
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Distributed data and cross database access in hybr...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member23
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-13-2022
8:22 AM
Introduction
It's been almost two years since my last post about XSUAA and therefore I thought it might be the right time to write about another topic that is happening in a lot of our applications within SAP IES (also known as SAP IT): distributed data.
Just as a disclaimer. The content you see here is approximately one year old and some things might already be outdated at the time of writing. What you see here is the result of a longer presentation to my team for best practices and options to tackle distributed data in hybrid system architectures using native functionalities of SAP HANA.
Another disclaimer: I AM BY FAR neither a database expert nor an SAP HANA database expert. To be honest, I try to avoid databases as much as possible, stick with application code and design, and rely on database abstraction. Yeah. I make it short: I hate databases 🙂
But the good thing is that with services like SAP HANA Cloud (https://discovery-center.cloud.sap/serviceCatalog/sap-hana-cloud?region=all) most of the work is done by others - knowing it better than me - and you/I as an architect and developer can focus on better things - or at least we can try. And there is also the wonderful hana.academyhelping with most of the topics by offering a LOT of Youtube videos and tutorials driven by denys.kempen and his team (you will also find some linked videos throughout the blog post)
In addition to this:
The solution I provide here is not a "one size fits them all"-solution. ALWAYS decide on an individual base, what might be the best solution for your problem. There are way more patterns to solve distributed data than to connect two databases (eg the Saga pattern or the well known CQRS pattern)
Some people might also argue that connecting two databases has nothing to do with "Microservices", but that is not the truth.
Microservices are not about HTTP-API access only. It's about two independent deployable artifacts with well-defined bounded-context and clear interfaces.
Even on a database level, you can define these interfaces with database views and abstract the access to your tables on this level instead of defining them via HTTP. But that's another story 😉 Now let's go further with our concrete problem.
Problem statement
Most of the applications that we have to deal with need data from on-premise or other cloud applications. Let's assume we have an application that is showing orders within a list. Not that special. We have these orders in our own database and therefore can just query for them.

TargetApp with our own entities and SourceApp with foreign entities
The interesting part is that when we have a foreign reference pointing to an ID of an entity located in another app within our own data.
We can of course hide this reference in the UI and wait till the user makes a click on the entry and then query the API of the source app to retrieve the details of this ID. Works!
But what about the possibility of offering additional filters to our users to filter within this list and considering the foreign reference to the person directly in the entities of the provided list?
A simple query might be:
“Give me all orders from a person located in Germany && …”
I think we have more than 200 solutions for this problem, but let's talk about just a few of them that are most often obvious and used (may it be good or not).
Solution 1 of more than 200
"We can just query the source app to give us all persons in the country X and then filter in our own app at the moment the user changes the filter!"

Querying our SourceApp for each individual entry in the list
Yes. Of course, we can do it:
- Get all people (IDs) from SourceApp from the Country
- Now return all orders from our own app (TargetApp) where these IDs exist.
But this definitely has some drawbacks. The payload will be horrible and you will have to merge the persons with your orders in your business logic. The service might return thousands of IDs (IF it will allow this massive return of entities and is not limited by numbers per page).
Who the hell should do this????
Trust me. I have seen things...
...and I have DONE things.... 🙂
One of the arguments that most people come up with for a real-time solution is: "We always want to have the most recent data!".
Solution 2 of more than 200
As payload can explode with a high set of data another solution is to poll the source app on a regular basis and copy over the entities either in your own database or filling a cache like Redis (https://discovery-center.cloud.sap/serviceCatalog/redis-hyperscaler-option?region=all).
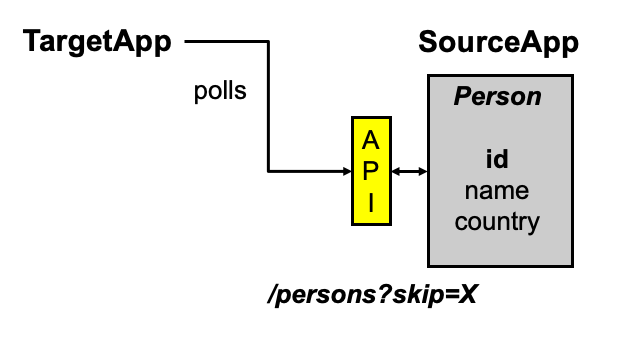
Polling our SourceApp on a regular basis to get all entities for further processing
This can be achieved by a scheduled service or any other external tool. Complexity will rise depending on the requirements like:
- Pull only delta changes - most often changes in the source API are needed for this
- Pull batches - same here even though oData/GraphQL might help here
- Introduce headers for better caching
Some words about these solutions
Even though it might be with some drawbacks this solution can work with your applications. IMHO we are once again back to the overall term that is shaping all landscapes in IT and software solutions: compromises.
For small applications and use cases, it is completely fine to just implement a scheduled service to fill a cache with a few hundred entities. This can be implemented fast and it will work. The same goes for the API query and the merging in the code. You might even just put the query entities in an in-memory cache like the one provided by Spring (https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache).
Options. Many of them. What most of these solutions have in common is the fact that they need custom implementation and dedicated business logic even though the only thing you want is to have a small set of data from a different source.
Both described solutions are most often used in business scenarios where we talk about third-party data ownage. This might happen using third-party services on the internet or even within the same company when security and non-functional requirements force access on an HTTP and application layer. But even under this circumstance, services often offer event-based access (like audit logs) to keep your payloads small and concentrate on delta changes instead of big database dumps on an HTTP level. But even then: Do not underestimate the complexity to keep up with delta queries, caching, and performance.
Solution using SAP HANA and virtual tables
First of all. Sorry that you had to read that much text to finally reach the chapter that is related to the subject of this blog post 🙂 The understanding of the two described solutions will help you with the available options SAP HANA is offering us here to take these approaches and just delegate them down to the database layer and use database functionalities to help us here. As already stated this is ONLY possible if you have the luxury to request access to the database.
SAP HANA is abstracting access to other databases with the use of virtual tables. These virtual tables can be mapped to certain adapters (using SDA) providing the individual implementation to remotely access the requested data.
In the following diagram, you can see certain components and the available options. Please visit the official help page to read more details about the components shown.

Components for remote connections - Source: https://help.sap.com/docs/HANA_CLOUD_DATABASE/477aa413a36c4a95878460696fcc8896/5885f0a35afe4ec698b00...
SDA vs SDI
Virtual tables are backed by two technologies that are living side-by-side with each other. SDA and SDI. SDI is an extension of SDA and needs further installations like a DP Agent (please read this great post (by a0286fd26e1645ac914b04a295fc5777 here: https://blogs.sap.com/2020/04/08/sdi-dp-agent-and-remote-source-configuration-in-hana-to-read-data-f...) running on a separate machine. SDI is offering MORE options than those that I describe here in this blog post.
Check out this blog post - even though it is a little bit older it is still valid - showing you roughly the differences between these technologies.
Another good overview can be found yet again on the official help page.
This blog post here will only concentrate on SDA features. It is sufficient for most of our use cases in hybrid landscape scenarios and works out of the box with SAP HANA Cloud databases and OnPrem >=SPS5. The good thing is that we do not need to install additional software (eg the DP Agent) and can just start. This is great. If you have more complex scenarios and need to do eg data transformation then SDI might be the better fit in conjunction with additional ELT software.
Adapters - SDA
Adapters are needed to establish a connection from one database to another. This table (see help page) shows you the available options. You can also see on this page that WAY MORE adapters are available if you are using SDI.

SDA Remote Sources - Source: https://help.sap.com/docs/HANA_CLOUD_DATABASE/477aa413a36c4a95878460696fcc8896/aba19dcf8466465a99a98...
So for our use-case and the interoperability between two HANA databases the hanaodbc adapter is completely fine. Adapters are therefore used to establish a so-called remote source pointing to another database. Remote sources are in general the meta-information for the adapters to set up a connection.
Remote Sources
Multiple steps are needed to maintain a correct remote source:
- When connecting HANA databases to each other it is important to import the certificate of the source database into the certification store. Otherwise, the adapter is not able to establish a secure end encrypted connection.A great video showing the certificate store and all the functions is the one below by denys.kempen
- In addition to this for HANA Cloud databases, it is also necessary to open the network firewall for further connections. This blog post by vitaliy.rudnytskiy shows how to do it: https://blogs.sap.com/2020/10/30/allow-connections-to-sap-hana-cloud-instance-from-selected-ip-addre...
- WIthin the SourceDB a technical user is needed for the connection. The adapter will use this technical user for the connection. I would recommend creating in addition to the user also a view and restricting access for the user to the view with an additional role. That is exactly what I meant before to follow certain microservice rules. Access should be clearly abstracted by views, roles, and technical users. DO NOT reuse this technical user for additional services/apps requesting access. If you want to do the future further analysis in regards to locks, performance, and security it is A LOT easier to inspect your database and the connections based on a certain user.
- You need a user with CREATE REMOTE SOURCE (eg DBADMIN) privilege then you can either set up the remote source via the cockpit or using SQL.
The following diagram shows the complete relations and terms to each other:

SDA, Certificates, and Remote Sources
Another wonderful explanation and guidance through the whole process can be watched here:
With that, you should now have a working connection to another HANA database. But how can we now access the data? This can be done with virtual tables.
Virtual Tables explained
Virtual tables are awesome. 🙂 Because you can use them as-is in your SQL query and a lot of work is been carried over by the HANA database and the SDA adapter.
But how?
The diagram below shows the relations of certain technologies to each other:

Virtual Tables and Remote Sources
- First of all virtual tables need to be created. This can only be done with a user having the rights to do so: CREATE VIRTUAL TABLE. And here we are once again with another video from the SAP HANA Academy showing the process of setting up a virtual table. If you are interested in achieving this with SQL, then you should visit the help page.
- Important to know is that virtual tables are pointers to tables/schemas that are "reachable" with the technical user configured in the remote source earlier?
- Reachable means that during the setup of the virtual table the technical user will be checked for all "SELECT *" privileges it has. Whatever tables/views he is able to read will be possible to configure as a virtual table.
- In addition to this, it is of course needed that the user trying to create the virtual table also needs to right to do so in the specified package. Most often you will try to create either the virtual table in a dedicated schema for better central management OR you will create the virtual table in the schema of the application you want to extend with the source data. So you either grant as a schema owner of the application the DBAdmin access to your own schema (eg CREATE ANY) or you grant as a DBAdmin then later on access to the virtual table for your application database user.
Working with virtual tables
The cool thing about virtual tables is that you can just use them like normal tables. As described above they can just exist in your schema like any other table, but as soon as SQL is targeting it, the HANA will delegate the request to the SDA adapter and the connection magic will happen in the background without noticing it for consumers.
SELECT * FROM SCHEMA.VIRTUAL_TABLE JOIN ANY_OTHER_TABLE ON Be careful with joining between multiple virtual tables. This might lead to problems (see the search results here) and you can alter the behavior with additional configuration properties.
AND Be careful when the technical user within the remote source has the necessary rights to INSERT and UPDATE you can of course alter the table the virtual table is pointing to!

Virtual Table pointing to a remote table
Virtual Tables – Problems that might happen
Yay. Your app is now able to consume other tables via remote source and now you can even try
SELECT * FROM PERSON WHERE <GIVEMEALL>Perfect. The remote databases will return 100000 entries whenever you need them across the whole network and can be joined within the memory of your own database. Even though this is awesome for you this might not be that great for the team operation and maintaining the source database you received access to. And you always have to take into consideration that access over a virtual table goes through the additional database and network layers that will also affect performance and latency in your own database.
Think of the fact that even more applications will have this access. The source database can now be hammered with 100k requests and it is hard to scale for further consumers in the future. The diagram below just tries to show this problem.

Problems with direct access
For the sake of scaling it would be better to keep the source database as a data source and delegate access to the specific entries to your own database instead of driving the long road. Complex queries and joins can then be executed on your own database instead of torturing the source database.
Let's talk about the decentralization of data.
Decentralized tables - ETL
Decentralization is helping a lot in terms of scaling. I am NOT saying to decentralize everything, but when you know that a lot of consumers will need the same data and a LOT of this data decentralization will help to keep your source database as the source and not act like a bottleneck. Think of the fact that the source database will go down. All the consumers will be affected by this and many applications will stop working here. By decentralizing data the application can still work as-is (or at least just have an older dataset).
For decentralizing a lot of times we will use additional software to do the job for us. In the software industry we often refer to the abbreviation ETL: Extract, Transform, Load.

Usage of ETL in hybrid landscapes
ETL most often makes sense when you do not only want to extract the data, but also transform it from one format to another and then push it to somewhere else. Guess what? SAP HANA is offering SDI for a lot of the third parties and also SAP software to do this. But once again we would have to install a DP agent. In most of our applications, a transformation is not needed. And as we are talking about getting data out of one database to another we can most often also just keep the data structure of the source table. And here we are again being happy that SDA is already offering exactly what we want: A simple table replication from one database to another.
SDA - Table Replication
Table replication is just awesome. Simple said 🙂 In the beginning, I said I am by far not a database expert and so the following explanation and diagram might not be 100% academically and in terms of the underlying implementation right, but it will give a good understanding of the things going on within the HANA database when using SDA table replication.

Log-based table replication
First of all the whole concept is relying on lag-based replication. To make it short and to give you an abstraction of the whole process let me give you the whole flow:
- As an administrator, you have to create a subscription for a given virtual table
- The subscription acts as "a kind of" pub/sub-channel to the source database.
- This channel will indicate changes in the source table using the logs of the source database and checking for altering events
- When a change has been put in the pub/sub the subscription in your application database checks the last log entry of the latest changes and just replays whatever is missing from the source database
The cool thing is that once again application developers do not need to care about this. In the end, they always have the most recent data (almost real-time when using real-time replication) available in their database AND they can use whatever native SQL they are used to because, in the end, they are dealing with data in their OWN database.
Subscription - Real-Time-Replication
Enabling a subscription and using replication instead of direct access is straightforward. In the end, you need a virtual table, a subscription, and a replication table.

Virtual tables, Subscription and Replication Table
seungjoonlee has written a lovely blog post about this subject with a lot of details. I will just pick some of the commands out of this blog post, but I highly recommend reading it in addition to the commands described here.
- First of all, you have to create a virtual table with your remote source
CREATE VIRTUAL TABLE MARKETING.V_CUSTOMER AT "REMOTE_REP"."<NULL>"."SALES"."CUSTOMER";
- The next step is then to create a table with the same definition acting as the container for the replication
CREATE COLUMN TABLE MARKETING.R_CUSTOMER LIKE MARKETING.V_CUSTOMER;
- Now we have to create a subscription that is tracking the changes and keeping our replication table up to date
CREATE REMOTE SUBSCRIPTION SUB ON MARKETING.V_CUSTOMER TARGET TABLE MARKETING.R_CUSTOMER;
- And in our last step, we need to start the distribution of the source data to our replication table
ALTER REMOTE SUBSCRIPTION SUB DISTRIBUTE;
That's it. Keep in mind that the initial load could take some time.
Even though the blog post linked already offers you enough information, you might also be interested in an SAP Developer Mission by chriskollhed showing you all the essentials: https://developers.sap.com/tutorials/hana-cloud-mission-extend-09.html
Virtual Table – Toggle Access/Replication Mode
The cool thing about virtual tables is the possibility to change the behavior without affecting your application's behavior because, in the end, the virtual table will either point via direct access to the remote source's database or just point to your local copies.
Important to know that you have essentially to deal with two subjects when creating your virtual tables (shown in the diagram below):

Data Federation and Replication
- Data FederationThis is the very default mode when creating a virtual table. It just points to another database's table and accessing the virtual table will directly delegate access to the source database.
- Data ReplicationReplication can be enabled using a replication table with the same structure as the source table and a subscription. There is also the option to disable real-time replication and switch to a manual snapshot. This might be handy when you know that a source table does only change on a daily/weekly/yearly base (eg tax values).

Multiple Toggles for Virtual Tables
Careful: Toggling a virtual table to real-time replication is something different than having a subscription because there is no explicit (but only indirect) subscription available as an entity. At least this is how I understood it. 😉
takao.haruki has written a wonderful blog post about the different behaviors of virtual tables in this blog post : https://blogs.sap.com/2020/05/18/checking-the-behavior-of-sap-hana-cloud-virtual-table-replica-featu...
Summary and conclusion
- For remote access, we have to decide between data federation and data replication
- Data federation can by default be achieved creating a virtual table via a remote source
- Data replication can either be achieved using an explicit subscription or by toggling a virtual table
- A subscription is always real-time and sits as its own entity in the database (can be seen in the database explorer)
- A subscription always works on a replication table with the same structure as the virtual table
- A subscription uses a sub/pub mechanism to know when to query the source DB logs for the appropriate delta and updates its bound replication data properly
- A toggle controls the access to a virtual table
- Direct access to the configured remote table is given by default (Data Federation)
- Data replication can be used by altering the virtual table
- Real-time replication by default
- Snapshot replication when needed (needs to be manually updated or SDI replication tasks)
Additional thoughts
I love this feature of SAP HANA Cloud! Simple as that. The most important thing is that the complexity of data retrieval and delta updates is abstracted completely by a virtual table. This means that a lot of frameworks can be used out of the box.
So it is possible to use CAP to just expose your virtual tables as OData services or any other framework like Spring Data
Application developers do NOT have to think about the data and can concentrate on business logic and use cases. In my humble opinion, we forget often to not mix concerns within our development and keep applications clean for what they are: Showing and storing data. Code for transformation and retrieval of data should be put away from business logic and even from the microservice itself. Pushing this concern into the database layer, a separate job or ETL software is the right way to do it.
I want once again to point out that without the great SAP HANA Academy I could have never written such a blog post and would also once again urge you to visit their page!
Please help me with this blog post and put false assumptions from my side into the comments. I will try to update this blog post as soon as possible.
Other than that you should:
- follow the SAP HANA tag or check the SAP HANA topic page
- Post and answer questions about SAP HANA,
- And read other blog posts on SAP HANA.
Feel free to check out my jeffrey.groneberg here. Do not hesitate to drop me a direct message, if you want to have a small chat or have questions about this or any other blog post.
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
296 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
342 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 5 in Technology Blogs by SAP
- Explore Business Continuity Options for SAP workload using AWS Elastic DisasterRecoveryService (DRS) in Technology Blogs by Members
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |