
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- How to estimate the cost of a SAP HANA Cloud insta...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-22-2022
7:17 PM
[Updated on November 2023]
In this blog, I’m going to cover the steps to estimate the cost of a SAP HANA Cloud instance with the help of the SAP HANA Cloud Capacity Unit Estimator.
The estimator is a tool that will allow us to calculate the number of Capacity Units (CU) that our SAP HANA Cloud instance will consume per month. To get the results, we need to enter information in the tool such as the desired instance size, some details about the expected workload, and how many hours we are planning to run our instance. Here are the basic steps we need to follow to enter all the required information and collect our results:
1. Select the desired hyperscaler
We must select the hyperscaler where we would like to run our instance. Although the cost of running an SAP HANA Cloud instance will be the same in all the hyperscalers, this information is relevant as different supported sizes depend on the selected hyperscaler.
2. Select the desired SAP HANA Cloud service
SAP HANA Cloud is composed of two components that can be provisioned together or independently. These components are:
- SAP HANA Cloud, SAP HANA Database
- SAP HANA Cloud, Data Lake
In the estimator, we should select the option “SAP HANA Database” when we would like to estimate the cost of a SAP HANA Cloud instance that will contain a SAP HANA Database.
The “Data Lake” option should only be used when we want to estimate the cost of a SAP HANA Cloud, Data Lake as a standalone instance (without SAP HANA Database).
3. Select the amount of activity of the SAP HANA Cloud instance per month
The activity refers to the amount of time the instance will run per month. We can adjust the desired activity using the total amount of hours per month or using a percentage. Note that the SAP HANA Cloud Capacity Unit Estimator is based on 730 hours per month (average amount of hours per month) which is the default activity value.

4. Select the desired SAP HANA Cloud configuration
For beginner users the estimator offers the possibility to use pre-configurations based on the amount of data we want to store and where we want to store it (data temperatures). We need to keep in mind that the term “hot data” refers to data that will be kept in memory within SAP HANA Database, “warm data” is used for data that will be kept on disk within the SAP HANA Database, and “cold data” is for the data that will be kept in the Data Lake Relational Engine.
We can select pre-configurations based on T-shirt sizes or we can manually add the amount of data we want to store in the instance using the “Calculate by data size” section. With either of these options, the estimator will automatically calculate the ideal SAP HANA Cloud configuration to work with that amount of data and provide the estimated monthly cost.

For more technical users, there is a custom configuration section where we will find all the knobs and dials that will allow us to customize the parameters of the instance to our requirements. These knobs are different depending on the SAP HANA Cloud components we plan to use.
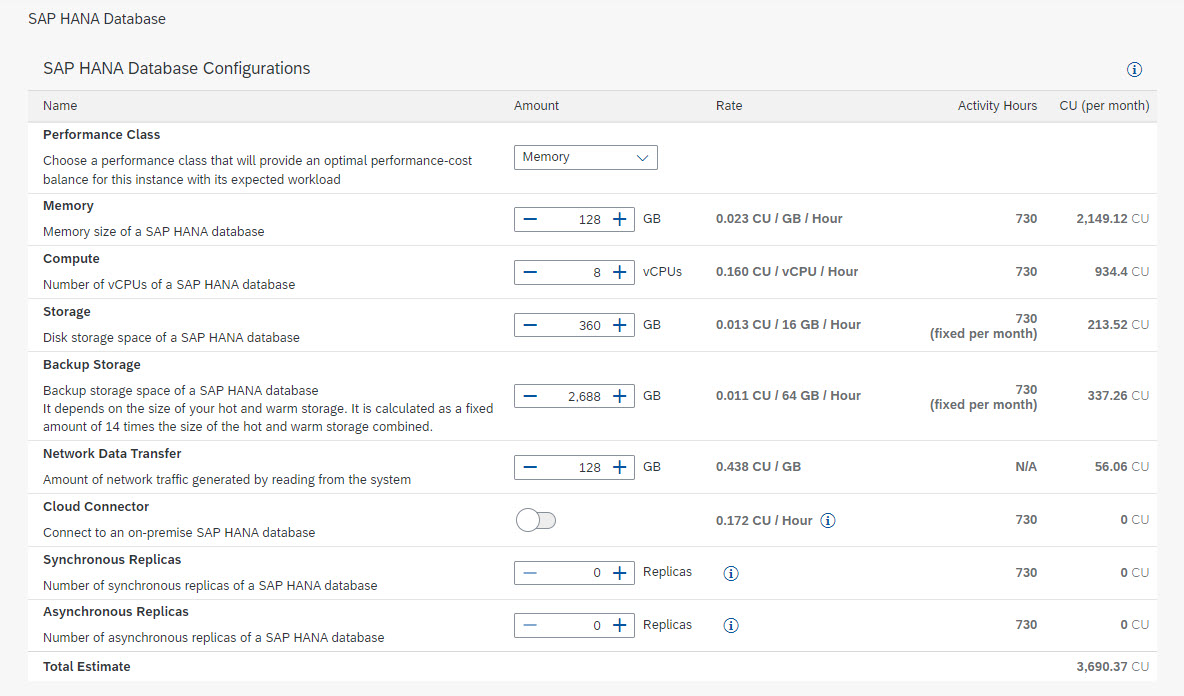
Custom configuration for SAP HANA Database
To estimate the cost for a SAP HANA Database, we should start with the configuration parameters that we will need to specify when creating and managing our SAP HANA Database instance:
- Performance Class
There are four performance classes that offer different core-to-memory ratios for our instance so we can choose the right configuration for our specific workload needs. The options are:
- High Memory: Optimized to support the processing of large data sets that require a lot of memory
- Memory (Default): Default compute-memory ratio, which is suitable for most workloads
- Compute: Optimized to support compute-intensive workloads
- High Compute: Optimized to support compute-intensive workloads that require less memory resources
Depending on the performance class we select, different SAP HANA Cloud configurations will be available when choosing the amount of memory and vCPU for our instance.
- Memory
This is the amount of memory assigned to the HANA Database and it will be used to store data and work with it. As a rule of thumb, you can estimate the amount of memory required by multiplying by 2 the amount of data you would like to keep in memory (hot data).
- Compute
Consist of the number of vCPU that you HANA Database instance will use to process your data.
- Storage
Is the total amount of storage required to persist the data you plan to store in memory (hot data) and at disk (warm data).
Note: The amount of memory, vCPU and storage are linked by the supported configurations and minimum requirements of an instance. Every time we adjust the amount memory or the number of vCPU, the other two values will be adjusted too while for the storage, the minimum amount is determined by the memory and compute, but we can always increase it if needed.
- Cloud Connector
This is optional and it is required in case we need to connect our instance to an on-premise system. The cost of the cloud connector consists of a fixed amount per hour equivalent to 1 vCPU and 0.5 GB of memory.
- Synchronous/ Asynchronous replicas
This is also optional and is only required for cases where additional availability for the SAP HANA Database is required.
Additionally, we should consider two other elements that will contribute to the cost but are influenced by the use we make of the instance instead of its configuration. These elements are:
- Backup Storage
Is the amount of storage required to back up the data stored in the instance (hot and warm data). We can estimate the amount of required backup storage as 14 times the data size.
- Network Data Transfer
Is the amount network traffic generated from reading data from the SAP HANA Database. As this could be hard to estimate, a recommended value we could use the same amount of GB as memory assigned to the instance.
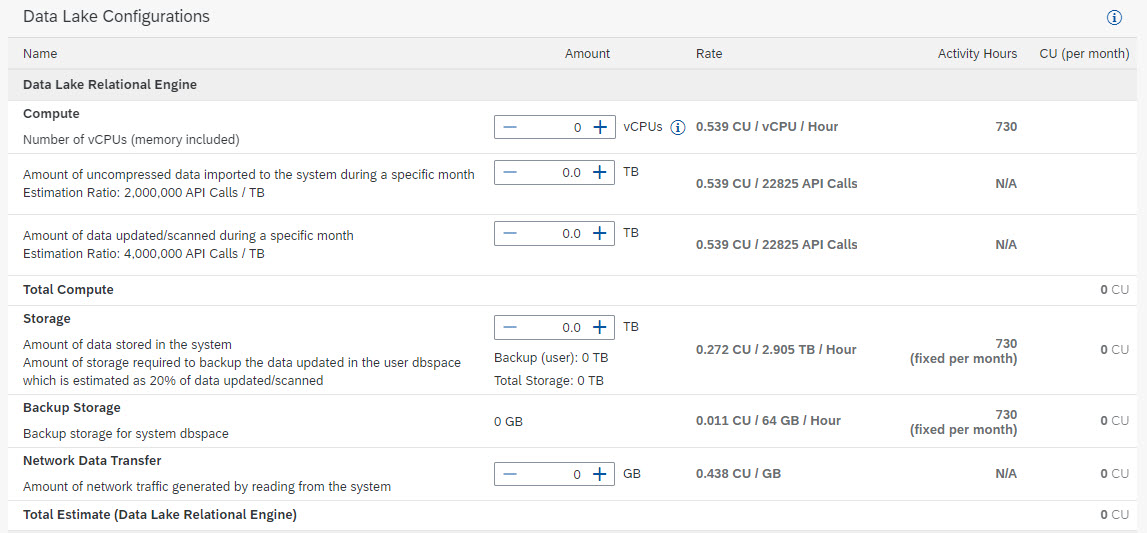
Custom configuration for Data Lake Relational Engine
To estimate the cost of a Data Lake Relational Engine instance, we should provide the following information
- Compute:
The compute costs of a Data Lake Relational Engine instance are generated by running the instance and by reading, writing, and updating data in the instance. To estimate the compute costs for a Data Lake Relational instance we need to define the following parameters:
- The number of vCPUs – These are the total number between the coordinator and worker nodes. The cost generated by the vCPUs is influenced by the amount of activity selected for the instance.
- The amount of uncompressed data that will be imported into the instance during a specific month – Every time data is imported into the data lake relational engine it will generate API calls that will contribute to the compute cost of your instance. As data gets compressed when imported, an estimation is that 2,000,000 API calls are required to import 1 TB of data (uncompressed).
- The amount of data that will be updated and scanned in the instance during a specific month – Similar to when data is imported, every time data is read or updated in the system it will generate API calls that will contribute to the compute costs. As the reads and updates will be on data already compressed and stored in the instance, an estimation is that 4,000,000 API calls are required to read or update 1 TB of data.
- Storage:
The storage costs consist of the storage required by your instance. The total amount of storage required is determined by rounding up to the next TB the result from adding the size of the data stored and most of the data backups.
E.g., If we store 1 TB of data and our data backups are estimated to consume 0.2 TB, the sum is 1.2 TB so the total amount of storage required is 2 TB.
To estimate the storage cost we just need to specify the total amount of data that will be stored in the system. The amount of storage required for data backups will be estimated as 20% of the data scanned/updated in the compute section.
- Backup Storage:
The backup storage costs correspond to the storage required to back up a small part of the Data Lake Relational Engine instance known as the “system dbspace”. The size of the system dbspace will depend on the usage and workload of the instance so it is complicated to estimate, hence the capacity unit estimator contains a fixed value that is good enough to cover most of the cases.
Note: Storage & backup storage costs are independent of the systems activity, and it will be charged for every hour of the month.
- Network Data Transfer:
The amount of network traffic generated by reading from the system. It can be estimated by entering the total amount of data read from the system in a month.
Custom configuration for Data Lake Files:
To estimate the cost of a Data Lake Files we need to introduce the following information in the estimator:
- Compute:
The compute cost for Data Lake Files is generated by the amount of file data scanned by queries and by reading/writing data into the data lake file storage. The compute costs for Data Lake Files consist of:
- SQL on Files Scan – This is the total amount of file data scanned by queries during a specific month.
- The amount of data read/written into data lake file storage in a month – Every time we read or write data against the data lake file storage, we generate API calls that will contribute to the compute cost. We can estimate this cost by entering the total amount of data we expect to read/write in a specific month. The estimator will calculate the number of API calls based on this information.
- Storage costs:
These are generated by the storage required to store all the files. We can estimate it by introducing in the estimator the total size for the files stored in the system.
- Network Data Transfer:
The monthly network transfer costs are estimated based on the amount of network traffic generated when reading data from the system. The estimator tool takes into account the specified amount of data read from the system during a month in the compute section.

5. The results
Once we have completed the previous steps, the SAP HANA Capacity unit estimator will provide an estimate of the total amount of capacity units (CU) that you SAP HANA Cloud instance will consume per month. This information can be found on the top right corner of the estimate.

Final recommendations
Even if we consider ourselves advanced users with the knowledge to estimate the cost for a SAP HANA Cloud instance using the custom configuration section, we always recommend starting with the “calculate by data size” section and then go to the custom configuration to adjust the parameters if needed. This approach will give you a head start as most of the parameters will be estimated by the tool based on the data volumes entered at the beginning.
Let me know in the comments section if you found this post to be useful or if there are any questions or feedback.
- SAP Managed Tags:
- SAP HANA Cloud, SAP HANA database,
- SAP HANA Cloud, data lake,
- SAP HANA Cloud
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
345 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
427 -
Workload Fluctuations
1
Related Content
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- Receive a notification when your storage quota of SAP Cloud Transport Management passes 85% in Technology Blogs by SAP
- Embrace the Future: Transform and Standardize Operations with Chatbot in Technology Blogs by Members
- Capitalizing on AI: The Future of Industries in Technology Blogs by SAP
- Workload Analysis for HANA Platform Series - 2. Analyze the CPU, Threads and Numa Utilizations in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 41 | |
| 25 | |
| 17 | |
| 14 | |
| 9 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |