
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- What’s New in SAP HANA Cloud - March 2022
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-25-2022
8:48 AM
We are already almost at the end of the first quarter of 2022, which means we are introducing another bucket of thrilling innovations to SAP HANA Cloud with our recent release. With this blogpost I want to provide you with a summary of the main highlights of the release.
In case you want to get a more in-depth picture of individual functionalities and changes, take a look at our comprehensive release webinar. There, we will also feature some great demos, presented by our product experts.

Innovations in SAP HANA Cloud, data lake
Within the QRC1 2022 release three main highlights have been introduced to the SAP HANA Cloud, data lake: A self-service for upgrades, the possibility for customer auditing, and a path for users to access diagnostic and trace files.
Self-Service Upgrades
For the SAP HANA Cloud, data lake you can now initiate updates on your own. This way upgrades can be executed at the time of your choosing.
The feature offers some clear benefits. First, self-service maintenance provides you with the maximum service availability. Second, this enhancement allows you to better maintain business continuity by executing an upgrade at a time that fits your business’ schedule. Additionally, you are not facing any waiting time because no service requests need to be created.
Customer Auditing
This innovation allows you to enable auditing for your SAP HANA Cloud, data lake. Once enabled, auditing tracks all the security-relevant activities performed on a data lake Relational Engine database (formerly SAP HANA Cloud, data lake IQ).
To configure the auditing, you first need to create a diagnostics service key. Then, create user trace events. Afterwards, create a trace session and start it. Your audit files are retained for 30 days. You can download them via either then HDL Files Rest API or the hdlfscli utility, and then read the audit files using the dbmanageetd utility.

If you do not want to track everything you can adapt the auditing scope according to your needs, e.g. limited to connections, DDL, permissions, and triggers.
Customer-facing diagnostic and trace files
With our most recent release of SAP HANA Cloud users are given a path for accessing diagnostic and trace files for the data lake Relational Engine. One can now create users with access to diagnostic directories. Those can then be used to read the diagnostic logs.
There are numerous options to access the files including using the HDL Files REST API or the hdlfscli utility. The files contain server logs as well as query plans. Get insights into server start up information, table loads, deletes, truncations, transaction ids and server checkpoints. You can also read error and status messages. Thus, this new feature improves the observability and the usage analysis of your data lake Relational Engine instance.

Customer-facing diagnostic and trace data (SAP HANA Cloud, data lake)
Innovations in SAP HANA Cloud, SAP HANA database
There have not only been great new features and enhancements to SAP HANA Cloud, data lake but also to SAP HANA Cloud, SAP HANA database. Multi-Zone replication is now available, integrated machine learning capabilities have been enhanced, data modeling with calculation views offers various new features, and automatic user creation using JWT and SAML is possible. Read more about the specific innovations below.
Innovations in Availability - Multi-Zone Replication
In Q1 2022 Multi-Zone High Availability across two availability zones (AZs) with synchronous replication has been made available in SAP HANA Cloud. This not only offers you high-availability setups in the same availability zone but also to run with multiple zones to increase availability in case of failing zones.
The synchronous replication across two AZs inside of a region (metro setup) allows on the one hand side autonomous, automatic failover and re-establishment of replication. On the other hand, the replica has always the same committed state as its source. Furthermore, the additional synchronous replica in a different AZ allows to achieve a higher SLA of 99.99% uptime, by covering more failure scenarios.

Multi-Zone High-Availability (SAP HANA Cloud, SAP HANA database)
Still, there are some considerations you should keep in mind. It is currently not possible to combine MZ-HA with disaster recovery (DR). Both options displace each other with their general design. Moreover, for the automatic selection there is a downtime when switching to MZ-HA.
To synchronize with the failover of e.g., application servers, which may be co-located in multiple AZs, a very fast manual takeover for MZ-HA is offered.

Manual Takeover in SAP HANA Cloud Central
Innovations in Machine Learning
SAP HANA Cloud offers an impressive set of embedded machine learning capabilities. The Predictive Analysis Library (PAL) offers for example functions in the area of classification, regression, time series analysis, clustering, and others, while the automated predictive library (APL) offers automated predictive functions which are easier to use and therefore also a great fit for non-experts.
With the most recent release alike. Additionally, there have been further improvements to the Python Machine Learning client.
Automated Machine Learning
With the March 2022 release of SAP HANA Cloud, we are offering a couple of new capabilities within the Predictive Analysis Library (PAL). You are now able to compose a PAL-function sequence into a pipeline model for training as well as prediction. Furthermore, new AutoML functions allow to automatically generate and select such pipeline models from data preprocessing, model-fitting, -comparison and -optimal parameter selection for classification and regression ML scenarios. These new AutoML capabilities can be leveraged with the SQL and Python interfaces alike.
The screenshots below demonstrate how to create an AutomaticClassification instance in Python and how to execute the AutomaticClassification-FIT from Python.


These new AutoML- and pipeline functions enable you to build composite, multi-function PAL models and automatically select best possible pipeline models. This way you not only increase your productivity in developing ML scenarios but are also able to build better PAL models and thus ultimately deliver more business value.
Machine Learning Functional Enhancements
Further enhancements have been introduced in PAL to Unified Regression, Classification, Time Series Analysis & Forecasting, Text mining, as well as to the Automated Predictive Library (APL).
The unified regression and classification procedures now implicitly support handling of missing values. Furthermore, segmented, or massive procedure invocation is now supported, i.e., you can build individual regression/classification models for each data by-group in parallel with a single procedure call.
In the area of time series analysis and forecasting, a new Croston TSB function for improved intermittent demand forecasting scenarios and a Stationary test function for detecting trend-stationarity of time series have been introduced. Moreover, segmented or massive time series forecasting is now possible using ARIMA, AutoARIMA, and AdditiveModelAnalysis, generating individual time series forecasting for each data by-group.
Additionally, Text mining, text classification, and term frequency-inverse document frequency (TF-IDF) functions now support the Spanish language.
Moreover, the Automated Predictive Library (APL) 2203 is now available in SAP HANA Cloud. You can get more information on what’s new in APL 2203 here.
Python Machine Learning Client
With QRC1 2022 of SAP HANA Cloud there are various improvements to the Python machine learning client.
First, there are new and enhanced SAP HANA dataframe functions like e.g., feature generation or upsert as well as PAL and APL function enhancements like e.g., isolation forest.
The enhancement highlight is the support for new PAL AutoML capabilities. With the Q1 release there are now methods available to configure, create, and fit AutoML pre-processing-, -classification-, or pipeline scenarios. A progress monitor for auto-ml and the best pipeline selection has been added as well as a best pipeline report and a pipeline visualization option for auto-ml.
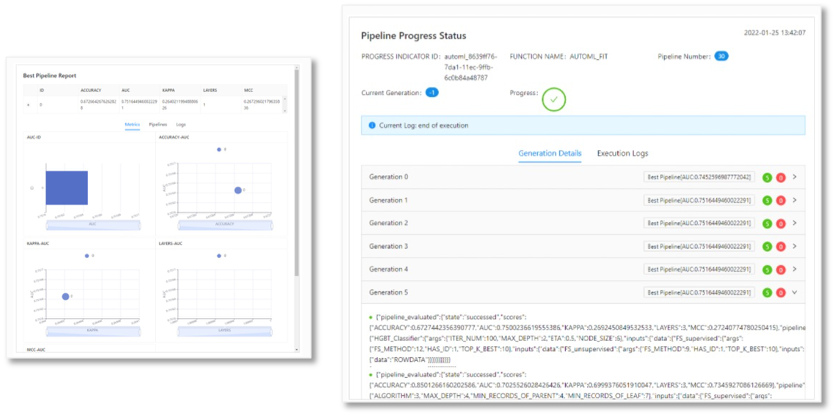
Best Pipeline report and AutoML progress monitor
If you want to know all details about the enhancements made to Python and the R Machine Learning client, you can find a complete list of Python hana-ml 2.12 enhancements here and a complete list of the latest R machine learning client 2.11 enhancements see here.
Innovations in Calculation View Modeling
Calculation views are used to create database content for the SAP HANA database in SAP HANA Cloud. They allow users to do more advanced slices on the available data. They are e.g., used for analyzing operational data marts or running multidimensional reports on revenue, profitability, and more.
With the March 2022 release of SAP HANA Cloud several features regarding calculation views modeling have been introduced. Four new features are highlighted below. You are now able to control whether preview queries in SAP BAS (SAP Business Application Studio) are executed automatically, you receive enhanced control over where filters are applied in federated scenarios, and additional options to prune data sources and thus reduce resource consumption and increase query performance.
Data Preview in SAP Business Application Studio
Users can now decide whether data preview queries in SAP Business Application Studio are executed automatically or not. This means a workspace parameter is available to control whether a data preview query is automatically executed or only after an explicit refresh request. Thus, you are now able to adapt the default queries that are automatically generated during data preview before they are executed.


The automatic execution of expensive and potentially irrelevant queries during the data preview is avoided and resources consumption can be reduced because of this enhancement. It also allows a faster preview of data queries through adapting them to your specific use case.
The second enhancement regarding the data preview is the possibility to view and get insights into SQL hierarchies during previewing your data. This way you can easily check hierarchies as well as effortlessly extract the SQL statements behind the hierarchy navigation. The feature thus enables faster development and simplified debugging. Note, that it is only possible for SQL hierarchies.


Filter application in Federated Scenarios
The next improvement for calculation views is the increased control about where filters are applied in federated scenarios. You can now map input parameters to remote views (via the parameters option of virtual tables) and transfer values into remote views (SQL and Calculation views). This provides the opportunity to gain more control about the execution of filters that are based on input parameters.
Those enhancements allow you to not only integrate remote scenarios in a straightforward manner but also to improve the performance in federated scenarios adding further modeling options.
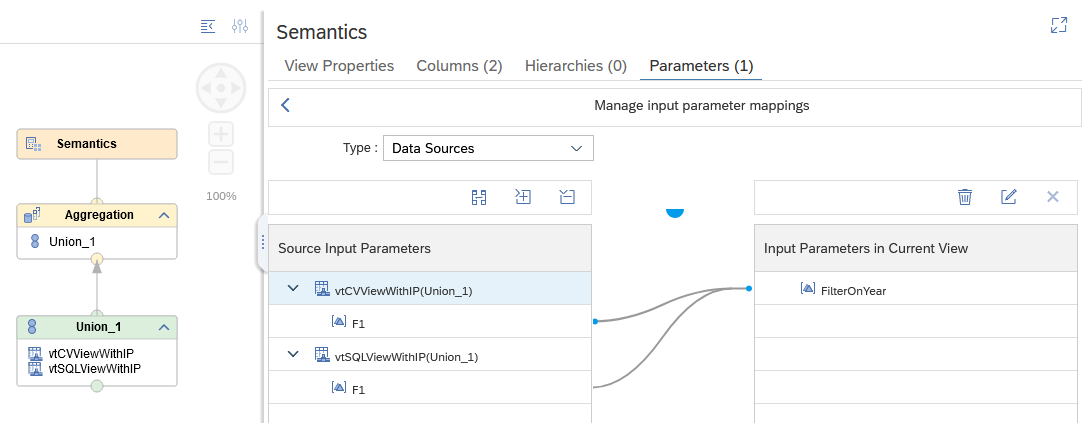

Pruning of data sources
One last new feature regarding the calculation views in SAP HANA Cloud is the possibility to prune data sources that do not contribute to requested columns in a union. With the newest release, you are now able to adapt the pruning of union data sources to query requirements by indicating that the focus of the analysis is e.g., on certain measures. Data will be pruned if no requested column, that is tagged as “Focus Column”, is mapped from the data source. "Focus Columns" can be selected from attributes and measures. In situations in which a data source of a union node does not deliver values to the requested Focus Columns, the source will be automatically pruned.

Excluding irrelevant data sources early not only improves the performance of your database query but also reduces the resource consumption and improves the overall efficiency.
You can see an example of data pruning below:


SalesOrders2020 will be pruned, even though it would deliver values for non-focus columns. This meansonly data from salesOrders2019 will be returned, salesOrders2020 will be excluded from processing early.
If you want to learn more about the innovations in calculation view modeling, you should definitely check out jan.zwickel blog.
Innovations in Security - Automatic User Creation
With our QRC1 2022 release of SAP HANA Cloud dynamic user creation is now supported within the SAP HANA database. Using LDAP (Lightweight Directory Access Protocol) authorizations, which is an open, vendor-neutral, and industry-standard application protocol for accessing corporate networks, user data can be created automatically in SAP HANA Cloud based on JWT (JSON Web Tokens) and SAML (Security Assertion Markup Language). After the creation, the user data can be managed in the respective LDAP groups.
This enhancement bridges an existing gap for automated user creation which is now possible with the two named protocols. It allows the full automation of user creation for SAP HANA systems using the two options together. The picture below shows the automation.

Other Innovations and News
Innovations in the SAP HANA Database Explorer
Not only SAP HANA Cloud, SAP HANA database and SAP HANA Cloud, data lake has been enhanced within our most recent release, but our tooling for both has also been improved to make various administrative tasks more convenient for you. For instance, you can now create a connection to an SAP HANA Cloud data lake file container using the “Add Database” dialog, connect to an SAP HANA Cloud database using SSO with JWT and remove multiple databases at once.
View and manage items in a data lake file container
With the most recent release you can create a data lake file container connection allowing various new actions that will improve your productivity and user experience when working with a SAP HANA Cloud data lake file container.
You can now view the properties of the file container e.g., including the REST API end point. Locating files or subfolders within a file container also becomes possible. Furthermore, you can observe file and folder properties such as file size and last modified time. The update also allows you to upload, download, and delete files from now on. Finally, you can examine the contents of text files (such as csv) and open them (for example, a .csv file), providing progressive loading.


These improvements provide you with another way to interact with the data lake files service in addition to REST API and HDLFSCLI.
Single Sign-On (SSO) with JSON Web Tokens (JWT)
Once SSO has been configured in the SAP HANA cockpit, the configured database can be accessed in the SAP HANA database explorer and will use the mapped credentials. The add database dialog now has an option to enable SSO for a new connection assuming JWT SSO has been configured in the SAP HANA cockpit.

Additional details can be found in the SAP HANA Cloud Database Administration with SAP HANA Cockpit guide under the topic Enable JWT SSO Login.
Remove database dialog
There is now a new icon enabling the selection of one or more databases to be removed.

HANA Database Explorer (DBX) Plug-In for Visual Studio Code and BAS
An updated version of the DBX Plug-In is now available. The plugin now allows to browse the content of the database with context sensitive views (Database and HDI Container) for the content within the database. Sample would be the list of tables or schemas.
There is now an option to save SQL files that are used within the tool for reload or other purposes.
More information about the HANA Database Explorer Plugin for MS Visual Studio can be found in jonathan.bregler’s blog post.
HANA Deployment Infrastructure (HDI) Innovations
The SAP HANA Deployment Infrastructure (HDI) provides a service that enables you to deploy database development artifacts to so-called containers. This service includes a family of consistent design-time artifacts for all key SAP HANA database features, which describe the target (run-time) state of SAP HANA database artifacts, for example: tables, views, or procedures.
With the March release of SAP HANA Cloud two major new features have been added. First, during HDI make processes multiple errors are now reported. Second, the Service Manager can now be used to create HDI containers.
HDI: returning multiple deployment errors
During a failing SAP HANA Deployment Infrastructure (HDI) make process only the first error message used to be reported. With our most recent release of SAP HANA Cloud subsequent error messages are stated to provide you with a better analysis for failures. You will get a clearer picture of the reason for the failure of the make process.
Thus, developers can now identify errors in make processes with more confidence while additionally the effort is reduced to find the reason for the failure.
A dedicated blog post on this topic by product expert volker.saggau can be found here.
Support for HDI containers created by SAP Service Manager
You can now add HDI containers, you have created using the SAP Service Manager (running on SAP Business Technology Platform (SAP BTP)), using the “Add Database” dialog in the SAP HANA database explorer. This enables you to now create database containers at runtime and replaces the instance manager, which is being deprecated in the SAP BTP.
This innovation allows users to conveniently find and add containers that are created during runtime by SAP Service Manager in the SAP HANA database explorer.
Additional options for exporting HDI deployment infrastructure for containers
With the Q1 2022 release of SAP HANA Cloud, administrators of HDI service layers can now be enabled to export HDI containers to tables or files, import containers into a cloud storage to act as cloud mass-storage devices, and to extend the syntax of an HDI container export to use cloud mass-storage.
From now on there is no need for additional storage in SAP HANA Cloud for HDI container exports. Thus, there is no limitation because of the limits of the underlying cloud storage for the export of HDI containers anymore.
Multi-Model Innovations
New SQL functions for the JSON Document Store
With the first release of SAP HANA Cloud in 2022 we are adding some new functionalities to the JSON Document Store. Looping over JSON arrays in SQL Script is now possible. Additionally, it is possible to retrieve the cardinality (the number of elements) of an array.
The new functions provide better ways to query and update JSON documents, especially arrays.
Hexagon Grid generator
As you may know, square and rectangle grid generators are already available in SAP HANA Cloud since the December release of SAP HANA Cloud. Now, these are complemented with the new hexagon grid generator. The functions can be used to generate a set of grid cells which can be used to group geometries for better analysis and visualization. With a grid system each point in a map can be given an identifier, an address to refer to. This allows you for example to count objects that pass grid cells.
Support of vector tiles to return geographic data to the client application
With the most recent release of SAP HANA Cloud, we introduced a new functionality based on industry standards to speed up the transportation of large spatial data volumes to a client. Thus, you are now able to return vector data that has been clipped to the boundaries of each tile by SAP HANA Cloud to the client's software system.
This new feature comes along with some major benefits for your work with SAP HANA Cloud. First, the bandwidth between a tile service and the client is significantly lower as the vector tiles are highly compressed. Furthermore, maps can be styled dynamically on client side without the need to download new tiles. Additionally, the interaction capabilities now include rotation, tilt, smooth zooming and scaling of maps, and feature highlighting. Moreover, map feature metadata can be queried as it is already stored in the tile set. The new functions also enable straightforward and easy integration into third-party vector tile services.
Graph Traversal Statements
With the Q1 release of SAP HANA Cloud we have added a new graph method for the graph traversal statements: the traverse Dijkstra. This statement adds another fundamental building blocks to the GRAPH language for database procedures. The new traversal operation can be used to implement custom algorithms, e.g. for identifying the 3 nearest Pizza restaurants given a street network.
Tutorial: Take Action Following an SAP HANA Cloud Database Alert with SAP Automation Pilot
My colleague, SAP HANA Product Expert, daniel.vanleeuwen has recently published a new tutorial on SAP Developer Tutorials.
Use his tutorial to learn how the SAP Automation Pilot can be used together with the SAP Alert Notification Service to react to an SAP HANA database alert. The tutorial is part of a tutorial group focusing on SAP HANA Cloud alerts and metrics. So, if this made you curious, check out the tutorial group here.

Did this summary make you curious about the entire scope of the Q1 2022 release of SAP HANA Cloud? If that is the case, you can find a summary of all the innovations introduced to SAP HANA Cloud here.
If you are looking for more details on the latest features and updates to SAP HANA Cloud, then make sure to take a look at our ‘What’s new in SAP HANA Cloud’ webinar: Watch here. Together with my colleagues from the SAP HANA Cloud Product Management team, I will share more details about these highlights.
What’s coming up?
Besides the exciting innovations that have been part of our QRC1 2022 roll-out of SAP HANA Cloud, there are some more thrilling news we want to share.
SAP HANA Service (Neo) self-service migration tool
By mid of April, we are planning to offer a self-service migration tool from SAP HANA Service on Neo to SAP HANA Cloud. This feature simplifies and accelerates your move to SAP HANA Cloud. The SAP HANA Cloud self-service migration tooling is now available supporting the SAP HANA Service for SAP BTP (Neo) as a source database, in addition to already supported SAP HANA Services for Cloud Foundry environments. This self-service cloud migration tool does the database validations and performs necessary checks as well as moves the database objects, schemas, and the data from the SAP HANA Services for SAP BTP Neo environments to SAP HANA Cloud.
Further updates
We also do not want to miss the opportunity to highlight some of the upcoming innovations for Q2 2022. With the QRC2 release of SAP HANA Cloud, we are once again broadening our data center landscape with a new data center for Google Cloud Platform in APJ.
Additionally, we are planning to offer near-zero downtime upgrades for the data lake with the next release.
To see all innovations that are planned for the upcoming quarters, please visit our SAP Road Map explorer here.
Apart from that, don’t forget to follow the SAP HANA Cloud tag to not miss any updates! In case you have missed the What’s New webinar in Q4 2021, you can find it and all future webinars in this playlist on YouTube.
In case you want to discuss some of the outlined innovations or have any other questions related to SAP HANA Cloud, feel free to post them in our SAP HANA Cloud Community Q&A or in the comments below.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA Cloud, SAP HANA database,
- SAP HANA
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
88 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
65 -
Expert
1 -
Expert Insights
178 -
Expert Insights
280 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
330 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
408 -
Workload Fluctuations
1
Related Content
- SAP Partners unleash Business AI potential at global Hack2Build in Technology Blogs by SAP
- It’s Official - SAP BTP is Again a Leader in G2’s Reports in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Release 2024.08 in Technology Blogs by SAP
- Deep dive into Q4 2023, What’s New in SAP Cloud ALM for Implementation Blog Series in Technology Blogs by SAP
- S/4HANA 2023 FPS00 Upgrade in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 11 | |
| 10 | |
| 9 | |
| 9 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 |