
- SAP Community
- Products and Technology
- Spend Management
- Spend Management Blogs by SAP
- Ariba Analytics using SAP Analytics Cloud, Data In...
Spend Management Blogs by SAP
Stay current on SAP Ariba for direct and indirect spend, SAP Fieldglass for workforce management, and SAP Concur for travel and expense with blog posts by SAP.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-06-2022
10:10 AM
Introduction
SAP Analytics Cloud makes it easy for businesses to understand their data through its stories, dashboards and analytical applications. However, sometimes we might not be sure how we can leverage SAC to create these based on data from other applications
For this worked example, we're going to make use of SAP Data Intelligence Cloud to retrieve data from SAP Ariba through its APIs, before storing it in SAP HANA Cloud's JSON Document Store
In further blog posts, we will build a model on top of this stored data and show how this can be consumed in an SAP Analytics Cloud Story. The focus of this series of blog posts is to show a technical approach to this need, not to provide a turnkey ready-to-run SAC story. After following this series you should have an understanding of how you can prepare your own stories using this approach
Ariba Analytics in SAP Analytics Cloud
For this example, we're going to create a simple story that lets you know how much spend has been approved within Ariba Requisitions created in the last thirty days

A simple SAC Story tracking Approved Requisitions
A Requisition is the approvable document created when a request is made to purchase goods or services. Our approach will let us view only the Approved Requisitions, excluding those still awaiting approval
For those feeling more adventurous, this setup can be repeated with different document types, and those combined to create more in depth SAP Analytics Cloud Stories. This is outside of the scope of our blog series
Solution Overview
Our finished solution will need SAP HANA runtime artifacts such as Document Store Collections, SQL Views and Calculation Views. We will define these as design-time artifacts in Business Application Studio, then deploy them to an HDI Container within our SAP HANA Cloud instance

Deploying our Design-time artifacts into SAP HANA Cloud
Using a scheduled SAP Data Intelligence Cloud Pipeline, we'll query SAP Ariba's APIs and place the data within our HANA Cloud Document Store Collection

Scheduled replication of Ariba Data
Our SQL View lets us create a view on top of the data within our JSON Documents. Creating a Calculation View on top of one or many SQL views will let us expose the data to SAP Analytics Cloud

Viewing the data in SAP Analytics Cloud
SAP Analytics Cloud can use HANA Cloud Calculation Views as the source for Live Data Models. With Live Data Models, data is stored in HANA Cloud and isn't copied to SAP Analytics Cloud
This gives us two main benefits: We avoid unnecessarily duplicating the data, and ensure changes in the source data are available immediately (provided no structural changes are made)
Finally, we use the Live Data Model to create a Story within SAP Analytics Cloud. Once we've got everything set up, we can use this story to check our data at any time, with the Data Intelligence Pipeline refreshing the data in the background on a predefined schedule
Creating an Ariba Application
In order to access the APIs provided by Ariba, we'll need to have what's known as an Ariba Application. We do this through the SAP Ariba Developer Portal
For our use case we will be requesting access to the Operational Reporting for Procurement API

From the Ariba Developer Portal, click on Create Application

Click on the Plus Symbol

Enter an Application Name and Description then click on Submit
Once the Application has been created, we'll need to request API access for the Application

Click on Actions, then Request API Access

Select the Operational Reporting for Procurement API, then select your Realm and click on Submit
Once the API Access Request has been approved by Ariba, your admin will be able to generate the OAuth Secret for our application

Your Ariba admin can click on Actions, then Generate OAuth Secret
This will generate our OAuth Secret, which is required to use the API. The secret will only be displayed once, so the admin should (securely) store this and provide it to you for use in the application
If the OAuth Secret is lost, the admin can regenerate it, at which point the old secret will stop working and you will have to use the newly generated secret
For a more comprehensive look at Ariba Applications we can refer to the Ariba APIs Datasheet and this blog post by ajmaradiaga
Ariba API
When we call the Ariba API, we have a number of things to consider. For our example, we're using the Synchronous API to retrieve data, but there's also a set of Asynchronous APIs you should consider when retrieving bulk data

Documentation is available online
In addition, when retrieving data sets, you have to specify an Ariba View that you wish to retrieve. These are similar to reporting facts in the Ariba solution, such as Requisition or Invoice. Views will specify which fields are returned, and may also specify filters you should provide when calling them
To simplify our example we're going to use a System View, which is predefined in Ariba. You are also able to work with Custom Views using the View Management API to better match your requirements but this falls outside the scope of this blog series
To explore these at your own pace, you can visit developer.ariba.com
Enabling Document Store in HANA Cloud
The Document Store is SAP HANA Cloud's solution for storing JSON Documents. While the Column and Row Stores use Tables to store their data, the Document Store stores data inside Collections
Before we activate the Document Store in HANA Cloud, just a word about resources. Like the Script Server, the Document Store is an additional feature that can be enabled, however we should consider HANA Cloud's current resourcing before enabling it. For more information on this we can consult the help documentation
When we're ready to enable, we'll need to navigate to SAP HANA Cloud Central.

From the BTP Control Center, we select our Global Account and click Open in Cockpit

From here we see our Subaccounts - we choose the Subaccount where our HANA instance resides

From our Subaccount, we click on Spaces

From the Spaces page, we select the Space that contains our HANA instance

Click on SAP HANA Cloud

Click on Actions, then Open In SAP HANA Cloud Central
From HANA Cloud Central, we can then activate the Document Store

Click on the dots, then choose Manage Configurations

Click on Edit

Go to Advanced Settings, select Document Store then click on Save
Once our HANA Cloud instance has restarted, we'll be able to use the Document Store
Creating a DocStore Collection in Business Application Studio
While we can create a Collection directly using SQL through Database Explorer, we want to make sure we also have a design-time artifact for our DocStore Collection
To do this, we'll use the Business Application Studio. For those unfamiliar with Business Application Studio, you can follow this Learning Journey Lesson to set up a Workspace - we'll assume this is already in place
It's time to set up our SAP HANA Database Project, and create the HDI Container where our runtime objects will reside

Creating our Project

Select SAP HANA Database Project
Next we'll need to provide some information for our project

Give our Project a name and click Next

Leave the Module name as is and click Next
Double check the Database Version and Binding settings then click Next

Setting our Database Information
Next we have to bind the project to a HANA Cloud instance within Cloud Foundry. The Endpoint should be automatically filled, but we have to provide our Email and Password before we can perform the binding

Binding our Cloud Foundry Account
For this example we're going to create a new HDI Container
If our Cloud Foundry space has more than one HANA Cloud instance, we may want to disable the default selection and manually choose the HANA Cloud instance where our container will reside
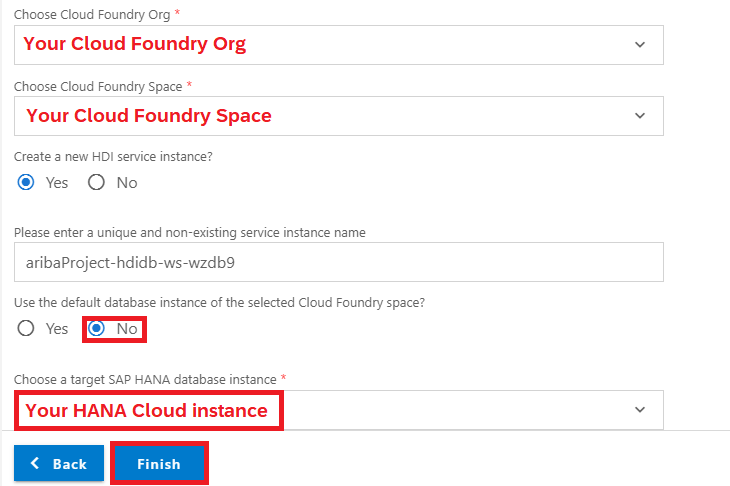
Creating our HDI Container
Now that we have our HDI Container and SAP HANA Project set up, it's time to create our design-time objects. First, we login to Cloud Foundry

Click on View, then Find Command or press Ctrl+Shift+P

Search and select CF: Login to Cloud Foundry, then follow the instructions before selecting the Space with our HANA Cloud instance
Next, we'll create our DocStore Collection

Use Find Command again to find Create SAP HANA Database Artifact, then click on it

Ensure that the artifact type is Document Store Collection, name is aribaRequisition and that the artifact will be created within the src folder of a HANA Project, then click on Create

Finally, we want to find our SAP HANA Project on the Explorer on the left, and click on the rocket icon to Deploy
After the deployment is successful, we have both our design-time .hdbcollection artifact, as well as the runtime DocStore collection which has been created in our HDI Container
Creating our Connections in Data Intelligence
So far we've gained access to Ariba APIs and enabled the Document Store in our HANA Cloud Instance. Next, we'll be setting up two Connections in Data Intelligence Cloud
The first Connection will allow our Data Intelligence Pipeline to query the Ariba APIs to retrieve our data, and the second will allow us to store this data in the Document Store within our HDI Container
First, we use the DI Connection Manager to create a new Connection, selecting OPENAPI as the Connection Type

Create a new Connection in the Connection Manager
Our OpenAPI Connection will be used to send the request to Ariba. We're going to set the connection up as below, using the credentials we received when we created our Ariba Application

Using our Ariba Application OAuth Credentials to create the OpenAPI Connection
Next, we're going to create a HANA Connection that will let us work with the HDI Container we created earlier. To get the credentials, we have to go to the BTP Cockpit

Select our HDI Container from the SAP BTP Cockpit

Click on View Credentials

Click on Form View
We'll want to keep this window open as we create our HANA DB Connection, as it has the details we need. Within Data Intelligence Cloud, create a new connection of type HANA_DB and fill it out as below using the credentials

Enter the credentials to create our HDI Connection
While we have the credentials open, take note of the Schema name. We'll need this to set up our pipeline
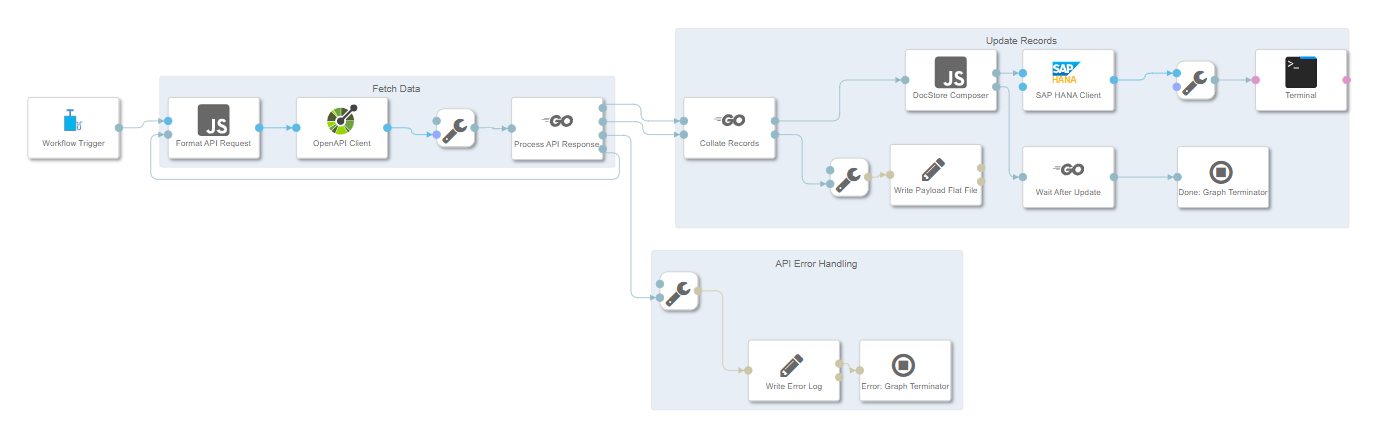
Pipeline Overview
The source code for our pipeline can be found here. Copy the contents of this JSON to a new Graph within the Data Intelligence Modeler. If you're not familiar with how to do this, you can refer to the README
When the pipeline starts, a GET request is made to the Ariba API. If there are more records to be fetched, the pipeline will make further requests until it has all available data. To avoid breaching Ariba's rate limiting, there is a delay of 20 seconds between each call

Fetching data from Ariba
Once all of the records have been fetched, the Document Store Collection is truncated to remove outdated results, and the most up to date data is inserted into our collection

Updating records
- A copy of the data is stored as a flat file in the DI Data Lake as reference
- The HANA Document Store Collection is truncated, and Documents are added to the Collection one at a time
- Once all records have been added to the Collection, the Graph will be terminated after a configurable buffer time (1 minute by default)
Configuring our Pipeline
In order to run this pipeline, you will have to make some changes to the pipeline:
In the Format API Request Javascript Operator, you should set your own values for openapi.header_params.apiKey and openapi.query_params.realm

You can edit this code from within the Script View of the Format API Request Operator
If your Connection names are different to ARIBA_PROCUREMENT and ARIBA_HDI, then you will want to select those under Connection for the OpenAPI Client and SAP HANA Client respectively

Changing the Connection for the OpenAPI Client

Changing the Connection for the HANA Client
Check the Path values for the operators "Write Payload Flat File" and "Write Error Log". This will be where the pipeline will write the Flat File and API Error Logs respectively. If you'd like them to save elsewhere, edit that here

Setting the log paths
Finally, we'll want to set the Document Collection Schema name in the DocStoreComposer Operator. This is the Schema we noted earlier while setting up the Connections

View the Script for our DocStoreComposer Operator

Add the Schema to the DocStoreComposer Operator
Testing our Pipeline
Now we're ready to test our pipeline. Click on Save, then Run

Testing our Pipeline
Once our pipeline has completed successfully, we'll be able to see that our JSON Documents are stored within our Collection by checking in the Database Explorer. We can access this easily through Business Application Studio by clicking the icon next to our SAP HANA Project

Getting to the Database Explorer from Business Application Studio
We can see that our pipeline has been successful, and that 206 JSON Documents have been stored in our Collection

Our Collection contains 206 Documents
Wrap-Up
In this blog post we've walked through how we can use SAP Data Intelligence Cloud to extract data from SAP Ariba, before storing it in a collection in SAP HANA Cloud's Document Store
In the next blog post in this series, we will discuss how we can create SQL and Calculation Views on top of our Document Store Collection
In the third and final blog post in this series, we will use our Calculation View as a Live Data Model which we then visualize in an SAP Analytics Cloud Story
Other Resources
SAP Ariba | How to Create Applications and Consume the SAP Ariba APIs by ajmaradiaga (~30 minutes viewing time)
SAP Ariba | Developer Homepage
SAP HANA Document Store | SAP HANA Document Store Guide
SAP HANA Document Store | Spotlight: SAP HANA Cloud JSON Document Store by laura.nevin (2 minute read)
SAP Data Intelligence Cloud | Introduction to the SAP Data Intelligence Cloud Modeler
SAP Data Intelligence Cloud | Modeling Guide for SAP Data Intelligence
JSON | Introducing JSON (short primer, technically-focused)
Special Thanks
This blog series has had a lot of input from my colleagues - any errors are mine not theirs. In particular, thanks go to the Cross Product Management - SAP HANA Database & Analytics team, Antonio Maradiaga, Bengt Mertens, Andrei Tipoe, Melanie de Wit and Shabana Samsudheen
Note: While I am an employee of SAP, any views/thoughts are my own, and do not necessarily reflect those of my employer
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Business Trends
113 -
Business Trends
10 -
Event Information
44 -
Event Information
2 -
Expert Insights
18 -
Expert Insights
23 -
Life at SAP
32 -
Product Updates
253 -
Product Updates
21 -
Technology Updates
82 -
Technology Updates
13
Related Content
- The Procurement Monthly - March 2024 in Spend Management Blogs by SAP
- Navigating the Data-Driven World of Procurement Analytics: The Roadmap to Achieving Best-In-Class St in Spend Management Blogs by SAP
- Boosting Business Success with Procurement Analytics: A Journey Paved with Numbers in Spend Management Blogs by SAP
- SAP Analytics for Cloud and SAP Ariba - Data Connections in Spend Management Q&A
- Suppliers should merge all electronic pipelines into an Omni-channel strategy. in Spend Management Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |