
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data and Analytics Showcase - Develop a Machin...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-12-2022
1:46 PM
The series of blog posts is written by Frank Gottfried, Christoph Morgen and Wei Han together.
Overview
In this blog post, we'll describe an end-to-end scenario, which demonstrates how to develop a SAP Cloud Programming Model (CAP) application in SAP Business Application Studio that leverages the machine learning capabilities (HANA PAL and APL library) from SAP HANA Cloud. Additionally, we'd like to showcase how our data and analytics solutions on SAP Business Technology Platform (SAP BTP) enable the collaboration between data scientist and app developer.
Following the upcoming sessions, you'll be able to:
- As data scientist: solve your business problem by exploring training/sample data located in a HANA database (e.g., HDI container), train and find out optimal machine learning models in Jupyter Notebook
- As data scientist: utilise hana-ml library to automatically generate related design-time artefacts such as ML training procedure and grant file in Jupyter Notebook
- As app developer: reuse the machine learning models from data scientist by importing all design-time artefacts into your CAP application in Business Application Studio and configure the database (db) module of your CAP project
- As app developer: develop a Node.js script for model inference (prediction procedure) in Business Application Studio and deploy the CAP project into BTP sub-account for consumption
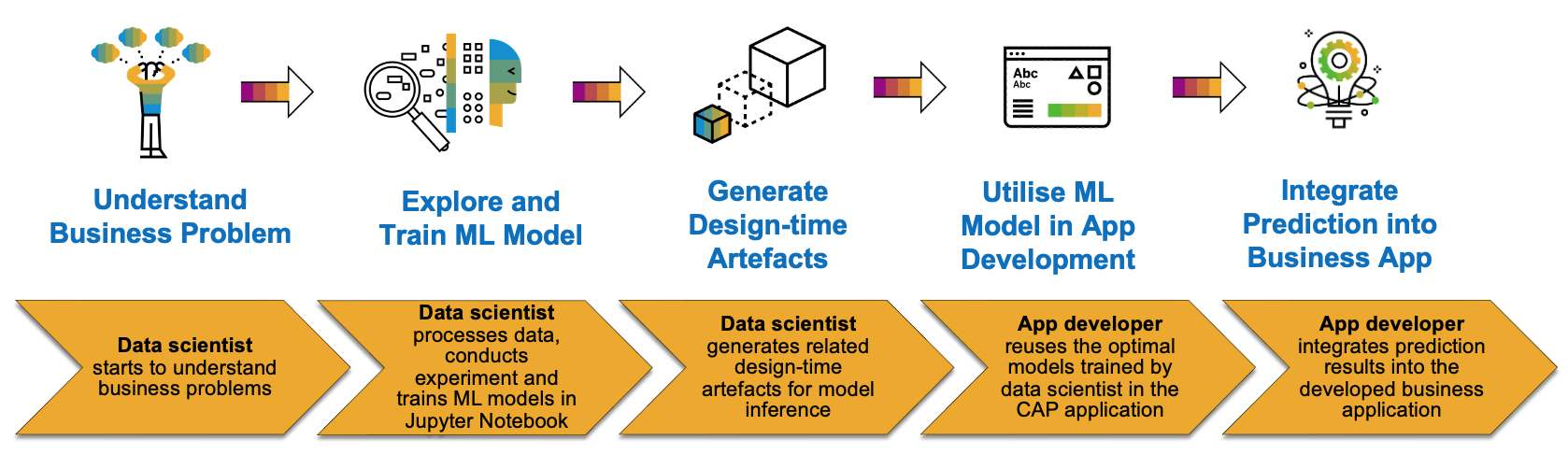
Use Case and Concept
As you may be aware, we have talked a lot how to combine prediction results from machine learning in your data modelling part and visualise the findings using dashboard or stories, e.g., in SAP Analytics Cloud. However, the use case described in this article is to demonstrate another essential application of machine learning - consume and leverage prediction results or findings directly in a business application, and further enhance with your own business logics.
Dataset
The dataset from one open website called “Tankerkönig“ is used in our case, which includes gasoline stations data in Germany and corresponding historical gasoline prices (E5, E10 and Diesel), all in CSV files. We use the stations and prices data within this website only for blog posting and demonstration purpose.
Scenario
We'd like to conduct massive time-series forecasting using the algorithm "Additive Model Time Series Analysis" from HANA PAL library to predict, for instance, the next 7-days Super E5 prices for gasoline stations in a specific area of Germany (e.g., Rhein-Neckar area), based on historical prices data from the tankerkönig repository.
The following two different scenarios are prepared depending on the places where training data sets are stored and CAP application is running. The only difference between these two scenarios is only the configuration of user-provided service on BTP and artefacts of database module of CAP project (Step D in the solution map). You can refer to our sub blog posts in the implementation part for more details
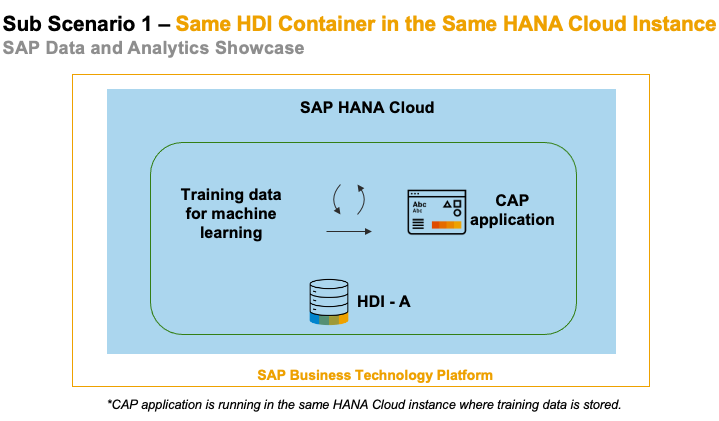
Sub-Scenario 1: Training Data and CAP Application Locate in the same HDI Container
The first scenario we described is a simple one, where your training data for machine learning is located in the same HDI container as your CAP project is running. In this case, you don't need to access data from another schema of HANA Cloud instance.
Sub-Scenario 2: Training Data and CAP Application Locate in Different HDI Containers
The second scenario is more complex than the above one. It is quite often that the training data used for machine learning is located in a different place where your business application (test data) is running. As shown in the below figure, our training data for machine learning is stored in a HDI container (called HDI-A), whereas our CAP application is running under another container (HDI-B). HDI-A and HDI-B belong to the same HANA Cloud instance.

Solution Map and Implementation
Now let’s have a look at the below technical architecture and implementation steps. No matter where your training data is located, our approach follows in general 5 steps:
Blog 1 - Machine Learning (Step A - Step C)
Data scientist accesses training data, explores training data and finds out the optimal machine learning models via Jupyter notebook. Data scientist uses the hana-ml library to generate design-time artefacts (e.g., hana procedure, roles, synonyms) and pushes them to GitHub repository.
Blog 2 - Application Development (Step D - Step E)
App developer imports required artefacts into CAP project and configures the database module. App developer further implements logic to call trained ML model and get prediction results back in business application.

Useful Concept
1. SAP HANA Cloud Predictive Analytics Library (PAL) - Python Client API for Machine Learning (hana-ml)
Data scientist develops python scripts in Jupyter Notebook and uses the algorithm "Additive Model Time Series Analysis" from hana-ml library for time series forecasting. To run hana procedure successfully in your CAP application, the roles AFL__SYS_AFL_AFLPAL_EXECUTE and AFL__SYS_AFL_AFLPAL_EXECUTE_WITH_GRANT_OPTION need to be granted to your database user. For example, runtime user of HDI-B container shall be able to run PAL procedures after granting the above-mentioned roles in our sub scenario2. Please refer to this document for more information.
The module hana_ml.artifacts.generators.hana within hana-ml library handles generation of required HANA design-time artefacts based on the provided base and consumption layer elements. These artefacts can incorporate into development projects in Business Application Studio and be deployed via HANA Deployment Infrastructure (HDI) into a SAP HANA system. The design-time files such as grants, roles, procedures, tables, and synonyms are generated automatically in our case.

2. Access a Classic Schema from SAP Business Application Studio
We need configure the database (db) module of our CAP project (running in HDI-B container) in SAP Business Application Studio and BTP, to access the training data located in HDI-A container. For this purpose, you need to know:
- how to create a user-provided service to access another database schema
- how to grant permissions to the technical users in your HDI container to access the database
This tutorial from SAP Developers website helps a lot. Please check the steps such as use-provided services, grant permissions to technical users and synonyms in the tutorial.

3. Call HANA Procedure from CAP Node.js Application in SAP Business Application Studio
To use machine learning models in your CAP application, we can expose hana procedures as a CAP service function under oData and implement logic for this service function in a Node.js script, calling the Stored Procedure from SAP HANA Cloud.
Example JavaScript codes to call the procedures in CAP project is shown in the below figure (Source: Create HANA Stored Procedure and Expose as CAP Service Function (SAP HANA Cloud)). You can check the full tutorials for more details.

Conclusion
We hope this blog post could give you a comprehensive overview about - how to develop a machine learning application, by using capabilities of SAP HANA Cloud, SAP Cloud Application Programming Model, SAP Business Application Studio and SAP Business Technology Platform. Thank you for your time, and please stay tuned and curious about our upcoming blog posts!
At the very end, I would like to say thank you to my colleagues Frank Gottfried and Christoph Morgen to bring this great approach and make this end-to-end demo story happen together!
We highly appreciate for all your feedbacks and comments! In case you have any questions, please do not hesitate to ask in the Q&A area as well.
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
293 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- Onboarding Users in SAP Quality Issue Resolution in Technology Blogs by SAP
- Improving Time Management in SAP S/4HANA Cloud: A GenAI Solution in Technology Blogs by SAP
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Embracing TypeScript in SAPUI5 Development in Technology Blogs by Members
- ABAP Cloud Developer Trial 2022 Available Now in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 14 | |
| 13 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 |