
- SAP Community
- Groups
- Interest Groups
- Artificial Intelligence and Machine Learning
- Blogs
- Build Your Own Model with TensorFlow in SAP AI Cor...
Artificial Intelligence and Machine Learning Blogs
Explore AI and ML blogs. Discover use cases, advancements, and the transformative potential of AI for businesses. Stay informed of trends and applications.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-28-2022
7:29 AM
I worked on this project with my colleagues gianluigi.bagnoli, stuart.clarke2, dayanand.karalkar2, yatsea.li, amagnani and jacobtan
In the first blog post of our series dedicated to AI & Sustainability, my colleague gianluigi.bagnoli introduced you to BAGNOLI & CO, a Milan-based Light Guide Plates (LGP) manufacturer, who is transforming its enterprise into a sustainable smart factory by reducing waste, and improving both the production efficiency and the workplace safety with the help of SAP AI Core, SAP AI Launchpad and SAP Analytics Cloud for Planning.
In the second blog post written by me, we have learnt the general end-to-end ML workflow a SAP Partner should follow to develop advanced custom AI solutions with SAP AI Core and SAP AI Launchpad.
Now in this blog post we will see in practice how this workflow can be applied to solve one of the main business challenges for BAGNOLI & CO.
First of all, let me spend a few words about the final products of our BAGNOLI & CO manufacturer. The light guide plate (LGP) is an optical product which can transform a line light source into a surface light source (see Fig. 1), with outstanding characteristics such as high luminous efficiency, luminance uniformity, long service life, energy conservation. Due to those excellent optical properties, LGPs are widely applied in liquid crystal display screens such as computer monitors, car navigations, etc.
So far so good, but as it usually happens, during the LGP’s production process, defects such as bright spots, material impurities, line scratches can occur (see Fig. 2). Those defects may affect the use of the devices, hence quality inspection is crucial during the production process. BAGNOLI & CO wants to abandon manual inspection, which is low-precision, inefficient and detrimental to the physical and mental health of employees, especially with the increasing demand for related equipment using LGPs.
In order to improve the efficiency and quality of the LGP production lines, some manufacturers used traditional visual inspection methods where features are generally hand-crafted by traditional image processing methods (such as morphological operations, histograms, etc.), and then defects are detected by formulated decision rules or learning-based methods (such as KNN, decision trees, SVM, and other classifiers). Unfortunately, since the LGP point distribution is uneven, and the size, shape, and brightness of the same kind of defects may vary a lot, the traditional computer vision methods cannot achieve a sufficient defect detection accuracy in these complex situations.
To overcome this issue, BAGNOLI & CO decided to take an innovative path and engaged a SAP golden partner to implement an AI solution based on deep learning algorithms, which can automatically learn more accurate and representative features from the LGP images that can assure a more accurate automatic inspection.
I will show you how the SAP partner acted in order to exploit the powerful feature expression ability of the deep learning methods for the detection of complex defects of the LGP products using SAP AI Core.
If traditional computer vision methods are not viable to implement an accurate automatic LGP inspection, the solution will still be found among the most advanced computer vision approaches. But before proceeding, let’s start from a very simple definition of computer vision:
From the engineering point of view, it seeks to automate tasks that the human visual system can do with the automatic extraction, analysis and understanding of useful information from a single image or a sequence of images.
Now, this is very interesting, but what are the most important tasks that computer vision can accomplish? Actually, there are many, and many of them are under our eyes every day though we don’t even think about them. Let’s make a brief and certainly incomplete list:
And I could cite many others…
In general, computer vision involves the development of a theoretical and algorithmic basis to achieve automatic visual understanding. Therefore, you can easily imagine that each of the tasks mentioned above, assume the existence of an underlying complex algorithm that most likely deals with deep learning. For this reason, we have witnessed great advancement of computer vision in the last decade, thanks to the availability of huge open datasets and powerful computing resources such as GPUs.
Now, among the tasks mentioned above, which one fits most for the BAGNOLI & CO business challenge? For sure we would like to differentiate good products from defective ones, task which a classification algorithm would be enough for. But, wouldn’t it be nicer, to have as much insight as possible about the defects? Such as the position, size and shape etc. which can help BAGNOLI & CO not only to get rid of defective products before they get shipped to customers, but also to distinguish severe defects from small imperfections that could still be sold at a lower price? Finally, through the analysis of defects shapes, manufacturers can gain insights on the general health of the production line. If Mr. BAGNOLI (or rather his computer) starts to see a bunch of products suddenly affected by scratches on that corner, with a recurrent pattern, maybe he can conclude his LGP cutting machine needs a check-up.
So image segmentation looks like the most suitable computer vision technique for our use case. Actually what we are interested in is a particular flavor of segmentation, that is “semantic segmentation” that refers to the classification of pixels in an image into semantic classes. Pixels belonging to a particular class are simply classified to that class with no other information or context taken into consideration. This is enough to achieve our goal, though there are many other sophisticated incarnations of image segmentation. Fig. 4 shows the expected prediction of our image segmentation model.
But what is the algorithmic construction powering the most advanced image segmentation techniques? Many recent and successful methods are based on deep learning algorithms involving Convolutional Neural Networks (CNN) and have proven in time their capabilities in computer vision tasks.
A Convolutional Neural Network is a class of neural networks that specializes in processing data that has a grid-like topology, such as an image. In fact, through a computer’s eyes, an image is nothing but a series of numbers arranged in a grid-like fashion, each number representing the brightness of a particular pixel.
A Convolutional Neural Network (see Fig. 5) takes an input image and tries to assign importance to various aspects in the image that can differentiate one image from the other one.
The architecture of a CNN is analogous to that of the connectivity pattern of neurons in the human brain and was inspired by the organization of the visual cortex. Individual neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. A collection of such fields overlaps to cover the entire visual area. So similarly, the first objective of the convolution operation is capturing the low-level features such as edges, colour, gradient orientation, etc. With added layers, the architecture adapts to the high-level features as well, giving a network which has the wholesome understanding of the image.
CNN is crucial for understanding the basic features of an image, but how are they used for example to achieve our image segmentation?
Deep artificial neural networks that perform segmentation typically use an encoder-decoder structure where the encoder is followed by a bottleneck and a decoder or upsampling layers directly from the bottleneck.
Encoder decoder architectures for semantic segmentation became popular with the onset of works like SegNet (by Badrinarayanan et. al.) in 2015.
SegNet proposes the use of a combination of convolutional and downsampling blocks to squeeze information into a bottleneck and form a representation of the input. The decoder then reconstructs input information to form a segment map highlighting regions on the input and grouping them under their classes.
SegNet was accompanied by the release of another independent segmentation work at the same time, U-Net (by Ronnerberger et. al.) which first introduced skip connections in Deep Learning as a solution for the loss of information observed in downsampling layers of typical encoder-decoder networks. Skip connections are connections that go from the encoder directly to the decoder without passing through the bottleneck (see Fig. 6).
So the U-Net architecture is exactly what we need and what we will implement in our solution for BAGNOLI & CO within SAP AI Core.
It is worth saying that training CNN’s and models involving several convolutional layers is time consuming and expensive process. You need large dataset of images and a long trial and error process to succeed. Many frameworks (such as Keras, Tensorflow, PyTorch) offer prebuilt or pre-trained networks that can be used as a starting point. For instance, for our defect detection task we decided to use MobileNetV2 as encoder, in-order to learn robust features and reduce the number of trainable parameters. MobileNetV2 network was trained on more than a million images from the ImageNet database. The network has learned rich feature representations for a wide range of images, but we freed some layers in order to accommodate also the specific features of our LGP images.
For the decoder part, we decided to use an upsample block already implemented in the conditional generative adversarial network (cGAN) called pix2pix and available in the TensorFlow examples repository.
Described above is the procedure for developing custom models with open-source tools usually followed in many contexts. You can appreciate the benefits and freedom of this approach that allows you to use what is available in the open-source community. In the following I will show you with our defect detection use case, how it is possible to productize any custom model designed with open-source tools into a complex AI solution with SAP AI Core.
In general, the workflow to build a predictive model has at least the following main steps:
I will go through each of the points above from the perspective of BAGNOLI & CO and SAP AI Core.
Going back to our LGP factory, let’s imagine putting a camera at the end of the production line (see Fig. 7) and storing the images in our hyperscaler object store.
The images will show the typical dot pattern responsible for the scatter the light emitted from the light sources. As explained in the beginning, defects might occur on the surface, so we have examples of normal items (upper row in Fig. 2) and defected ones (lower row in Fig. 2).
Is the information carried out by those images enough for training an image segmentation algorithm based on deep learning? Actually, for a supervised approach like the one we are following the answer is no. Since we want to train our DNN to correctly classify each pixel, we need to provide a ground truth that in our case is an additional map for each LGP image reporting the class each pixel belongs to in the original image: 1 if the pixel corresponds to a defect, 0 in all the other cases. We refer to this map with the term “mask” and the task of preparing it is known as image annotation (see Fig. 10).
In general, the annotation task can be taken care of through various open source or licensed software available on the market. We can assume the SAP golden partner had followed the guidance of one of BAGNOLI & CO experienced quality inspectors. Or, alternatively, that it outsourced this tedious and time-consuming task to one of the companies specialized in image annotation.
What about pre-processing? Data pre-processing is a process of cleaning or manipulating the raw data to achieve more accurate results from the applied model in machine learning and deep learning projects. In deep learning tasks for computer vision, pre-processing often consists in applying a set of traditional image transformations that can include resizing, rotations, color or brightness corrections, denoising, etc. These operations can greatly enhance the model performance. In the development of the AI solution for BAGNOLI & CO I applied some image transformation, such as histogram equalization and dilation, to highlight the defects and facilitate the learning process of our model.
The design of the model architecture, that I have described in the previous paragraph is crucial. The architecture can be also very complex, and therefore it may be composed of several parts each corresponding to as many modules. So coding is fundamental and to move to SAP AI Core we have to make sure we have designed our pipeline and the relative code, structured in one or many modules.
As you may remember from the previous blog post, templates are used in SAP AI Core for defining the ML pipelines and the serving application in terms of Docker images. Focusing on the training of a model, the training template is the place where your pipeline has to be defined: every step can be declared there, identified by a specific name and linked to the corresponding Docker image. This means every piece of code you have written has to be converted to a Docker image.
An interesting aspect here is that both Docker images and templates are agnostic to the programming language used for coding, so basically you are free to code in your preferred programming language. For example, I have chosen python.
If you remember the ML workflow in SAP AI Core (see Fig. 9), assuming that all the initial configurations are already done (step 0 and 1), we are now talking about step 2.1 and 2.2. In our use case I planned to have a pipeline composed by just one step, therefore just one dockerized python class that performs all the main tasks, such as reading the data, preprocess them, build and train our image segmentation model, i.e. the modified U-Net described above. You can see how my python code and training template look at the following links: training python class and training template.
Following the ML workflow, at this point in order to execute the training of the segmentation model on SAP AI Core, I just need to create a training configuration (step 2.4) that binds together the LGP dataset and the executable defined by our training template. Once the configuration is created, I can execute the training (step 2.5) by means of a simple API and after a while it will return our trained model, saved automatically on the registered hyperscaler object store (step 3).
After a training it is fundamental to evaluate the model quality and accuracy.
When training a model in SAP AI Core you can register as a metric object whatever information you need to evaluate your model performance. This way, for every execution, every version of the model and configuration you have tried, the performance of the model is safely stored and can be easily accessed by means of a simple API call.
But what is the most suitable metric to evaluate the accuracy of an image segmentation model? The Intersection-Over-Union (IoU) is sometimes used in semantic segmentation. Simply put, IoU estimates how well the defect reconstructed by the algorithm overlaps with the real defect. So by construction this metric ranges from 0 to 1 with 0 signifying no overlap and 1 signifying perfectly overlapping segmentation.
In Fig. 10 you can see a plot depicting the evolution of the IoU metric at each iteration of our U-Net training obtained by simply plotting the values retrieved from SAP AI Core.
In the previous blog post, I have explained how to deploy a custom model in SAP AI Core, so we know we need to develop a web application that serves the inference requests coming through the exposed endpoint.
But how is the web application workflow going to change to fit our defect detection use case? We can refer to Fig. 11. In this scheme you can see an image of a defected LGP device is provided as input in the form of a binary string. Then internally the application proceeds with decoding and applying to it the same pre-processing adopted during the training. At this point, the application running in SAP AI Core connects again to the hyperscaler object store, download the trained model and then it applies it to the input image.
The result of this procedure is the segmentation map I have previously described that conveys information about those pixels identified as a defect (if any) and the percentage of defected area. The final step is the preparation of the response that includes the mask encoded in binary string and the percentage of defected area of the item under inspection.
You can inspect the web application code we have developed following the workflow above for BAGNOLI & CO at this link.
As I did for the training, I need to convert this code to a Docker image and then I need to write a serving template configuration file to provide all the parameters to manage it in the SAP AI Core Kubernetes infrastructure.
Referring to Fig. 9 we have completed steps 4.1 and 4.2. To deliver our segmentation model, I have just to prepare a serving configuration (step 4.3) that tells SAP AI Core what to execute and using which artifact, and then start the model server (step 4.4). So, doing this, I have finally deployed our model. As a result, I got its inference URL from SAP AI Core. As you will see in the next blog posts, that will be the key for integrating and consuming our image segmentation model.
In this blog post we have learnt how to develop a custom AI solution for automating the product inspection for our manufacturer BAGNOLI & CO with AI Core and AI Launchpad. Please, don't forget to share your feedback or thoughts in a comment.
In the next blog post, we will learn how to develop a custom Deep Learning model involving CNNs in Tensorflow for sound-based proactive maintenance on the equipment in BAGNOLI & CO with the ML end-to-end workflow in SAP AI Core.
Just as a reminder, here’s the full program of our journey:
If you're a partner and would like to learn more, don't forget to register to our upcoming bootcamps on sustainability-on-BTP, where this case is going to be explained and detailed. Here you can find the dates and the registration links:
SAP HANA Academy has prepared an interesting series of videos that provides deeper dive content about AI & Sustainability based on the bootcamp storyline. If you want to learn more about the BAGNOLI & CO automated defect detection implemented in SAP AI Core that I have described in this blog post, please, do check this link.
In the first blog post of our series dedicated to AI & Sustainability, my colleague gianluigi.bagnoli introduced you to BAGNOLI & CO, a Milan-based Light Guide Plates (LGP) manufacturer, who is transforming its enterprise into a sustainable smart factory by reducing waste, and improving both the production efficiency and the workplace safety with the help of SAP AI Core, SAP AI Launchpad and SAP Analytics Cloud for Planning.
In the second blog post written by me, we have learnt the general end-to-end ML workflow a SAP Partner should follow to develop advanced custom AI solutions with SAP AI Core and SAP AI Launchpad.
Now in this blog post we will see in practice how this workflow can be applied to solve one of the main business challenges for BAGNOLI & CO.
BAGNOLI & CO business challenge: automating defect detection
First of all, let me spend a few words about the final products of our BAGNOLI & CO manufacturer. The light guide plate (LGP) is an optical product which can transform a line light source into a surface light source (see Fig. 1), with outstanding characteristics such as high luminous efficiency, luminance uniformity, long service life, energy conservation. Due to those excellent optical properties, LGPs are widely applied in liquid crystal display screens such as computer monitors, car navigations, etc.

Figure 1: Small Light guide plate prototype.
So far so good, but as it usually happens, during the LGP’s production process, defects such as bright spots, material impurities, line scratches can occur (see Fig. 2). Those defects may affect the use of the devices, hence quality inspection is crucial during the production process. BAGNOLI & CO wants to abandon manual inspection, which is low-precision, inefficient and detrimental to the physical and mental health of employees, especially with the increasing demand for related equipment using LGPs.

Figure 2: Examples of LGP surfaces without defects (upper row) and with defects (lower row).
In order to improve the efficiency and quality of the LGP production lines, some manufacturers used traditional visual inspection methods where features are generally hand-crafted by traditional image processing methods (such as morphological operations, histograms, etc.), and then defects are detected by formulated decision rules or learning-based methods (such as KNN, decision trees, SVM, and other classifiers). Unfortunately, since the LGP point distribution is uneven, and the size, shape, and brightness of the same kind of defects may vary a lot, the traditional computer vision methods cannot achieve a sufficient defect detection accuracy in these complex situations.
To overcome this issue, BAGNOLI & CO decided to take an innovative path and engaged a SAP golden partner to implement an AI solution based on deep learning algorithms, which can automatically learn more accurate and representative features from the LGP images that can assure a more accurate automatic inspection.
I will show you how the SAP partner acted in order to exploit the powerful feature expression ability of the deep learning methods for the detection of complex defects of the LGP products using SAP AI Core.
What is computer vision?
If traditional computer vision methods are not viable to implement an accurate automatic LGP inspection, the solution will still be found among the most advanced computer vision approaches. But before proceeding, let’s start from a very simple definition of computer vision:
From the engineering point of view, it seeks to automate tasks that the human visual system can do with the automatic extraction, analysis and understanding of useful information from a single image or a sequence of images.
Now, this is very interesting, but what are the most important tasks that computer vision can accomplish? Actually, there are many, and many of them are under our eyes every day though we don’t even think about them. Let’s make a brief and certainly incomplete list:
- Image classification (Fig. 3), that deals with comprehending the image as a whole, by trying to identify classes of objects within the image;
- Object detection (Fig. 3) that refers to a set of techniques that allow a computer to identify and locate an object of particular interest from still images or videos;
- Image segmentation (Fig. 3) that consists of partitioning an image into multiple parts or regions, often based on the characteristics of the pixels in the image;
- Image generation that consists of generating new images from an existing dataset;
- Image restoration that refers to the restoration or the reconstruction of faded and old image hard copies that have been captured and stored in an improper manner, leading to quality loss of the image.
And I could cite many others…

Figure 3: Examples of image classification, detection and segmentation.
In general, computer vision involves the development of a theoretical and algorithmic basis to achieve automatic visual understanding. Therefore, you can easily imagine that each of the tasks mentioned above, assume the existence of an underlying complex algorithm that most likely deals with deep learning. For this reason, we have witnessed great advancement of computer vision in the last decade, thanks to the availability of huge open datasets and powerful computing resources such as GPUs.
Now, among the tasks mentioned above, which one fits most for the BAGNOLI & CO business challenge? For sure we would like to differentiate good products from defective ones, task which a classification algorithm would be enough for. But, wouldn’t it be nicer, to have as much insight as possible about the defects? Such as the position, size and shape etc. which can help BAGNOLI & CO not only to get rid of defective products before they get shipped to customers, but also to distinguish severe defects from small imperfections that could still be sold at a lower price? Finally, through the analysis of defects shapes, manufacturers can gain insights on the general health of the production line. If Mr. BAGNOLI (or rather his computer) starts to see a bunch of products suddenly affected by scratches on that corner, with a recurrent pattern, maybe he can conclude his LGP cutting machine needs a check-up.
So image segmentation looks like the most suitable computer vision technique for our use case. Actually what we are interested in is a particular flavor of segmentation, that is “semantic segmentation” that refers to the classification of pixels in an image into semantic classes. Pixels belonging to a particular class are simply classified to that class with no other information or context taken into consideration. This is enough to achieve our goal, though there are many other sophisticated incarnations of image segmentation. Fig. 4 shows the expected prediction of our image segmentation model.

Figure 4: Example of an input image and the expected predictions from our image segmentation model.
Convolutional neural network is the key…
But what is the algorithmic construction powering the most advanced image segmentation techniques? Many recent and successful methods are based on deep learning algorithms involving Convolutional Neural Networks (CNN) and have proven in time their capabilities in computer vision tasks.
A Convolutional Neural Network is a class of neural networks that specializes in processing data that has a grid-like topology, such as an image. In fact, through a computer’s eyes, an image is nothing but a series of numbers arranged in a grid-like fashion, each number representing the brightness of a particular pixel.
A Convolutional Neural Network (see Fig. 5) takes an input image and tries to assign importance to various aspects in the image that can differentiate one image from the other one.
The architecture of a CNN is analogous to that of the connectivity pattern of neurons in the human brain and was inspired by the organization of the visual cortex. Individual neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. A collection of such fields overlaps to cover the entire visual area. So similarly, the first objective of the convolution operation is capturing the low-level features such as edges, colour, gradient orientation, etc. With added layers, the architecture adapts to the high-level features as well, giving a network which has the wholesome understanding of the image.

Figure 5: A typical CNN for image classification.
… but U-Net is our architecture
CNN is crucial for understanding the basic features of an image, but how are they used for example to achieve our image segmentation?
Deep artificial neural networks that perform segmentation typically use an encoder-decoder structure where the encoder is followed by a bottleneck and a decoder or upsampling layers directly from the bottleneck.
Encoder decoder architectures for semantic segmentation became popular with the onset of works like SegNet (by Badrinarayanan et. al.) in 2015.
SegNet proposes the use of a combination of convolutional and downsampling blocks to squeeze information into a bottleneck and form a representation of the input. The decoder then reconstructs input information to form a segment map highlighting regions on the input and grouping them under their classes.
SegNet was accompanied by the release of another independent segmentation work at the same time, U-Net (by Ronnerberger et. al.) which first introduced skip connections in Deep Learning as a solution for the loss of information observed in downsampling layers of typical encoder-decoder networks. Skip connections are connections that go from the encoder directly to the decoder without passing through the bottleneck (see Fig. 6).

Figure 6: Our modified U-Net architecture.
So the U-Net architecture is exactly what we need and what we will implement in our solution for BAGNOLI & CO within SAP AI Core.
It is worth saying that training CNN’s and models involving several convolutional layers is time consuming and expensive process. You need large dataset of images and a long trial and error process to succeed. Many frameworks (such as Keras, Tensorflow, PyTorch) offer prebuilt or pre-trained networks that can be used as a starting point. For instance, for our defect detection task we decided to use MobileNetV2 as encoder, in-order to learn robust features and reduce the number of trainable parameters. MobileNetV2 network was trained on more than a million images from the ImageNet database. The network has learned rich feature representations for a wide range of images, but we freed some layers in order to accommodate also the specific features of our LGP images.
For the decoder part, we decided to use an upsample block already implemented in the conditional generative adversarial network (cGAN) called pix2pix and available in the TensorFlow examples repository.
Described above is the procedure for developing custom models with open-source tools usually followed in many contexts. You can appreciate the benefits and freedom of this approach that allows you to use what is available in the open-source community. In the following I will show you with our defect detection use case, how it is possible to productize any custom model designed with open-source tools into a complex AI solution with SAP AI Core.
How to bring our custom model in SAP AI Core?
In general, the workflow to build a predictive model has at least the following main steps:
- data collection, data exploration, preparation and pre-processing;
- research of a model that best fits the type of data and the business use case;
- model training and testing;
- evaluation of the results;
- model serving and deployment.
I will go through each of the points above from the perspective of BAGNOLI & CO and SAP AI Core.
Collecting and preparing the data in BAGNOLI & CO
Going back to our LGP factory, let’s imagine putting a camera at the end of the production line (see Fig. 7) and storing the images in our hyperscaler object store.

Figure 7: The BAGNOLI & CO production line showing the mounted image camera and sound sensors.
The images will show the typical dot pattern responsible for the scatter the light emitted from the light sources. As explained in the beginning, defects might occur on the surface, so we have examples of normal items (upper row in Fig. 2) and defected ones (lower row in Fig. 2).
Is the information carried out by those images enough for training an image segmentation algorithm based on deep learning? Actually, for a supervised approach like the one we are following the answer is no. Since we want to train our DNN to correctly classify each pixel, we need to provide a ground truth that in our case is an additional map for each LGP image reporting the class each pixel belongs to in the original image: 1 if the pixel corresponds to a defect, 0 in all the other cases. We refer to this map with the term “mask” and the task of preparing it is known as image annotation (see Fig. 10).
In general, the annotation task can be taken care of through various open source or licensed software available on the market. We can assume the SAP golden partner had followed the guidance of one of BAGNOLI & CO experienced quality inspectors. Or, alternatively, that it outsourced this tedious and time-consuming task to one of the companies specialized in image annotation.
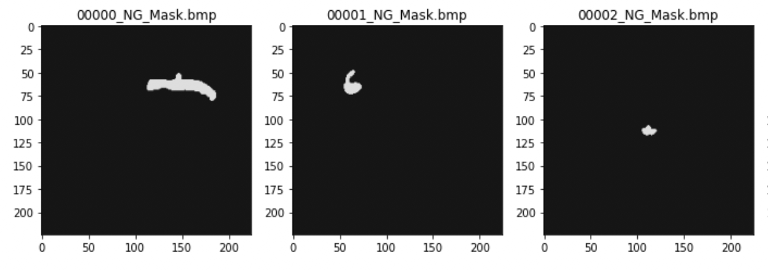
Figure 10: Masks corresponding to the defected items in Fig. 2.
What about pre-processing? Data pre-processing is a process of cleaning or manipulating the raw data to achieve more accurate results from the applied model in machine learning and deep learning projects. In deep learning tasks for computer vision, pre-processing often consists in applying a set of traditional image transformations that can include resizing, rotations, color or brightness corrections, denoising, etc. These operations can greatly enhance the model performance. In the development of the AI solution for BAGNOLI & CO I applied some image transformation, such as histogram equalization and dilation, to highlight the defects and facilitate the learning process of our model.
Research the best model for our business use case and train it with SAP AI Core
The design of the model architecture, that I have described in the previous paragraph is crucial. The architecture can be also very complex, and therefore it may be composed of several parts each corresponding to as many modules. So coding is fundamental and to move to SAP AI Core we have to make sure we have designed our pipeline and the relative code, structured in one or many modules.
As you may remember from the previous blog post, templates are used in SAP AI Core for defining the ML pipelines and the serving application in terms of Docker images. Focusing on the training of a model, the training template is the place where your pipeline has to be defined: every step can be declared there, identified by a specific name and linked to the corresponding Docker image. This means every piece of code you have written has to be converted to a Docker image.
An interesting aspect here is that both Docker images and templates are agnostic to the programming language used for coding, so basically you are free to code in your preferred programming language. For example, I have chosen python.
If you remember the ML workflow in SAP AI Core (see Fig. 9), assuming that all the initial configurations are already done (step 0 and 1), we are now talking about step 2.1 and 2.2. In our use case I planned to have a pipeline composed by just one step, therefore just one dockerized python class that performs all the main tasks, such as reading the data, preprocess them, build and train our image segmentation model, i.e. the modified U-Net described above. You can see how my python code and training template look at the following links: training python class and training template.

Figure 9: End-to-end ML workflow in SAP AI Core.
Following the ML workflow, at this point in order to execute the training of the segmentation model on SAP AI Core, I just need to create a training configuration (step 2.4) that binds together the LGP dataset and the executable defined by our training template. Once the configuration is created, I can execute the training (step 2.5) by means of a simple API and after a while it will return our trained model, saved automatically on the registered hyperscaler object store (step 3).
How to evaluate the model accuracy in SAP AI Core?
After a training it is fundamental to evaluate the model quality and accuracy.
When training a model in SAP AI Core you can register as a metric object whatever information you need to evaluate your model performance. This way, for every execution, every version of the model and configuration you have tried, the performance of the model is safely stored and can be easily accessed by means of a simple API call.
But what is the most suitable metric to evaluate the accuracy of an image segmentation model? The Intersection-Over-Union (IoU) is sometimes used in semantic segmentation. Simply put, IoU estimates how well the defect reconstructed by the algorithm overlaps with the real defect. So by construction this metric ranges from 0 to 1 with 0 signifying no overlap and 1 signifying perfectly overlapping segmentation.
In Fig. 10 you can see a plot depicting the evolution of the IoU metric at each iteration of our U-Net training obtained by simply plotting the values retrieved from SAP AI Core.

Figure 10: Evolution of the IoU metrics vs. training iterations (epochs) for the training and validation samples.
Serving and deploy our custom model in SAP AI Core
In the previous blog post, I have explained how to deploy a custom model in SAP AI Core, so we know we need to develop a web application that serves the inference requests coming through the exposed endpoint.
But how is the web application workflow going to change to fit our defect detection use case? We can refer to Fig. 11. In this scheme you can see an image of a defected LGP device is provided as input in the form of a binary string. Then internally the application proceeds with decoding and applying to it the same pre-processing adopted during the training. At this point, the application running in SAP AI Core connects again to the hyperscaler object store, download the trained model and then it applies it to the input image.
The result of this procedure is the segmentation map I have previously described that conveys information about those pixels identified as a defect (if any) and the percentage of defected area. The final step is the preparation of the response that includes the mask encoded in binary string and the percentage of defected area of the item under inspection.

Figure 11: Serving application workflow for the defect detection use case.
You can inspect the web application code we have developed following the workflow above for BAGNOLI & CO at this link.
As I did for the training, I need to convert this code to a Docker image and then I need to write a serving template configuration file to provide all the parameters to manage it in the SAP AI Core Kubernetes infrastructure.
Referring to Fig. 9 we have completed steps 4.1 and 4.2. To deliver our segmentation model, I have just to prepare a serving configuration (step 4.3) that tells SAP AI Core what to execute and using which artifact, and then start the model server (step 4.4). So, doing this, I have finally deployed our model. As a result, I got its inference URL from SAP AI Core. As you will see in the next blog posts, that will be the key for integrating and consuming our image segmentation model.
What’s next?
In this blog post we have learnt how to develop a custom AI solution for automating the product inspection for our manufacturer BAGNOLI & CO with AI Core and AI Launchpad. Please, don't forget to share your feedback or thoughts in a comment.
In the next blog post, we will learn how to develop a custom Deep Learning model involving CNNs in Tensorflow for sound-based proactive maintenance on the equipment in BAGNOLI & CO with the ML end-to-end workflow in SAP AI Core.
Just as a reminder, here’s the full program of our journey:
- An overview of sustainability on top of SAP BTP
- Introduction of end-to-end ML ops with SAP AI Core
- BYOM with TensorFlow in SAP AI Core for Defect Detection (this blog post)
- BYOM with TensorFlow in SAP AI Core for sound-based Predictive Maintenance
- Embedding Intelligence and Sustainability into Custom Applications on SAP BTP
- Maintenance Cost Budgeting & Sustainability Planning with SAP Analytics Cloud
If you're a partner and would like to learn more, don't forget to register to our upcoming bootcamps on sustainability-on-BTP, where this case is going to be explained and detailed. Here you can find the dates and the registration links:
| Bootcamp | Session 1 | Session 2 | Session 3 | Registration |
| NA / LAC | June 23rd 11:00AM EST | June 30th 11:00AM EST | July 7th 11:00AM EST | Registration |
| EMEA / MEE | June 21st 09:00AM CET | June 28th 09:00AM CET | July 5th 09:00AM CET | Registration |
| APJ | July 6th 10:00AM SGT | July 13th 10:00AM SGT | July 20th 10:00AM SGT | Registration |
Additional resources
SAP HANA Academy has prepared an interesting series of videos that provides deeper dive content about AI & Sustainability based on the bootcamp storyline. If you want to learn more about the BAGNOLI & CO automated defect detection implemented in SAP AI Core that I have described in this blog post, please, do check this link.
- SAP Managed Tags:
- Artificial Intelligence
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Agents
3 -
AI
5 -
AI Launchpad
2 -
Artificial Intelligence
2 -
Artificial Intelligence (AI)
3 -
Brainstorming
1 -
BTP
1 -
Business AI
2 -
Business Trends
1 -
Cloud Foundry
1 -
Data and Analytics (DA)
1 -
Design and Engineering
1 -
forecasting
1 -
GenAI
1 -
Generative AI
4 -
Generative AI Hub
4 -
Graph
1 -
Language Models
1 -
LlamaIndex
1 -
LLM
2 -
LLMs
2 -
Machine Learning
1 -
Machine learning using SAP HANA
1 -
Mistral AI
1 -
NLP (Natural Language Processing)
1 -
open source
1 -
OpenAI
1 -
Python
2 -
RAG
2 -
Retrieval Augmented Generation
1 -
SAP Build Process Automation
1 -
SAP HANA
1 -
SAP HANA Cloud
1 -
User Experience
1 -
user interface
1 -
Vector Database
3 -
Vector DB
1 -
Vector Similarity
1
Top kudoed authors
| User | Count |
|---|---|
| 3 | |
| 3 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |