The Inline declaration provides an effortless way to create data objects and better readability to code readers. Since SAP NetWeaver ABAP 7.4 introduced this new feature, it has been the preferred way over explicit data declaration.
We will always have to consider the data volume for the internal tables to avoid possible performance issues. It is more critical when we use the inline declaration because it creates only standard-type tables. Performance issues happen if the internal table created by the inline declaration contains many rows and we access it inside a loop.
A common performance issue
select * from dd03l FOR ALL ENTRIES IN @lt_tables
where tabname = @lt_tables-tabname
into table @data(lt_tabfields).
loop at lt_tables ASSIGNING FIELD-SYMBOL(<fs_tab>).
loop at lt_tabfields ASSIGNING FIELD-SYMBOL(<fs_tabfields>)
where tabname = <fs_tab>-tabname.
endloop.
endloop.
The internal table LT_TABFIELDS is created with the inline declaration at the SELECT statement. As we can see in the debugger, the table type is the standard and it does not have any keys.
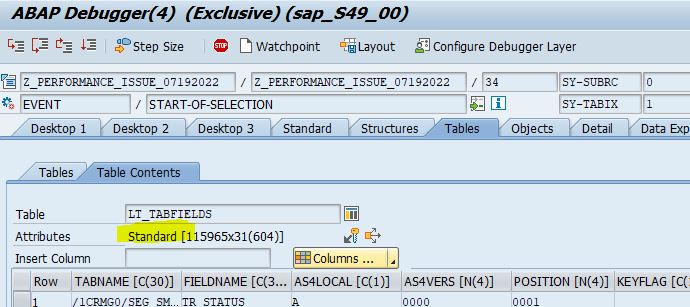

Suppose we have to access the internal table inside a loop. In that case, we will have to define the internal table explicitly as sorted or hashed types or with secondary sorted keys to avoid possible performance issues.
Explicit data declaration example #1 (with sorted type internal table)
data : lt_tabfields2 type sorted table of dd03l with non-UNIQUE KEY tabname.
loop at lt_tables ASSIGNING FIELD-SYMBOL(<fs_tab>).
loop at lt_tabfields ASSIGNING FIELD-SYMBOL(<fs_tabfields>)
where tabname = <fs_tab>-tabname.
endloop.
endloop.
Explicit data declaration example #2 (with secondary sorted key)
data : lt_tabfields type table of dd03l with non-UNIQUE sorted KEY k1 COMPONENTS tabname.
loop at lt_tables ASSIGNING FIELD-SYMBOL(<fs_tab>).
loop at lt_tabfields ASSIGNING FIELD-SYMBOL(<fs_tabfields>)
using key k1 where tabname = <fs_tab>-tabname.
endloop.
endloop.
Response time comparison for the nested loop (test case : 10K rows in the LT_TABLES, 115K rows in the LT_TABFIELDS)
Standard type (via inline declaration) |
147,219ms |
Sorted type (via explicit declaration) |
81ms |
Standard type with secondary key (via explicit declaration) |
134ms |
As you can see in the runtime comparison above, the inline declaration can cause performance issues when the developer uses it without considering the future data volume. For better performance, it's always recommended to use the code inspector (transaction SCI) before transporting the ABAP programs to the production system. The check variant will have to include the low-performance operation for standard type internal table to detect performance issues with the inline declaration.

Thank You For Reading, please share feedback and thoughts in a comment. And consider following the
ABAP Development environment topic and
jihoon.kim for future similar content.
