
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Intelligence – What’s New in DI:2022/10
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-31-2022
3:09 PM
SAP Data Intelligence, cloud edition DI:2022/10 is now available.
Within this blog post, you will find updates on the latest enhancements in DI:2022/10. We want to share and describe the new functions and features of SAP Data Intelligence for the Q4 2022 release.
If you would like to review what was made available in the previous release, please have a look at this blog post.
This section will give you a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
This topic area focuses mainly on all kinds of connection and integration capabilities which are used across the product – for example: in the Metadata Explorer or on operator level in the Pipeline Modeler.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
This topic area covers new operators or enhancements of existing operators. Improvements or new functionalities of the Pipeline Modeler and the development of pipelines.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
This topic area includes all services that are provided by the system – like administration, user management or system management.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
These are the new functions, features and enhancements in SAP Data Intelligence, cloud edition DI:2022/10 release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
If you are interested, please refer to What’s New in Data Intelligence – Central Blog Post.
For more updates, follow the tag SAP Data Intelligence.
We recommend visiting our SAP Data Intelligence community topic page to check helpful resources, links and what other community members post. If you have a question, feel free to check out the Q&A area and ask a question here.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
Within this blog post, you will find updates on the latest enhancements in DI:2022/10. We want to share and describe the new functions and features of SAP Data Intelligence for the Q4 2022 release.
If you would like to review what was made available in the previous release, please have a look at this blog post.
Overview
This section will give you a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
SAP Data Intelligence 2022/10

Connectivity & Integration
This topic area focuses mainly on all kinds of connection and integration capabilities which are used across the product – for example: in the Metadata Explorer or on operator level in the Pipeline Modeler.
Microsoft SQL Server 2019 support
USE CASE DESCRIPTION:
- Connect, browse and ingest data from Microsoft SQL Server 2019 databases in Generation 1 and Generation 2 Pipelines.
- Supported operators:
- SQL Consumer
- Table Consumer
- Flowagent SQL Executor
- TLS, Client certificate, cloud connector support.

BUSINESS VALUE – BENEFITS:
- Support latest MSSQL versions in SAP Data Intelligence Cloud.
Support X.509 authentication for HANA_DB connection type
USE CASE DESCRIPTION:
- X.509 client certificates as authentication method for HANA_DB connection types.
- Supported Operators in Generation 1 and Generation 2:
- All HANA Operators.
- Flowagent operators (Table Consumer, Table Producer, SQL Consumer, Flowagent SQL Executor, Data Transfer, Table Replicator).

BUSINESS VALUE – BENEFITS:
- Use non-basic authentication for HANA connections in SAP Data Intelligence Cloud.
Support ODP as source in Replication Flows
USE CASE DESCRIPTION:
- Allow integration of SAP ABAP based systems via ODP interface as a source in Replication Flows for mass data replication scenarios. Supported for replicating data sets provided via ODP interface including in ODP_SAPI & ODP_BW context.
- Replicate (initial load + delta) via ODP interface from various sources:
- SAP Business Warehouse e.g. (A)DSO’s etc.
- SAP Business Suite Systems e.g. Business extractors
- SAP S/4HANA on Premise


BUSINESS VALUE – BENEFITS:
- Support simplified mass data replication scenarios for SAP ABAP source systems using the ODP interface.
Support Cluster Tables with Delta in Replication Flows
USE CASE DESCRIPTION:
- Cluster tables can be replicated in initial + delta load mode capturing insert, update and delete processes into any supported target by replication flows.
- Replicate (initial load + delta) ABAP cluster table from ECC to:
- HANA
- Object store (in CSV, Parquet, JSON, JSONL format)
- Kafka (in AVRO, JSON format)

BUSINESS VALUE – BENEFITS:
- Support mass data replication scenarios for cluster tables.
Support Kafka as Target System in Replication Flows
USE CASE DESCRIPTION:
- Replicate (initial + delta) from all supported source systems of replication flows into Kafka as a target. When using Kafka as a target the following properties need to be considered:
- Container (not required & disabled)
- Number of Partitions
- Replication Factor
- Compression (e.g. gzip, snappy)
- Format (AVRO or JSON)

BUSINESS VALUE – BENEFITS:
- Support mass data replication scenarios from various sources into Kafka as a target system using replication flows.
Support Parallel Data Transfer Jobs in SAP S/4HANA systems
USE CASE DESCRIPTION:
- Support parallel data transfer jobs in SAP S/4HANA on Premise systems to serve a high amount of consumers extracting data from SAP S/4HANA (e.g. Data intelligence & SAP Business Warehouse systems etc.)
- Allow customers to define the number of parallel data transfer jobs via a parameter maintained in the source SAP system.
- Further details available in SAP Notes 3253654 & 3223735

BUSINESS VALUE – BENEFITS:
- Higher parallelization in the SAP S/4HANA system to process requests from many consumers requesting data for various data extraction scenarios (e.g. Data intelligence, SAP BW via ODP).
Support subfolders in target dataset for Replication Flows
USE CASE DESCRIPTION:
- Support slashes in target dataset names in case you use an object store as target within a Replication Flow (GCS, AWS S3, HDL-Files or ADL V2).
- Slashes can be used in target dataset names to allow the definition of subfolder paths that will automatically be created during runtime if they are not yet existing.
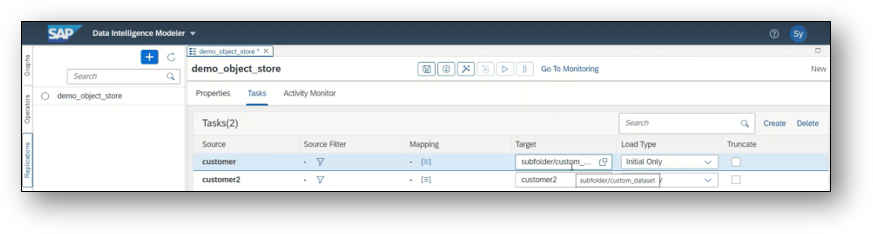
BUSINESS VALUE – BENEFITS:
- Simplified way for end users to define subfolder file paths in a Replication Flow
- E.g. hierarchical application components of CDS views can therefore be reflected in the object store folder structure (or file prefix resp.) without having to create one replication flow per CDS view.
Pipeline Modelling
This topic area covers new operators or enhancements of existing operators. Improvements or new functionalities of the Pipeline Modeler and the development of pipelines.
Multiplexing in Generation 2
USE CASE DESCRIPTION:
- Multiplexing in Generation 2 pipelines without operators for main and Python subengine
- 1:n, n:1 and n:m connections between operators are supported
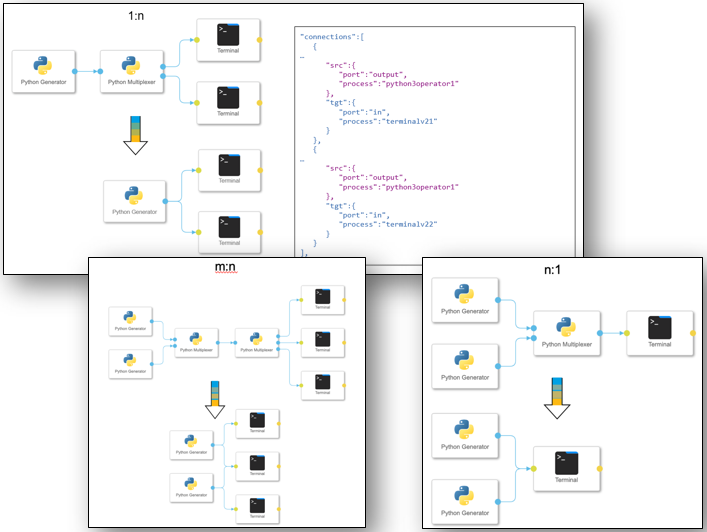
BUSINESS VALUE – BENEFITS:
- The multiplexing without multiplexer operators or additional Python script operators is supported
Support of File Sources in Generation 2
USE CASE DESCRIPTION:
- Resilient File consumption in Generation 2 Pipelines.
- New Operators:
- Binary File Consumer
- List Files Operator
- Snapshot support with at-least-once guarantee for Read = Once and List = Once configuration respectively.

BUSINESS VALUE – BENEFITS:
- Standard Operators for file consumption in Generation 2 to enable resilient processing of unstructured file data.
Support for Excel Files as source
USE CASE DESCRIPTION:
- Support of Excel Files as source for Generation 1 and Generation 2 Structured File Consumer operators.
- New read only properties section in Structured File Consumer operators to avoid inconsistencies in the operator configuration.
- Support of Excel files within Metadata Explorer.
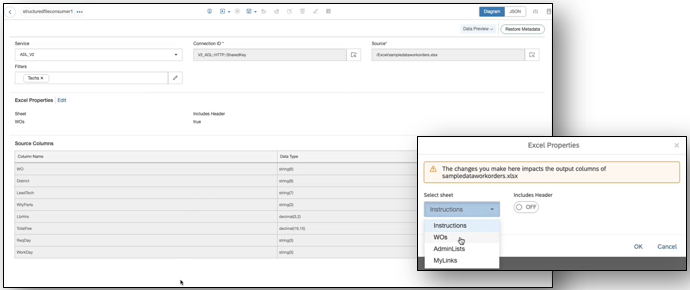

BUSINESS VALUE – BENEFITS:
- More comprehensive structured file consumption capabilities in SAP Data Intelligence Cloud.
- Ability to view metadata of an Excel file and preview contents of a specific sheet both in catalog and on a remote connection.
Default memory/cpu settings for pipelines
USE CASE DESCRIPTION:
- Apply default graph limits on graphs.
- Switch the warning of missing resource limits to an error on explicit graph validation.
- Implicit validation on graph start will continue to treat missing resource limits as warning.
- Graphs that are delivered as standard content in SAP Data Intelligence Cloud have been updated with proper resource limits.
- See updated SAP Help Documentation
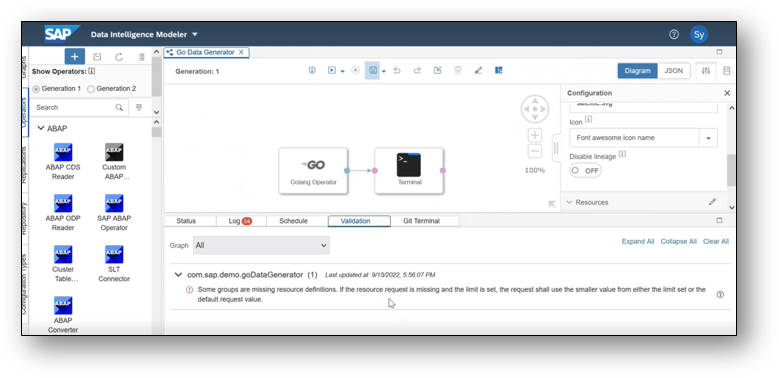

BUSINESS VALUE – BENEFITS:
- Better control over resource consumption of pipelines.
Support ODP as source in Generation 2
USE CASE DESCRIPTION:
- Enable the ABAP-based systems to access data (initial + delta) via ODP to the Read Data from SAP System Generation 2 operator accessing objects in ODP_BW & ODP_SAPI context.
- Supported object types: SAPI and BW
- Supported ABAP source systems:
- SAP S/4HANA 2022 on Premise (version >= 1909 with TCI)
- SAP Business Warehouse (using DMIS AddOn)
- SAP Business Suite Systems, e.g. SAP ECC (using DMIS AddOn)

BUSINESS VALUE – BENEFITS:
- Enable resilient data integration for ODP sources in generation 2.
Extract HANA ODBC logs
USE CASE DESCRIPTION:
- Possibility to activate/deactivate HANA ODBC tracing for the following Generation 1 and Generation 2 Flowagent operators (only for HANA_DB connection type):
- Structured Table Producer/Consumer
- Structured SQL Consumer

BUSINESS VALUE – BENEFITS:
- Extract low level ODBC debug logs for HANA connections from Flowagent producer/consumer operators to accelerate root cause analysis of errors.
Administration
This topic area includes all services that are provided by the system – like administration, user management or system management.
Policy for read-only access to Monitoring application
USE CASE DESCRIPTION:
- Introduction of a dedicated policy sap.dh.monitoring that gives a user read-only access to the Analytics and Instances tabs in the monitoring application.
- Access to Schedules currently not supported.

BUSINESS VALUE – BENEFITS:
- Allow the creation of monitoring users.
Make Axino Memory & Scale Settings Configurable
USE CASE DESCRIPTION:
- Change/Maintain Axino resources in the SAP Data Intelligence Cloud System Management application.
- Maximum Memory and CPU resources as well as minimum and maximum number of Axino instances can be defined by an administrator.
- See SAP Note 3148794

BUSINESS VALUE – BENEFITS:
- Avoid Axino out of memory failures in ABAP scenarios and simplified maintenance of used resources.
These are the new functions, features and enhancements in SAP Data Intelligence, cloud edition DI:2022/10 release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
If you are interested, please refer to What’s New in Data Intelligence – Central Blog Post.
For more updates, follow the tag SAP Data Intelligence.
We recommend visiting our SAP Data Intelligence community topic page to check helpful resources, links and what other community members post. If you have a question, feel free to check out the Q&A area and ask a question here.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
- SAP Managed Tags:
- SAP Data Intelligence
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
12 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
340 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
417 -
Workload Fluctuations
1
Related Content
- What’s new in Mobile development kit client 24.4 in Technology Blogs by SAP
- AI Core - on-premise Git support in Technology Q&A
- What is the preferred way of data fetch from HANA view in ABAP Program in Technology Q&A
- what is the standard page to display employee Username in SuccessFactors : IAS or Spotlight? in Technology Q&A
- Behind the compatibility - What are the compatibility means between GRC and the plugins in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 32 | |
| 24 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |