
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP CAP Application Dynamic Data Source Routing
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
shanthakumar_kr
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-10-2022
8:03 AM
Introduction
A very common use case that we experience while designing an application is the necessity to switch databases on the fly based on region or read/write activity in order to reduce latency and boost availability.
Consider a geo-distributed app, which spans many geographic locations to ensure high availability, resiliency, compliance, and performance. The application layer is distributed across regions and linked to distributed databases. As a result, the application layer is highly available and reliable. Furthermore, the geo-distributed app can fulfil user requests with little latency, regardless of the user's location. If you need help setting up the geo-distributed app, see the blog post.
The user data should be located as close to the application instance as possible for optimal performance. Let's examine various data storage distribution patterns for DB operations.
- Read local/write locally: In this pattern, all the read and write requests are served from the local region. It will not only help in reducing the latency but also reduce the potential for network errors. There are few global databases having support for this functionality, Amazon DynamoDB is a great example to understand this pattern.
- Read local/write global: In this pattern, specific region works as a global write region. All the write operations will be performed in this region, while read requests can be served from any region. Amazon Aurora is a great example to understand this pattern.
- Read local/write partitioned: In this pattern, each item or record is assigned to a home region. Here we map records with partition key (such as user ID) to a home region close to where most write requests will originate.
There are several techniques for implementing patterns 2 and 3 at the application layer, but we will concentrate on the spring boot dynamic data source routing approach to disperse database operations.
Solution Architecture
The conceptual solution diagram below shows an active-active application architecture design, which integrates SAP CAP applications with dynamic data source routing for read-write operations.
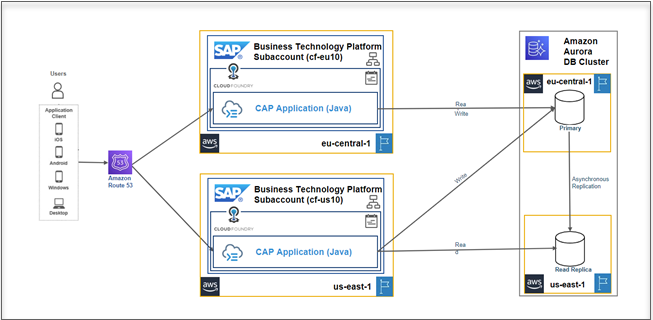
Figure 1: Active-Active Application Architecture with local reads and global writes
The basic principle of separation is to route the read operations to the closest region where the latency is low and write operations to the primary region.
- The primary region is responsible for read and write operations. The second region is only responsible for the read operations.
- The primary node synchronizes data from the primary region to all secondary regions through a data replication mechanism.
- The business side sends the write operations to the primary region and read operations to the primary/secondary region by program or middleware
Implementation
We'll start with the SAP CAP Bookshop sample application and work our way up to the dynamic data source routing adjustments. In order to implement dynamic data source routing in the SAP CAP Java application, the spring framework offers a concept known as AbstractRoutingDataSource.
Link to the Git repository containing the entire application
Let’s jump into the code straightaway!
1. Spring Configuration (application.yaml file)
The following configuration is for a SQLite data source, so that we can easily implement and test the application locally. (Refer aurora profile for Aurora Data source)
Configure the database connection strings in the application.yaml file for both data sources i.e., primary and secondary.
spring:
config.activate.on-profile: sqlite
datasource:
primary:
url: "jdbc:sqlite:primary.db"
driver-class-name: org.sqlite.JDBC
initialization-mode: never
hikari:
maximum-pool-size: 10
secondary:
url: "jdbc:sqlite:secondary.db"
driver-class-name: org.sqlite.JDBC
initialization-mode: never
hikari:
maximum-pool-size: 10 2. Data Source Configuration (DataSourceConfiguration.java)
We will create data sources for both of our databases and provide them to DataSourceRouting. Here we will define key-value pairs for all configured data sources in the above step. The value will be the data source instance and the key will be from determineCurrentLookupKey() method. The lookup key is passed as a request attribute from SAP CAP Application Handler.
We can also mention a default data source if nothing can be found for any user request. it will be the default one and prevent exceptions.
@Configuration
public class DataSourceConfiguration {
//Fetching the DB ConfigurationProperties from application.yaml
@Bean
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSourceProperties primaryDataSourceProperties()
{
return new DataSourceProperties();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.secondary")
public DataSourceProperties secondaryDataSourceProperties()
{
return new DataSourceProperties();
}
@Bean
@Primary
public DataSource routingDataSource(DataSourceProperties primaryDataSourceProperties,DataSourceProperties secondaryDataSourceProperties)
{
AbstractRoutingDataSource routingDataSource = new AbstractRoutingDataSource() {
@Override
protected Object determineCurrentLookupKey() {
//return DatabaseContextHolder.get();
String temp = getReadEndPointRegion();
return temp;
}
};
Map<Object, Object> dataSourceMap = new ConcurrentHashMap<>();
dataSourceMap.put("primary", primaryDataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build());
dataSourceMap.put("secondary", secondaryDataSourceProperties.initializeDataSourceBuilder().type(HikariDataSource.class).build());
routingDataSource.setTargetDataSources(dataSourceMap);
routingDataSource.setDefaultTargetDataSource(dataSourceMap.get("primary"));
routingDataSource.afterPropertiesSet();
return routingDataSource;
}
public String getReadEndPointRegion() {
RequestAttributes requestAttributes = RequestContextHolder.currentRequestAttributes();
return (String) requestAttributes.getAttribute("readEndPointRegion", RequestAttributes.SCOPE_REQUEST);
}
}3. Use the DataSourceRouting in SAP CAP Application Handler
We already have SAP CAP Application Handlers such as CatalogService, AdminService, and others. For testing purposes, we will implement the routing logic in CatalogServiceHandler, which will route all read operations to the secondary data source and write operations to the primary data source.
To change the data source dynamically, add the following event in CatalogServiceHandler
@Before(event = { CqnService.EVENT_READ})
public void beforeEvent(EventContext context) {
RequestContextHolder.currentRequestAttributes().setAttribute("readEndPointRegion", "secondary", RequestAttributes.SCOPE_REQUEST);
}Here we are setting the readEndPointRegion as secondary, so that all the read request goes to the secondary data source. The primary target data source is always used for write operations because we set the default target data source as the primary in the previous step.
Testing the application
1. Create a sqlite data source for primary and secondary as per the configuration in application.yaml.
To create data sources, run the following commands. This will create the primary.db and secondary.db files in the project root.
cds deploy --to sql:primary.db --no-save
cds deploy --to sql:secondary.db --no-save2. To run the application, use the command line to pass the profile parameters as shown below.
mvn spring-boot:run "-Dspring-boot.run.profiles=sqlite"Else in VS Code, create the launch.json as follows and run or debug the application
{
"version": "0.2.0",
"configurations": [
{
"name": "Run BookShop",
"type": "java",
"request": "launch",
"mainClass": "my.bookshop.Application",
"args": "--spring.profiles.active=sqlite",
"env": {
"READ_ENDPOINT_REGION": "secondary"
}
}
]
}3. Access the application by entering the credentials (admin/admin) at the following URL. http://localhost:8080/fiori.html

Figure 2: SAP Fiori Launchpad Home page
4. Navigate to the Manage Books tile and modify the existing book or create new books. Here I am modifying the existing book description.

Figure 3: Manage Books Fiori Application
5. Finally validate the changes.
As per our configuration, the changes should be updated on the primary data source.
Use a database tools like DBeaver to validate the changes. Open both (primary.db, secondary.db) database files from the project root and validate the my_bookshop_Books table.
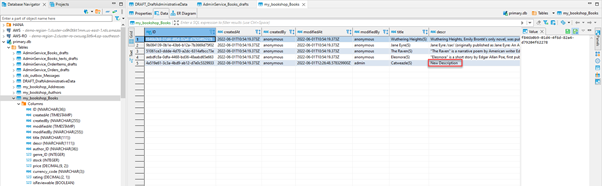
Figure 4: Accessing the data using DBeaver
Also validate using Browse books tile

Figure 5: Browse Books Fiori Application
Here the description is not changed since the read operations are routed to secondary data source
Known Issues
The use of read-replica instances does not ensure strict ACID semantics for database access and should be used with caution. This is due to the fact that the write operation data might not be immediately visible to the read transaction. Therefore, it is recommended to use read-replica instances for transactions where read data does not change frequently and when the application is capable of tolerating obsolete data.
Related Blogposts
SAP BTP Multi-Region reference architectures for High Availability and Resiliency by maheshkumar.palavalli
Architecting solutions on SAP BTP for High Availability by muralidaran.shanmugham2
Distributed Resiliency of SAP CAP applications using Amazon Aurora (Read Replica) with Amazon Route ... by shanthakumar.krishnaswamy
Conclusion
I hope this blog post has given you a general concept of how to configure Dynamic Data Source Routing in SAP CAP Application to address the problem. This solution can be adapted to different use cases and data sources.
The entire application can be found in GitHub Repo
Please leave any thoughts or feedback in the comments section below.
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- How to use AI services to translate Picklists in SAP SuccessFactors - An example in Technology Blogs by SAP
- Dynamic Approver based on dynamic task determination. in Technology Q&A
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Mistral gagnant. Mistral AI and SAP Kyma serverless. in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |