Within the time frame of 2022 QRC1, several new calculation view features have been released in SAP HANA Cloud that can be used with SAP Business Application Studio beginning of April 2022. Some of these features are highlighted below.
You can find examples that illustrate the individual features
here. An overview of features of other releases can be found
here.
Data Preview: Toggle between automatic and manual execution
In the past, data preview queries were executed automatically, when starting a data preview. In case of expensive queries this can be unwanted given that typically only a reduced query is of interest.
With the new option it is possible to only execute the data preview query on request. Therefore, the query can be adapted, e.g., filters added, columns removed, before executing the query.
To switch between the different behaviors go to the Preferences and search for the term "manual refresh". Choose to either automatically execute the query or to only execute the data preview query on explicit request (e.g., after the query has been modified):

New option can be found in Preferences

Choose between manual or automatic refresh
Data Preview: Gain insight into hierarchies
It is now possible to show hierarchies during data preview. This can be used to validate the hierarchy.
The data preview option is only available for SQL hierarchies. These type of hierarchies are generated when choosing either the Hierarchy Type "Auto" or "SQL hierarchy views" in the View Properties

Options to generate SQL hierarchy views

Example hierarchy during data preview
Using the button "SQL" the SQL query behind the hierarchy display is shown. This can be used as a starting point to create own SQL navigation queries or to generate a tabular format of the current hierarchy drill-down.
Federated Scenario: Input parameter mapping to remote views
Information entered in query prompts can be processed using input parameters in Calculation Views.
A new option is available to map these input parameters also to parameters of remote SQL and Calculation Views. With this it is, for example, easier to control at what processing stage and how a filter is applied:

Mapping of an input parameter to remote views
Performance: Column Based Pruning
Several Union Pruning techniques exist that help to exclude early the processing of data sources of union nodes. Excluding data sources early can have a huge effect in terms of query runtime and memory reduction. For an overview of the different pruning techniques, see the
SAP HANA Performance Guide for Developers.
Until QRC1 of 2022, the criteria for excluding data sources were based on filter values. With column based pruning a new option is available that prunes data sources based on whether a data source is mapped to a so called "Focus Column". If a data source does not contribute any Focus Column and a Focus Column is requested in the query then the data source is pruned.
This pruning technique can be used, for example, if an analysis is focusing only on data sources that contribute to a measure of interest. In this situation the measure can be defined as a Focus Column.
In the following example, measure "SALES" is only mapped for data source "SalesOrders2019" but not for data source "SalesOrders2020":

Mapping in Union: Measure "SALES" is only mapped from the first data source
Measure "SALES" is defined as Focus Column:

Measure "SALES" is defined as Focus Column
As a consequence, data source "salesOrders2020" will be pruned because it does not deliver values for the Focus Column "SALES". This means that the result will only contain entries with year "2019":

Only values from data source "SalesOrders2019" appear in the result
If column based pruning is switched off,

Column based pruning is switched off
records of both sources are delivered:

Records from both sources are contained in the result but the value of "SALES" is NULL for "2020"
Given that measure "SALES" is NULL for all records from "SalesOrders2020", no bar appears for the value of measure "SALES" for year "2020".
Column based pruning can be an effective means to exclude data sources early if these data sources do not contribute values for "Focus Columns". Excluding data sources early during processing can significantly reduce runtime and memory consumption.
Model Insights: Column Based Pruning
A Where Used button is now available that lists all places where elements like input parameters, calculated columns or restricted columns are used within the current model.

Where used button
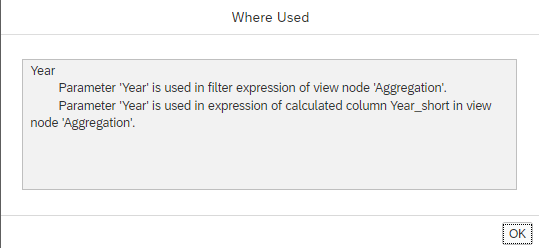
Example: places where input parameter is used
This information can be helpful e.g., during refactoring steps or during debugging of a view.
