
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- General principles for SAP HANA Cloud native appli...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
erhard_weidenau
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
05-10-2022
8:37 AM
SAP HANA Cloud is a true cloud product and an integral part of SAP BTP. In an on-premise set-up using SAP HANA XS classic, application development could be discussed and handled to a large extend within XS classic. For SAP HANA Cloud, XS advanced is the new and only way of building applications. This programming and server model relies more on shared services and Cloud Foundry. Consequently, some of your previous design principles need to be adapted. For instance, the database as well as services and application developed upon are fully integrated into Cloud Foundry and adhere to its security policies.
But let us start easy. When it comes to native database development, you basically deal with the following:
In this blog post, we focus on the application logic and persona and not too much on data, application security, or processes. We will discuss and motivate the following guiding principles, which are not complete, but should be considered during the design process.
Before going into detail of these principles, I will comment on data. In general, we recommend to separate data from application logic as a rule of thumb. Reasons for this separation are as follows. Whereas the application logic could follow a micro service design. This might not always be a good idea for the data, i.e., persistence. For instance, you build a data lake, which serves as a single source of data for various applications. If the persistency of the applications would be strictly separated this would yield to replication of data used by several applications. This replication and the resulting redundancy often contradict the idea of your data lake. In addition, the application logic is subject to change and could be disruptive, e.g., an algorithm is removed or changed in an incompatible manner. Whereas for data, the underlying table definitions are less likely to be changed. And if they are changed, it is generally in a compatible way. Consequently, separate deployment is often helpful.
You want to do application development on SAP HANA Cloud. You might wonder why you need to deal with Cloud Foundry or even BTP sub-accounts. This section will illustrate you how these two influence the design and security of your application.
Motivation
Remember application development in the cloud is based on services. The services that contain data and application logic for SAP HANA Cloud database development are the HDI containers. One of the Cloud Foundry paradigms is that services within the same Cloud Foundry space can fully access each other. Meaning all service keys are visible between the services of the Cloud Foundry space as well as to any space developer. The service keys for HDI containers consists of a runtime and a design user of the HDI container, which gives you basically full access. This is by intention to enable easy binding and re-use. If you now want to strictly limit the access to an HDI container, you need separate the accessing developer or service and the consumed HDI container into different Cloud Foundry spaces. Showing that database and application security includes the design of HDI containers and their location in Cloud Foundry spaces, and BTP accounts, as we will see soon.
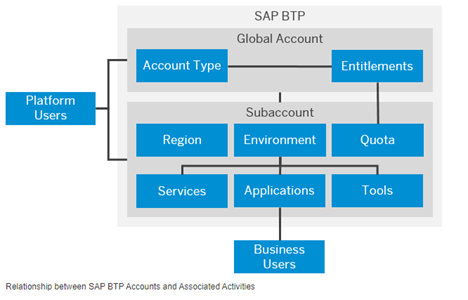
We strongly recommend starting with your BTP account design early. You might iterate over the design. Having database specific questions in mind, the planning or design of the BTP global account is touched briefly to make you familiar with some concepts.
The general structure of your BTP global account can have aspects that focus on
A good starting point are the general best-practices for setting up a BTP account, see
https://help.sap.com/products/BTP/65de2977205c403bbc107264b8eccf4b/0859096d340b45dfb39417a01870ad95....
First you should determine the amount of people that will work with your solution. Do not limit your thoughts to now, but it is good practice to prepare for the next years. There might be other projects using the same data foundation, more people using your application, etc.
One team: In a set-up, where everyone does everything, you should keep things as simple as possible without compromising on compliance or security aspects. For instance, if everyone can act as a super-user, then auditing and traceability are key for being compliant.
Some teams: In such a set-up, you find specialization and responsibilities with different teams. But the list of teams is flat, i.e., there is no need for a hierarchy of teams.
The team members are supposed to do certain tasks. Even more important you have the aspect that certain tasks shall only be done by a specific team. Thereby, you enter areas of
Since the list of teams is flat, your global account model has no explicit need for sub-structures or grouping. Therefore, you have more freedom in your modeling.
Many teams: With a higher number of teams, you have hierarchies or groups of teams. In our global account modeling, this translates into:
Enough of the pure BTP account design. Let us have a look at the personas who work and develop on SAP HANA Cloud instance. Especially, development operations and administrators on the one hand and software developers on other the hand. Both personas have BTP accounts and are members of Cloud Foundry spaces. One thing most customer need to achieve is segregation of duty. Let us have a look at the following objective.
It is important to know that the creation, change, and deletion of a SAP HANA Cloud instance is in general NOT different to the creation, change, and deletion of any other service instance in a Cloud Foundry space. The Cloud Foundry user role that enables for this is Space Developer, see https://help.sap.com/products/BTP/65de2977205c403bbc107264b8eccf4b/09076385086b4da3bd1808d5ef572862....
We have the following:
Problems
Although software developers cannot apply changes to the database, if they do not have access to a database administrator user, they can still do the following:
Recommendation
You should have different Cloud Foundry spaces for database administration and project or application development.
It might even be useful to have these Cloud Foundry spaces in separate BTP sub-accounts. Technically, you can exclude the usage of paid services in a Cloud Foundry space using an appropriate Quota Plan. But keep in mind, development might grow over time and deal with integration of various services, too. Overtime, the quota configuration might change and hence open the creation and/or deletion of SAP HANA Cloud instances. In case you need a save set-up, you can create a sub-account that contains your SAP HANA Cloud instances only, whereas application development, testing, and running productive application is done in other sub-accounts.
Note: Since the SAP HANA Cloud database is no longer in the same Cloud Foundry space, it is by default not visible or accessible for space developers in another Cloud Foundry space. In order to make the SAP HANA Cloud instance available for development, e.g. HDI container deployment, you need to share the instance the Cloud Foundry space used for development, see https://help.sap.com/viewer/683a53aec4fc408783bbb2dd8e47afeb/LATEST/en-US/1683421d02474567a54a81615e....
Dividing your application or project into independently deployable parts is often key when it comes applying minimal changes and corrections into your productive application. The smallest granularity of Cloud Foundry deployment is a service, e.g. an HDI container. We will now discuss the impact of this to your application design.
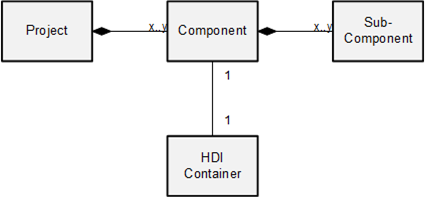
Often, we find many applications and services running on the same SAP HANA Cloud database. In such a situation, it is natural to find tasks and functions needed by different applications. Or you have applications which profit from having a sub-structure grouping similar tasks and functions into a software component or shortly a component. In bigger projects, components are grouped by purpose e.g. data foundation layer, composition layer, consumption layer. We call such a group a layer and request that they form a directed, a-cyclic graph.
Since data and application logic is contained in HDI containers, components are built of HDI containers. In the following we touch some aspects on HDI container design with respect to layers.
Sure, layers and components are logical concept that are not reflected in objects in CF or HANA, directly. It is described as Software Architecture. But we have the following recommendations on how these logical concepts can be used grouping HDI containers in Cloud Foundry spaces.
Recommendations
In these cases, you keep the layers in different Cloud Foundry spaces and expose the API using user-defined service with minimal privileges, see https://help.sap.com/viewer/c2b99f19e9264c4d9ae9221b22f6f589/LATEST/en-US/f7381ccf4bc644f286ac72cc54....
Reasons
Up to now, we had a pure design discussion. Next, we dive into the interplay between design time and runtime. Remember services in the cloud are intended to be instantiated several times for scalability and robustness reasons. Therefore, we have the situation that one design time object can correspond to several runtime instances. Nothing special. Nevertheless, the next section deals with the correspondence between design time and runtime objects.
Remember, a database module of an MTA is a design time object that contains the definition of database artefacts, see the developer guide. An HDI container is a runtime object containing instances of database artefacts. During development, you create database artefacts in a database module. These objects or the module itself are deployed into an HDI container to create runtime representations of the design time objects. During development, it is technically possible that various design time environments bind to the same HDI container, because the deploy application is in the end just a Cloud Foundry application binding to a Cloud Foundry service. Since there are no limits for applications to bind to a service, several design time environments, e.g., BAS development spaces of different developers, could bind to the same HDI container. Beside the human aspect of different developer working on the same HDI container, it is technically possible that you bind several database modules to the same HDI container. Meaning different database modules deploy into the very same HDI container. This is strongly discouraged.
You should have only one database module deploying into an HDI container.
Risks
Software projects are naturally evolve over time, e.g., the code base grows, or a component might need sub-component…. Sometimes you might face the situation that sub-components that are deployed into one HDI container are handled by different people. In this section, we illustrate how two developers working in their own BAS development space can contribute to the source code that is deployed into one productive HDI container.
Let’s take the following example.
The following questions will be discussed:
By assumption, we have only one HDI container and we follow the guiding principle only one database module per HDI container. We recommend using sub-folders of the database module path db/src in such a situation. This yield to an easy rule to follow for the developers
Note: In order to reflect the differences of the two sub-components, the sub-folders could have different namespaces for their database artefacts, too. Besides the safety belt for potential name clashes, the sub-component of an artefact could be easily identified and the correct developer directly approached in case of questions, new features, or errors.
The guiding principle influences the runtime and the number of HDI containers, mostly. Meaning, we have at least three HDI containers in this situation.
This is shown in the next diagram. Both developers have pulled the component resources from a common code repository, e.g., GitRepository. Their software project, which is described by the mta.yaml file, has only one database module. This module contains the sub-modules as sub-folders. During development, Anton and Rachel work in different containers and a deployment of one developer does not impact or influence the work of the other developer. The published/released code is separate container that does not change either.
Discouraged Approaches: Anton and Rachel use the same development HDI container
In case Anton and Rachel would use the same HDI container, they would have two database modules deploy into only one HDI container.
In the picture, you see that if the source code differs between the two developers, their deployment into the same container influences the artefacts of the other component, which might already be changed. In case the complete module or parts of sub-component 2 are deployed by Anton, the already deployed changes from Rachel get reverted, because Anton still has the old source code of Rachel’s sub-component. The same holds true if Rachel deploys the complete database module or parts of sub-component 1.
Let us take a simplified CRM example. In the CRM system, you run two applications
We assume that there are two teams and that you follow the principle of least privilege or need to know. Meaning for example that the artefacts of Claims & Returns are only accessible to the team for Claims & Returns and not to the team for Customer Segmentation.
Moreover, we assume that
Design Possibilities and Implications
The choice for a 1 or 2 HDI containers design has implications on reused or common objects, too. A typical example is given by master data.
In a 1 HDI container design – Monolith
Consequently, we have the following:
In a 2 HDI container design:
Consequently, we have the following:
We see that the 2 HDI container is the preferred design according to our requirements to isolation and the need-to-know principle.
Nevertheless, working with several HDI containers comes with the necessity of cross-container access. Cyclic HDI container usage should be omitted because deployment dependencies could block each other like a dead lock. Let’s continue our example. Both applications naturally will need master data. In the beginning the set might theoretically be disjoint. But over time, there will be a set of common meta data. This data must not be cross referenced between the individual developer containers; hence we must introduce a third HDI container for the re-use artefacts. Meaning practically there is NO 2 HDI container design, only a 3 HDI container design 😉.
Native application development in SAP HANA Cloud has many aspects. Beside data structures, algorithms, views, and database artefacts, an applications has to fulfill requirements like security and compliance, e.g., segregation of duties. In this blog post, I illustrated how these requirements can not be solved in the SAP HANA Cloud database, alone. But you need to make yourself familiar with the concepts of Business Technology Platform and Cloud Foundry, right from the start.
If you have feedback & questions please let me know in the comments what would be helpful to you.
Thanks and Regards,
Erhard
For a complete overview on the development please refer to SAP HANA Cloud, SAP HANA Database Developer Guide for Cloud Foundry Multitarget Applications. For our discussion, we just recall the major terms:
The design-time artifacts of a database module are deployed into an HDI container, which contains the runtime objects, see https://help.sap.com/viewer/c2b99f19e9264c4d9ae9221b22f6f589/LATEST/en-US/1b567b05e53c4cb9b130026cb2...
But let us start easy. When it comes to native database development, you basically deal with the following:
- Data, e.g., tables and their content
- Application logic, e.g., procedures, views, calculation views
- Users and authorizations, e.g., analytic privileges, roles, users.
- Persona, e.g., developers, administrators, and operators
- Processes for development, testing, and production
In this blog post, we focus on the application logic and persona and not too much on data, application security, or processes. We will discuss and motivate the following guiding principles, which are not complete, but should be considered during the design process.
- Use Cloud Foundry spaces and/or BTP sub-accounts to separate database administration tasks from development tasks
- You should have only one database module per HDI container
- Use separate database modules for components or bigger sub-components
- Use Cloud Foundry spaces for layered software design and to increase the protection of sensitive data
Before going into detail of these principles, I will comment on data. In general, we recommend to separate data from application logic as a rule of thumb. Reasons for this separation are as follows. Whereas the application logic could follow a micro service design. This might not always be a good idea for the data, i.e., persistence. For instance, you build a data lake, which serves as a single source of data for various applications. If the persistency of the applications would be strictly separated this would yield to replication of data used by several applications. This replication and the resulting redundancy often contradict the idea of your data lake. In addition, the application logic is subject to change and could be disruptive, e.g., an algorithm is removed or changed in an incompatible manner. Whereas for data, the underlying table definitions are less likely to be changed. And if they are changed, it is generally in a compatible way. Consequently, separate deployment is often helpful.
Cloud Foundry and BTP influence segregation of duty in the database
You want to do application development on SAP HANA Cloud. You might wonder why you need to deal with Cloud Foundry or even BTP sub-accounts. This section will illustrate you how these two influence the design and security of your application.
Motivation
Remember application development in the cloud is based on services. The services that contain data and application logic for SAP HANA Cloud database development are the HDI containers. One of the Cloud Foundry paradigms is that services within the same Cloud Foundry space can fully access each other. Meaning all service keys are visible between the services of the Cloud Foundry space as well as to any space developer. The service keys for HDI containers consists of a runtime and a design user of the HDI container, which gives you basically full access. This is by intention to enable easy binding and re-use. If you now want to strictly limit the access to an HDI container, you need separate the accessing developer or service and the consumed HDI container into different Cloud Foundry spaces. Showing that database and application security includes the design of HDI containers and their location in Cloud Foundry spaces, and BTP accounts, as we will see soon.
We strongly recommend starting with your BTP account design early. You might iterate over the design. Having database specific questions in mind, the planning or design of the BTP global account is touched briefly to make you familiar with some concepts.
The general structure of your BTP global account can have aspects that focus on
- Region: in which location do I need an account? Or the availability of certain services or hyper scalers?
- Cost: you want to easily identify and assign costs to business units, organizations, cost centers in your company
- Compliance and security: who has access to which data?
- Technical features
- etc.
A good starting point are the general best-practices for setting up a BTP account, see
https://help.sap.com/products/BTP/65de2977205c403bbc107264b8eccf4b/0859096d340b45dfb39417a01870ad95....
How big is your organization?
First you should determine the amount of people that will work with your solution. Do not limit your thoughts to now, but it is good practice to prepare for the next years. There might be other projects using the same data foundation, more people using your application, etc.
One team: In a set-up, where everyone does everything, you should keep things as simple as possible without compromising on compliance or security aspects. For instance, if everyone can act as a super-user, then auditing and traceability are key for being compliant.
Some teams: In such a set-up, you find specialization and responsibilities with different teams. But the list of teams is flat, i.e., there is no need for a hierarchy of teams.
- Database & infrastructure team
- Developer team(s)
- End-users
- Fire fighters
- Supporters
- etc.
The team members are supposed to do certain tasks. Even more important you have the aspect that certain tasks shall only be done by a specific team. Thereby, you enter areas of
- user and members
- entitlements, service plan assignments
- quotas and quota plans
- Cloud Foundry space and BTP sub-accounts
- role collections, role templates, and scopes
- etc.
Since the list of teams is flat, your global account model has no explicit need for sub-structures or grouping. Therefore, you have more freedom in your modeling.
Many teams: With a higher number of teams, you have hierarchies or groups of teams. In our global account modeling, this translates into:
- working with naming conventions
- working with different sub-accounts for branches of the hierarchy
- using Cloud Foundry spaces for branches where self-organization is possible
- etc.
Enough of the pure BTP account design. Let us have a look at the personas who work and develop on SAP HANA Cloud instance. Especially, development operations and administrators on the one hand and software developers on other the hand. Both personas have BTP accounts and are members of Cloud Foundry spaces. One thing most customer need to achieve is segregation of duty. Let us have a look at the following objective.
Keep database administration separate from development tasks
It is important to know that the creation, change, and deletion of a SAP HANA Cloud instance is in general NOT different to the creation, change, and deletion of any other service instance in a Cloud Foundry space. The Cloud Foundry user role that enables for this is Space Developer, see https://help.sap.com/products/BTP/65de2977205c403bbc107264b8eccf4b/09076385086b4da3bd1808d5ef572862....
We have the following:
- The creation, change, and deletion of SAP HANA Cloud instances is controlled by the entitlement “SAP HANA Cloud” on BTP sub-account. In all Cloud Foundry spaces, whose quota plan allow the usage of paid services, all organization members being space developers can create, change, delete SAP HANA Cloud instances.
- The creation, change, and deletion of HDI containers is controlled by the entitlements “SAP HANA schemas & HDI Containers” and “Cloud Foundry Runtime” on BTP sub-account. In all Cloud Foundry spaces, whose quota plans have a non-zero memory quota, all organization members being space developers can create, change, delete HDI containers.
- For administration of the database on database level, you need a dedicated SAP HANA Cloud database user.
Problems
Although software developers cannot apply changes to the database, if they do not have access to a database administrator user, they can still do the following:
- They could create their own SAP HANA Cloud instances. This could result in higher costs due to increased SAP HANA Cloud quota usage.
- They could delete existing SAP HANA Cloud instances bringing the risk of loss of intellectual property and work due to deleted databases
Recommendation
You should have different Cloud Foundry spaces for database administration and project or application development.
It might even be useful to have these Cloud Foundry spaces in separate BTP sub-accounts. Technically, you can exclude the usage of paid services in a Cloud Foundry space using an appropriate Quota Plan. But keep in mind, development might grow over time and deal with integration of various services, too. Overtime, the quota configuration might change and hence open the creation and/or deletion of SAP HANA Cloud instances. In case you need a save set-up, you can create a sub-account that contains your SAP HANA Cloud instances only, whereas application development, testing, and running productive application is done in other sub-accounts.
- One sub-account for database administrators
- One or more sub-account for developers
Note: Since the SAP HANA Cloud database is no longer in the same Cloud Foundry space, it is by default not visible or accessible for space developers in another Cloud Foundry space. In order to make the SAP HANA Cloud instance available for development, e.g. HDI container deployment, you need to share the instance the Cloud Foundry space used for development, see https://help.sap.com/viewer/683a53aec4fc408783bbb2dd8e47afeb/LATEST/en-US/1683421d02474567a54a81615e....
Layered software design and Cloud Foundry spaces
Dividing your application or project into independently deployable parts is often key when it comes applying minimal changes and corrections into your productive application. The smallest granularity of Cloud Foundry deployment is a service, e.g. an HDI container. We will now discuss the impact of this to your application design.

Often, we find many applications and services running on the same SAP HANA Cloud database. In such a situation, it is natural to find tasks and functions needed by different applications. Or you have applications which profit from having a sub-structure grouping similar tasks and functions into a software component or shortly a component. In bigger projects, components are grouped by purpose e.g. data foundation layer, composition layer, consumption layer. We call such a group a layer and request that they form a directed, a-cyclic graph.
Since data and application logic is contained in HDI containers, components are built of HDI containers. In the following we touch some aspects on HDI container design with respect to layers.

Sure, layers and components are logical concept that are not reflected in objects in CF or HANA, directly. It is described as Software Architecture. But we have the following recommendations on how these logical concepts can be used grouping HDI containers in Cloud Foundry spaces.
Recommendations
- For a layer where all components are completely visible and accessible to each other, it is recommended that this layer is fully contained in single Cloud Foundry space. This ensures easy cross-container access between the various components.

- If you require that not all components should be completely visible to each other, e.g.,
- that upper layers and their developers shall only be able to consume and read data use certain functions from the lower layer using an agreed API.
- Or that the programmatic access to sensitive data, e.g., Human Resources data like employee information, must be controlled carefully.
In these cases, you keep the layers in different Cloud Foundry spaces and expose the API using user-defined service with minimal privileges, see https://help.sap.com/viewer/c2b99f19e9264c4d9ae9221b22f6f589/LATEST/en-US/f7381ccf4bc644f286ac72cc54....

Reasons
- All services of a Cloud Foundry space are mutually fully visible. Runtime and design time users of other HDI containers are accessible.
- An HDI container in another Cloud Foundry space is accessible using e.g., a user provided service, which basically consists of user credentials. Access to the HDI container is controlled by the privileges that the HANA user of the user-provided service can grant to others. These credentials generally differ from the credentials of the service keys of the HDI container.
Up to now, we had a pure design discussion. Next, we dive into the interplay between design time and runtime. Remember services in the cloud are intended to be instantiated several times for scalability and robustness reasons. Therefore, we have the situation that one design time object can correspond to several runtime instances. Nothing special. Nevertheless, the next section deals with the correspondence between design time and runtime objects.
Remember, a database module of an MTA is a design time object that contains the definition of database artefacts, see the developer guide. An HDI container is a runtime object containing instances of database artefacts. During development, you create database artefacts in a database module. These objects or the module itself are deployed into an HDI container to create runtime representations of the design time objects. During development, it is technically possible that various design time environments bind to the same HDI container, because the deploy application is in the end just a Cloud Foundry application binding to a Cloud Foundry service. Since there are no limits for applications to bind to a service, several design time environments, e.g., BAS development spaces of different developers, could bind to the same HDI container. Beside the human aspect of different developer working on the same HDI container, it is technically possible that you bind several database modules to the same HDI container. Meaning different database modules deploy into the very same HDI container. This is strongly discouraged.
You should have only one database module deploying into an HDI container.
Risks
- There can be name clashes of artefacts defined in different modules.
- The deployment of a database module into an HDI container manages the delta, too. Meaning what is missing will be created, what is changed will be altered, objects with a counterpart in source code will be deleted if deployment is called with the un-deploy option. This is the default setting in Business Application Studio.
Set-up sub-components within an HDI container
Software projects are naturally evolve over time, e.g., the code base grows, or a component might need sub-component…. Sometimes you might face the situation that sub-components that are deployed into one HDI container are handled by different people. In this section, we illustrate how two developers working in their own BAS development space can contribute to the source code that is deployed into one productive HDI container.
Let’s take the following example.
- We have two developers, Anton and Rachel, who both work on different sub-components of the same component, i.e., component 1 and component 2
- The component is realized with only 1 HDI container, i.e., we assume there is a design decision not to split the HDI container into several HDI containers
The following questions will be discussed:
- What technical artefact should represent such a sub-component?
- A subfolder in database module?
- or a database module?
- How will Anton and Rachel work without ignoring the principles we discussed?
By assumption, we have only one HDI container and we follow the guiding principle only one database module per HDI container. We recommend using sub-folders of the database module path db/src in such a situation. This yield to an easy rule to follow for the developers
- Anton is responsible for sub-component 1 and works in folder db/src/subcomponent1
- Rachel is responsible for sub-component 2 and works in folder db/src/subcomponent2
Note: In order to reflect the differences of the two sub-components, the sub-folders could have different namespaces for their database artefacts, too. Besides the safety belt for potential name clashes, the sub-component of an artefact could be easily identified and the correct developer directly approached in case of questions, new features, or errors.
The guiding principle influences the runtime and the number of HDI containers, mostly. Meaning, we have at least three HDI containers in this situation.
- Anton has his HDI container for testing and developing
- Rachel has her HDI container for testing and developing
- There is one HDI container that contains the published/released code of Anton and Rachel. We sometimes call it a golden code line, or you can think of the common quality or productive HDI container
This is shown in the next diagram. Both developers have pulled the component resources from a common code repository, e.g., GitRepository. Their software project, which is described by the mta.yaml file, has only one database module. This module contains the sub-modules as sub-folders. During development, Anton and Rachel work in different containers and a deployment of one developer does not impact or influence the work of the other developer. The published/released code is separate container that does not change either.

2 developers working on different sub-components in the same database module
Discouraged Approaches: Anton and Rachel use the same development HDI container
In case Anton and Rachel would use the same HDI container, they would have two database modules deploy into only one HDI container.
In the picture, you see that if the source code differs between the two developers, their deployment into the same container influences the artefacts of the other component, which might already be changed. In case the complete module or parts of sub-component 2 are deployed by Anton, the already deployed changes from Rachel get reverted, because Anton still has the old source code of Rachel’s sub-component. The same holds true if Rachel deploys the complete database module or parts of sub-component 1.

Issue if 2 developers deploy into the very same HDI container
Application Example
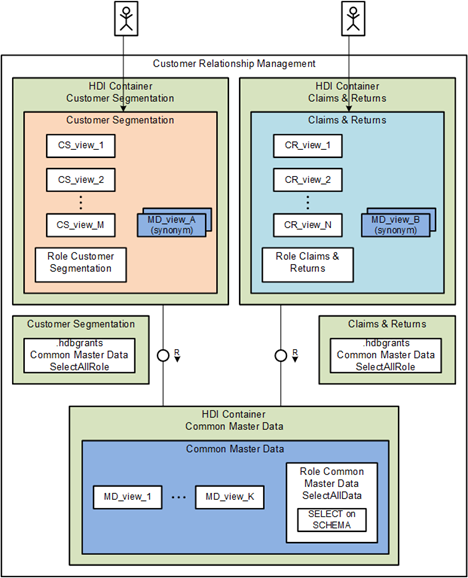
Let us take a simplified CRM example. In the CRM system, you run two applications
- Customer segmentation for market analysis
- Claims & returns
We assume that there are two teams and that you follow the principle of least privilege or need to know. Meaning for example that the artefacts of Claims & Returns are only accessible to the team for Claims & Returns and not to the team for Customer Segmentation.
Moreover, we assume that
- the set of artefacts for Claims & Returns is stable, e.g., changes or new objects occur rarely.
- the set of artefacts for Customer Segmentation changes frequently

Simple example of two CRM applications
Design Possibilities and Implications
- Simple CRM example in one HDI container
- Simple CRM example in two HDI containers
The choice for a 1 or 2 HDI containers design has implications on reused or common objects, too. A typical example is given by master data.
In a 1 HDI container design – Monolith
- The applications "Customer Segmentation" and "Claims & Returns" are sub-components in one HDI container. The database artefacts, e.g., calculation views, for both applications reside in the same schema, i.e., HDI container schema. Therefore, you must have different namespaces for the two applications.
- Each application needs a separate role that provides access to the artefacts of its application.
Consequently, we have the following:
- Artefacts from another namespace can easily accessed
- Changes in one component require the redeployment of everything

Monolithic design of two CRM applications
In a 2 HDI container design:
- The applications "Customer Segmentation" and "Claims & Returns" are separate HDI containers.
- Since the artefacts exist in different schemas, there is no technical need for a separate namespace, because name clashes can only happen with one schema.
- Nevertheless, if you work with public synonyms or sometimes omit the schema name in discussions, different namespaces for the two applications could be beneficial.
- Again, each application needs a separate role that provides access to the artefacts of its application.
Consequently, we have the following:
- Artefacts from the other container can only be accessed by cross container access which requires some additional efforts
- Changes of one component do not imply a re-deployment of the other component. This results in shorter deploy times and less overall service downtime due to software changes or fixes.
We see that the 2 HDI container is the preferred design according to our requirements to isolation and the need-to-know principle.
Nevertheless, working with several HDI containers comes with the necessity of cross-container access. Cyclic HDI container usage should be omitted because deployment dependencies could block each other like a dead lock. Let’s continue our example. Both applications naturally will need master data. In the beginning the set might theoretically be disjoint. But over time, there will be a set of common meta data. This data must not be cross referenced between the individual developer containers; hence we must introduce a third HDI container for the re-use artefacts. Meaning practically there is NO 2 HDI container design, only a 3 HDI container design 😉.
Conclusion
Native application development in SAP HANA Cloud has many aspects. Beside data structures, algorithms, views, and database artefacts, an applications has to fulfill requirements like security and compliance, e.g., segregation of duties. In this blog post, I illustrated how these requirements can not be solved in the SAP HANA Cloud database, alone. But you need to make yourself familiar with the concepts of Business Technology Platform and Cloud Foundry, right from the start.
If you have feedback & questions please let me know in the comments what would be helpful to you.
Thanks and Regards,
Erhard
Some References
For a complete overview on the development please refer to SAP HANA Cloud, SAP HANA Database Developer Guide for Cloud Foundry Multitarget Applications. For our discussion, we just recall the major terms:
- Design-time database resources reside in the database module of your multi-target application, see https://help.sap.com/viewer/c2b99f19e9264c4d9ae9221b22f6f589/LATEST/en-US/72b60de8cd1945818259c7d978...
The design-time artifacts of a database module are deployed into an HDI container, which contains the runtime objects, see https://help.sap.com/viewer/c2b99f19e9264c4d9ae9221b22f6f589/LATEST/en-US/1b567b05e53c4cb9b130026cb2...
- SAP Managed Tags:
- SAP HANA Cloud
Labels:
13 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
273 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
324 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
402 -
Workload Fluctuations
1
Related Content
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- SAP GUI for Java 8.10 on the Horizon in Technology Blogs by SAP
- Unlocking Full-Stack Potential using SAP build code - Part 1 in Technology Blogs by Members
- Consuming CAPM Application's OData service into SAP Fiori Application in Business Application Studio in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 12 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 4 |