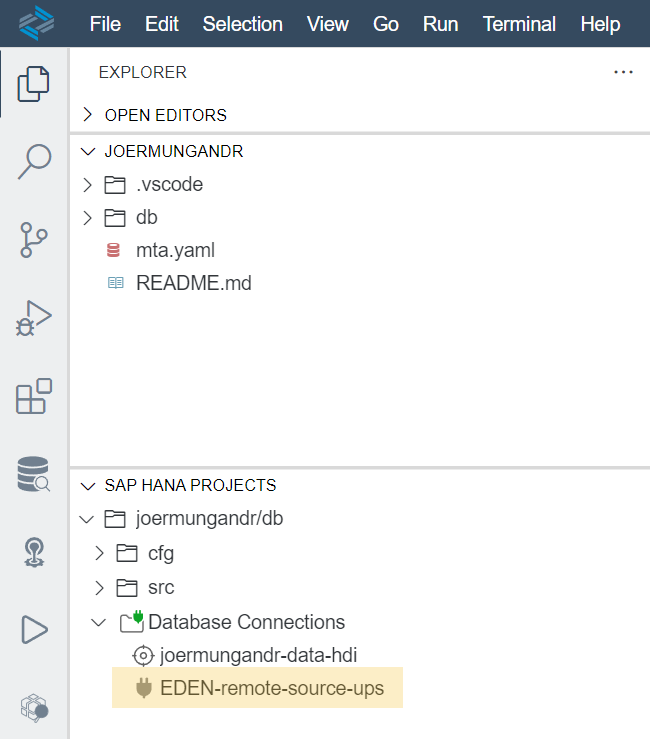
In order to re-create the cloud foundry services you can simply go into your BTP account and obtain the credentials for the services from there.
Credentials for the EDEN-remote-source-ups service obtained from source system

{
"certificate": "-----BEGIN CERTIFICATE-----\n<hash>\n-----END CERTIFICATE-----",
"driver": "com.sap.db.jdbc.Driver",
"host": "***.hana.canary-eu10.hanacloud.ondemand.com",
"password": "************",
"port": "443",
"tags": [
"hana"
],
"user": "eden_remote_grantor"
}For the new ups service in preproduction replace host and password with relevant preproduction values.
Here is the snippet to create the eden_remote_grantor user used by the user-provided-services (EDEN-remote-source-ups).
The *_REMOTE_SOURCE roles are used in case you need the ups to be able to access the remote systems / sources and are only existing post-hdi deployment.
-- execute in preprod
-------------------------------------------------------
CREATE USER EDEN_REMOTE_GRANTOR PASSWORD "*********";
-- Role eden_remote_read will be granted all relevant remote source privileged roles (SDI/SDA/OData) to access replication source systems
create role eden_remote_read;
grant eden_remote_read to EDEN_REMOTE_GRANTOR;
-- Shangri-la roles
-- Create Roles for Remote Source
CREATE ROLE SHANGRILA_REMOTE_SOURCE;
CREATE ROLE SHANGRILA_REMOTE_SOURCE_GRANTABLE;
grant SHANGRILA_REMOTE_SOURCE to eden_remote_read with admin option;
grant SHANGRILA_REMOTE_SOURCE_GRANTABLE to eden_remote_read with admin option;
-- Joermungandr roles
CREATE ROLE JOERMUNGANDR_REMOTE_SOURCE;
CREATE ROLE JOERMUNGANDR_REMOTE_SOURCE_GRANTABLE;
grant JOERMUNGANDR_REMOTE_SOURCE to eden_remote_read with admin option;
grant JOERMUNGANDR_REMOTE_SOURCE_GRANTABLE to eden_remote_read with admin option;
-------------------------------------------------------This blog post does not include remote source usage, as we import, export the data using cloud storage, but you could use the above template to assign the privileges to the remote_grantor_user.
HDI-Deployment: Deploy HDI container without data to the database
Since the reporting layer EDEN-Reporting has objects (calculation views) that use synonyms that point to the data foundation HDI containers we need to deploy the data foundation HDI containers first.

HDI Deployment Order
For this example i deployed the Joermungandr MTAR first.(1a)
Joermungandr - empty hdi container deployment
Even when initial MTAR deployments fail the HDI container will be created. In case you need to adjust more then just one ore two files it's much quicker to connect to the created container in BAS and fix/ deploy from there.
Which is visible in the BTP Space view:

Please ignore eden-reporting-hdi in the screenshot, it will not be there if you initially deploy the data foundations.
But you should have EDEN-remote-source-ups and joemungandr-data-hdi after the MTAR deployment.
Going into the BAS workspace after MTAR deployment should give you something like this:

BAS: Joermungandr project view
In case you have artifacts using remote objects (Virtual Tables, Replication tasks) you need to have the remote source used in these remote objects already created & configured prior to deployment or the deployments will fail.
If you need to exclude a artifact simply change it's extentions to .txt and it will be ignored during deployment.
For the EDEN-Reporting layer i followed the same steps:
- Deploy container MTAR (to get an empty shell container)
- Go into BAS and connect the HDI container
- Connect services and check deployment
- Remove deployment errors (most often excluding files from deployment which require remote data)
Post-HDI-Deployment: Assign HDI-Container generated roles to roles created in Pre-HDI-Deployment
The manually created role EDEN_REPORTING_READ can now be assigned the hdi generated roles
- dl.df.joermungandr.auth::Read
- dl.reporting.auth::Read
after HDI container deployment.
Testing database setup
Go into your Database Explorer and connect the newly created HDI containers
- Joermungandr
- Eden-Reporting
For our reporting case we need the roles from the eden-reporting-hdi. (assign the roles via grant statements or via dba cockpit)

Connect to your DB where the HDI containers are deployed
Now test if your created SAC user (SAC_PREPROD) is allowed to query views from the eden-reporting-hdi container.
You do this by connecting to the preprod database with your SAC user and a sql console:
-- exeucted in preprod with user SAC_PREPROD
SELECT
"OrderID",
SUM("CC_SALES") AS "CC_SALES"
FROM "EDEN_REPORTING"."dl.reporting.view::CV_ORDERS"
GROUP BY "OrderID"Could not execute 'SELECT "OrderID", "CustomerID", "EmployeeID", "OrderDate", ...'
Error: (dberror) [258]: insufficient privilege: Detailed info for this error can be found with guid '5F227C3542AB8B41BCE145E6B20A97B6'
Now add the role EDEN_REPORTING_READ to SAC_PREPROD and the query will not fail anymore.
[SAC]: Create connection to PreProd system
Inside my SAC tenant i created a new HANA Live connection and used the SAC_PREPROD user created before with the roles for eden-reporting-hdi assigned in the previous chapter.
Host is the database from the preproduction system in BTP we created before.

[SAC]: Create/Copy Story from your production system to preproduction
In SAC i had the following things to do:
- Create HANA live connection to the new preprod db with user SAC_PEPROD
- Copy the production Model
- Change the datasource to preprod
- select the calculation view from the EDEN Reporting HDI container.
- Copy the story from production and exchange the data source to use the preprod Model created previously.
You may need to allow the ip adress of the SAC system to call the preproduction DB via SAP HANA Cloud Central.
Initially my copy of the SAC story will be blank as the data is not yet inside the HDI preprod container.
![]()
[DBX] Import data from the cloud storage into the system
In the SAC story i used a simple table chart to visualize the calculation view inside the eden-reporting hdi container.
In my scenario the table structures will exist but are empty.
![]()
This is due to the fact that the tables were created during the HDI container deployment and are managed by the HDI container.
Before actually importing the data you can check the content of the data export with the IMPORT SCAN syntax:
import scan 's3-<region>://<access_key>:<secret_key>@<bucket_name>/<object_id>';
SELECT * FROM #IMPORT_SCAN_RESULT;
This will show you if the objects you are about to import exist already. If that is the case you can provide the DATA ONLY option to exclude replacing the existing table structures with the import and only import the data.
import all from 's3-<region>://<access_key>:<secret_key>@<bucket_name>/<object_id>' with threads 4 DATA ONLY;
Check if the tables have been loaded.
select schema_name, table_name, record_count, table_size from m_tables where schema_name = 'JOERMUNGANDR_DATA_FOUNDATION';
Now check back with the SAC story:

Conclusion
As you can see it's some effort initially to get it all setup, but once it's done you simply have to execute the two export/import query commands and get a complete refresh of the data.
Please leave a comment in case you have questions or feedback.
Cheers,
Yves
- SAP Managed Tags:
- SAP HANA Cloud, SAP HANA database
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
326 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
403 -
Workload Fluctuations
1
Related Content
- Análise Combinatória de dados de bancos diferentes in Technology Q&A
- 体验更丝滑!SAP 分析云 2024.07 版功能更新 in Technology Blogs by SAP
- Upload file capability in landscape manager in Technology Q&A
- [BIG PROBLEM] SAP Host Agent cannot connect to SYSTEMDB in Technology Q&A
- Corporate Git Setup on SAP BTP versus connecting to Corporate Git directly from SAP BAS in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 4 |