前言
在进行计划预测时,我们经常使用“时间序列预测”功能来寻找一些关键 KPI 的演变规律,从而生成可以用以预测未来数值的预测模型。时间序列预测可以帮助帮助用户理解,这些 KPI 的变化是否存在某种规律,以及他们在某个特定月份是否倾向于更低的值(周期性分析)。
在一些情况下,被预测的 KPI 只和时间相关,因此仅依靠该 KPI 的历史值即可实现准确的预测。但有时,我们要预测的值不仅取决于时间,还与其他外部因素相关。例如,某公司产品的销售额在一定程度上与该公司在营销和广告上的花费有关,或者某一城市租用的自行车数量与该城市的天气和温度相关。
因此,在 SAP 分析云近期的更新中,我们将“影响因素”功能引入到时间序列预测模型中,使得时间序列模型的生成过程中,不仅可以基于历史值,更可以将其他外部影响因素的影响纳入模型的学习范围,从而生成更准确的预测值。在这篇文章中,我将向您展示如何使用“影响因素”功能,以从您的数据中获得更多见解,并提高预测的准确性。
场景
假设您在上海的一家自行车租赁公司工作。公司提供了一个计划模型,其中包含一个BikeHires测量值,表示每天的使用人数,以及与天气相关的几个测量值。您想基于预测计划来预测未来31天租用的自行车数量。在这种情况下,假设当前日期为2015年7月31日,这将允许我们将预测值与2015年8月实际产生的值进行比较。
如果要重新创建此示例,可以下载
此数据集。请注意,列BikeHires, Temp.Min, Temp.Max, Temp.Mean, Humid.Min, Humid.Max, Humid.Mean 和 Rain将作为度量,其他列应视为维度。
基线预测模型
让我们创建一个“基线”预测模型,在不使用影响因素的情况下预测租用人数。我们将在 2015 年 7 月 31 日之后预测 31 个预测点,并从一整年的历史数据中学习,见下图。



如下图所示,我们配置一个观测项时段,时段大小为1年,截至2015年7月31日。

如下图所示,目前我们不添加任何的影响因素

对预测模型进行训练后,我们可以在预测建模报告中得到以下结论:
- 经过训练的预测模型的期望误差为93%。
- 当将预测值与实际值进行比较时,我们可以看到一些波动没有建模,一些预测值与实际值相差甚远。
- 共有7个异常值(预测值与实际值相差甚远的点)。

请注意,根据预测引擎的版本迭代,您得到的结果可能略有不同。
通过解释报告,我们可以看到预测模型在时间序列中发现了趋势和一些周期性模式。

这表明自行车租用量在一定程度上是由时间决定的。但我们认为,与天气相关的因素,如室外温度或降雨量,同样也会对自行车租赁产生影响。如今,我们可以利用“影响因素”功能,来验证是否有这种相关性。
利用影响因素改进预测模型
我们希望保留基线模型作为参考,并对改进的预测模型使用相同的设置,所以让我们使用“克隆”功能。

打开新创建的预测模型,向下滚动至设置的“影响因素”部分。让我们通过添加以下影响因素并训练预测模型来验证我们关于外部温度和降雨量对自行车租用产生影响的假设:
Humid. Max |
当日最大的空气湿度(%) |
Humid. Mean |
当日平均的空气湿度(%) |
Humid. Min |
当日最小的空气湿度(%) |
Rain |
当日降雨量 |
Temp. Max |
当日最高温度(℃) |
Temp. Mean |
当日平均温度(℃) |
Temp. Min |
当日最低温度(℃) |

一个时间序列预测模型最多可以添加20个影响因素。影响因素是计划模型(账户、度量等)的数值,这可能有助于预测目标。模型训练完成后,在预测建模报告中,我们得到以下几点结论:
- 经过训练的预测模型的期望误差已降至1%(无影响因素的模型为16.93%)
- 将预测值与实际值进行比较时,我们可以看到预测序列更接近实际值。
- 异常值较少(5个异常值,而基线模型中为7个)。

因此,使用了“影响因素”后,根据训练数据集训练出来的BikeHires的时序模型更加准确。。但为了了解模型的“真实”准确性,我们需要查看水平周期的准确性。通过放大预测与实际的可视化结果,我们可以看到,当使用影响因素时,预测序列更接近实际时间序列:

无影响因素的时间序列预测

包含影响因素的时间序列预测
我们可以在解读报告中看到影响因素的相对贡献。

时间成分(趋势、周期…)由计划日期(Day维度)表示,占预测的86.04%。然后是最高温度,占5.84%;然后是平均湿度,占2.10%;然后是降雨量,占1.96%……因此,正如预期的那样,降雨量、最高温度和平均湿度对租用的自行车数量有很大影响。我们可以通过一个故事来可视化BikeHire与影响因素,来更深入地了解影响因素与目标之间的关系。我们可以看到,总体而言,当室外温度升高时,租用自行车的人数趋于增加,而当湿度和降雨量增加时,租用自行车的人数趋于减少。

需要注意的一点是,我们在设置中选择的一些影响因素(Humid.Min,Humid.Max…)没有出现在列表中。预测模型只保留“有用”的影响因素。它评估每个影响因素将为模型带来多少额外性能,只保留那些带来足够额外准确性的性能。因此,重要的是要理解,如果一个影响因素没有显著提高预测精度,那么就不可能强迫预测模型使用该影响因素。
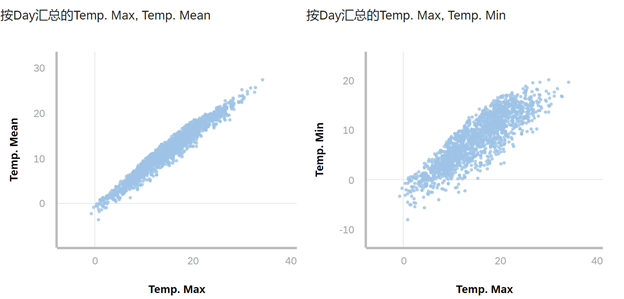
但为什么Temp.Min和Temp. Mean没有被模型使用呢?通过绘制Temp.Max与Temp. Mean和Temp.Min的散点图,我们发现Temp.Max与这两个影响因素高度相关,也就意味着这三个度量具有高度的相似性,相比于单独使用Temp.Max,额外使用Temp. Mean和Temp.Min两个因素并不会带来更多有用的信息。
关于影响因素的其他考虑
影响因素必须是可用于预测的
预测模型可以发现影响因素和待预测目标之间的数据中存在的模式(相关性),然后在未来应用这些模式来生成预测。为了在未来正确应用模式,需要为预测期提供影响因素的未来值。如果使用一些影响因素创建时间序列预测模型,但没有为预测期提供影响因素的值,则预测计划将不会生成预测并报告错误。
假如是Temp.Max和Rain已被选为影响因素,以下数据不能够获得2015年8月的预测,因为影响因素在该时期没有值。

下面的数据将允许生成2015年8月的预测,因为影响因素的值在该时期内可用。

您还需要区分受直接控制的影响因素和不受直接控制的影响因素。
使用诸如“广告预算”、“费用预算”或“销售预算”之类的指标是很简单的,因为您(或至少是您公司的某个人)决定了他们的价值,你可以为预测期提供准确的值。
另一方面,使用天然气或货币汇率等影响因素需要更加小心。这些因素可能会对您想要预测的KPI产生影响,但它们不在您的控制之下:您无法知道它们的未来值。如果你想利用这些影响因素,您应该根据影响因素的不同假设生成几组预测。例如,您可以为“可能”假设(使用影响因素的预期未来值)、乐观假设和悲观假设生成预测。
如何找出潜在的影响因素
我们倾向于将异常值(或者更一般地说,任何没有预测到的值)视为不可预测的事件。在分析预测模型的报告时,请花一些时间查看这些“预测得不太好”的点。您能找到实际情况不如预期的商业原因吗?您会发现更多结论。在这种情况下,您可能已经确定了一个可以添加到计划模型中的度量,用于提高预测的准确性。
在添加影响因素时要“吝啬”
在我的模型中加入所有可能的影响因素似乎是一个提高预测准确性的好主意。但事实并非如此。我们建议谨慎选择影响因素,不要同时使用太多。使用“太多”影响因素可能会产生负面建模影响:当使用太多影响因素时,预测模型可能很好地解释了过去,但可能无法在未来的数据上提供相同的性能,也就是“过拟合”。使用影响因素也会提高计划模型的成本。影响因素必须随着时间的推移进行维护:您需要收集数据,并将其纳入计划模型。只有在准确度或商业洞察力方面真正有所提高的情况下,这些工作才是值得投入的。我们没有任何经验法则来确定影响因素的正确数量,而且您也不需要得到一个完美的模型。在您的预测模型中保留那些对准确度有很大影响的影响因素,丢弃那些影响不大的因素。一个可行的做法是在预测模型中逐步引入影响因素,以检查对期望误差的影响。
结语
在这篇文章中,您学习了如何使用”影响因素”功能来提高时间序列预测模型的准确率,更好的辅助企业决策者做出正确的数据驱动决策。希望这篇推文对您有帮助。如果您喜欢这篇文章,欢迎留下评论并点赞,非常感谢。
更多关于SAP Analytics Cloud的使用技巧,请关注话题标签:
SAP Analytics Cloud
想要全面了解如何使用SAP Analytics Cloud 进行预测计划,欢迎阅读中文官方指南:
SAP Analytics Cloud 中文帮助手册
