
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Hands-On Tutorial: Leverage AutoML in SAP HANA Clo...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-23-2022
6:21 AM
SAP HANA Cloud has recently been enriched with a new Automated Machine Learning (AutoML) approach. AutoML can be helpful for many different reasons, for example to give a data scientist a head-start into quickly finding a first machine learning model. Also, it is a great starting point to see what is possible with the data and if it is worth to invest more time into the use case.
But isn’t there already an automated machine learning approach in SAP HANA Cloud?
Yes, the Automated Predictive Library (APL) is a proven and trusted approach in SAP HANA Cloud with proprietary content. Further, the APL adds very powerful feature engineering into the process before creating a machine learning model. If you are curious to give it a try, have a look at the following Hands-On tutorial by my colleague andreas.forster.
The Predictive Analysis Library (PAL) provides the data scientist with a huge variety of different expert algorithms to choose from. Now, PAL provides new algorithm pipelining capabilities and an AutoML approach on top, targeting classification, regression and time series scenarios. The new framework allows data scientist experts to build composite pipeline models of multiple PAL algorithms and with the aid of the AutoML engine, an automated selection of pipeline functions from data preprocessing, comparison of multiple algorithms, hyper-parameter search and optimal parameter value selection. Thus, expert data scientists can benefit from a tremendous productivity up-lift, deriving better PAL models in less time.
Let’s take a look at a concrete example to see what is possible through this new approach in the PAL. The challenge will be to predict if a transaction if fraudulent or not. Such use cases are often quite challenging due to imbalanced data and require different techniques before implementing a machine learning model.
What will you learn in this Hands-On tutorial?
What are the requirements?
Let’s jump right in. In your Python editor install and import the following library:
The hana_ml library enables you to directly connect to your HANA. To leverage its full potential you have to make sure that your user has the following policies assigned:
Set your HANA host, port, user, password and encrypt to true:

Execute the following command to connect to your HANA:
You can hide your login credentials through the Secure User Store from the HANA client and don’t have them visible in clear text. In our command prompt execute the following script:
Then back in your Python editor you can use the HANA key to connect:
Now, upload a local dataset and push it directly into HANA. Make sure you change the path to your local directory.
Before you bring your local dataset into HANA, please execute some transformations. Change the columns to upper string and add a unique Transaction ID to the data. This ID will later be used as a key in our machine learning algorithms, which are directly running in HANA.
Next, create a HANA dataframe and point it to the table with the uploaded data.
If your data already exists in HANA, you can create a HANA data frame through the sql or table function i.e.
Next, control your data and convert the following variables accordingly.
Control the conversion and take a look at a short description of the data. Note the target variable is called Fraud. In addition, there are eight predictors capturing different information of a transaction.
Next, split the data into a training and testing set.
Please control the size of the training and testing datasets.
Import the following dependencies for the AutomaticClassification.
Further, you can manage the workload in HANA by creating workload classes. Please execute the following SQL script to set the workload class, which will be used in the AutomaticClassification.
The AutoML approach automatically executes data processing, model fitting, -comparison and -optimization. First, create an AutoML classifier object “auto_c” in the following cell. It is helpful to review and set respective AutoML configuration parameters.
In addition, you could set the maximum runtime for individual pipeline evaluations with the parameter max_eval_time_mins or determine if the AutoML shall stop if there are no improvement for the set number of generations with the early_stop parameter. Further, you can set specific performance measures for the optimization with the scoring parameter.
A default set of AutoML classification operators and parameters is provided as the global config-dict, which can be adjusted to the needs of the targeted AutoML scenario. You can use methods like update_config_dict, delete_config_dict, display_config_dic to update the scenario definition. Therefore, let’s reinitialize the Auto ML operators and their parameters.
You can see all the available settings when you display the configuration file.
Let’s adjust some of the settings to narrow the searching space. As the resampling method choose the SMOTETomek method, since the data is imbalanced.
Exclude the Transformer methods.
As machine learning algorithms keep the Hybrid Gradient Boosting Tree and Multi Logistic Regression.
Let’s set some parameters for the optimization of the algorithms.
Review the complete Auto ML configuration for the classification.
Next, fit the Auto ML scenario on the training data. It may take a couple of minutes. If it takes to long exclude the SMOTETomek in the resampler method of the config file.
You can monitor the pipeline progress through the execution logs.
Now, evaluate the best model on the testing data.
Then, you can create predictions with your machine learning model.
Of course, you can also save the best model in HANA. Therefore, create a Model Storage.
Save the model through the following command.
I hope this blog post helped you to get started with your own SAP Machine Learning use cases and I encourage you to try it yourself. If you want to try out more notebooks, have a look at the following Github Repository.
I want to thank andreas.forster, christoph.morgen and raymond.yao for their support while writing this Hands-On tutorial.
Cheers!
Yannick Schaper
But isn’t there already an automated machine learning approach in SAP HANA Cloud?
Yes, the Automated Predictive Library (APL) is a proven and trusted approach in SAP HANA Cloud with proprietary content. Further, the APL adds very powerful feature engineering into the process before creating a machine learning model. If you are curious to give it a try, have a look at the following Hands-On tutorial by my colleague andreas.forster.
The Predictive Analysis Library (PAL) provides the data scientist with a huge variety of different expert algorithms to choose from. Now, PAL provides new algorithm pipelining capabilities and an AutoML approach on top, targeting classification, regression and time series scenarios. The new framework allows data scientist experts to build composite pipeline models of multiple PAL algorithms and with the aid of the AutoML engine, an automated selection of pipeline functions from data preprocessing, comparison of multiple algorithms, hyper-parameter search and optimal parameter value selection. Thus, expert data scientists can benefit from a tremendous productivity up-lift, deriving better PAL models in less time.
Let’s take a look at a concrete example to see what is possible through this new approach in the PAL. The challenge will be to predict if a transaction if fraudulent or not. Such use cases are often quite challenging due to imbalanced data and require different techniques before implementing a machine learning model.
What will you learn in this Hands-On tutorial?
- Access data from your local Python environment directly in SAP HANA Cloud.
- Leverage the native Auto Machine Learning capability in SAP HANA Cloud.
What are the requirements?
- Please have your favorite Python editor ready. I used a Jupyter Notebook with Python Version 3.6.12.
- The HANA Cloud must have at least 3 CPUs and the script server must be enabled.
- Download the Python script and the data from the following GitHub repository.
Let’s jump right in. In your Python editor install and import the following library:


The hana_ml library enables you to directly connect to your HANA. To leverage its full potential you have to make sure that your user has the following policies assigned:
- AFL__SYS_AFL_AFLPAL_EXECUTE
- AFL__SYS_AFL_APL_AREA_EXECUTE
- WORKLOAD_ADMIN
Set your HANA host, port, user, password and encrypt to true:
Execute the following command to connect to your HANA:

You can hide your login credentials through the Secure User Store from the HANA client and don’t have them visible in clear text. In our command prompt execute the following script:

Then back in your Python editor you can use the HANA key to connect:

Now, upload a local dataset and push it directly into HANA. Make sure you change the path to your local directory.
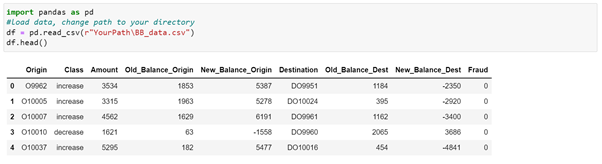
Before you bring your local dataset into HANA, please execute some transformations. Change the columns to upper string and add a unique Transaction ID to the data. This ID will later be used as a key in our machine learning algorithms, which are directly running in HANA.

Next, create a HANA dataframe and point it to the table with the uploaded data.

If your data already exists in HANA, you can create a HANA data frame through the sql or table function i.e.

Next, control your data and convert the following variables accordingly.

Control the conversion and take a look at a short description of the data. Note the target variable is called Fraud. In addition, there are eight predictors capturing different information of a transaction.

Next, split the data into a training and testing set.

Please control the size of the training and testing datasets.

Import the following dependencies for the AutomaticClassification.

Further, you can manage the workload in HANA by creating workload classes. Please execute the following SQL script to set the workload class, which will be used in the AutomaticClassification.

The AutoML approach automatically executes data processing, model fitting, -comparison and -optimization. First, create an AutoML classifier object “auto_c” in the following cell. It is helpful to review and set respective AutoML configuration parameters.
- The defined scenario will run two iterations of pipeline optimization. The total number of pipelines which will be evaluated is equal to population_size + generations × offspring_size. Hence, in this case this amounts to 15 pipelines.
- With elite_number, you specify how many of the best pipelines you want to compare.
- Setting random_seed =1234 helps to get reproducable AutoML runs
In addition, you could set the maximum runtime for individual pipeline evaluations with the parameter max_eval_time_mins or determine if the AutoML shall stop if there are no improvement for the set number of generations with the early_stop parameter. Further, you can set specific performance measures for the optimization with the scoring parameter.

A default set of AutoML classification operators and parameters is provided as the global config-dict, which can be adjusted to the needs of the targeted AutoML scenario. You can use methods like update_config_dict, delete_config_dict, display_config_dic to update the scenario definition. Therefore, let’s reinitialize the Auto ML operators and their parameters.

You can see all the available settings when you display the configuration file.

Let’s adjust some of the settings to narrow the searching space. As the resampling method choose the SMOTETomek method, since the data is imbalanced.

Exclude the Transformer methods.

As machine learning algorithms keep the Hybrid Gradient Boosting Tree and Multi Logistic Regression.

Let’s set some parameters for the optimization of the algorithms.

Review the complete Auto ML configuration for the classification.

Next, fit the Auto ML scenario on the training data. It may take a couple of minutes. If it takes to long exclude the SMOTETomek in the resampler method of the config file.

You can monitor the pipeline progress through the execution logs.

Now, evaluate the best model on the testing data.

Then, you can create predictions with your machine learning model.

Of course, you can also save the best model in HANA. Therefore, create a Model Storage.

Save the model through the following command.

I hope this blog post helped you to get started with your own SAP Machine Learning use cases and I encourage you to try it yourself. If you want to try out more notebooks, have a look at the following Github Repository.
I want to thank andreas.forster, christoph.morgen and raymond.yao for their support while writing this Hands-On tutorial.
Cheers!
Yannick Schaper
- SAP Managed Tags:
- Machine Learning,
- SAP HANA Cloud,
- Python,
- Big Data,
- SAP Business Technology Platform
Labels:
7 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
109 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
74 -
Expert
1 -
Expert Insights
177 -
Expert Insights
346 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
388 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
479 -
Workload Fluctuations
1
Related Content
- Your Ultimate Guide for SAP Sapphire 2024 Orlando in Technology Blogs by SAP
- Exploring ML Explainability in SAP HANA PAL – Classification and Regression in Technology Blogs by SAP
- SAP Datasphere catalog - Harvesting from SAP Datasphere, SAP BW bridge in Technology Blogs by SAP
- Embedding Business Context with the SAP HANA Cloud, Vector Engine in Technology Blogs by SAP
- Second time a Leader in the Gartner® Magic Quadrant™ for Process Mining in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 15 | |
| 12 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 |