
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Integrating SAP Signavio Process Intelligence and ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-03-2022
2:45 PM
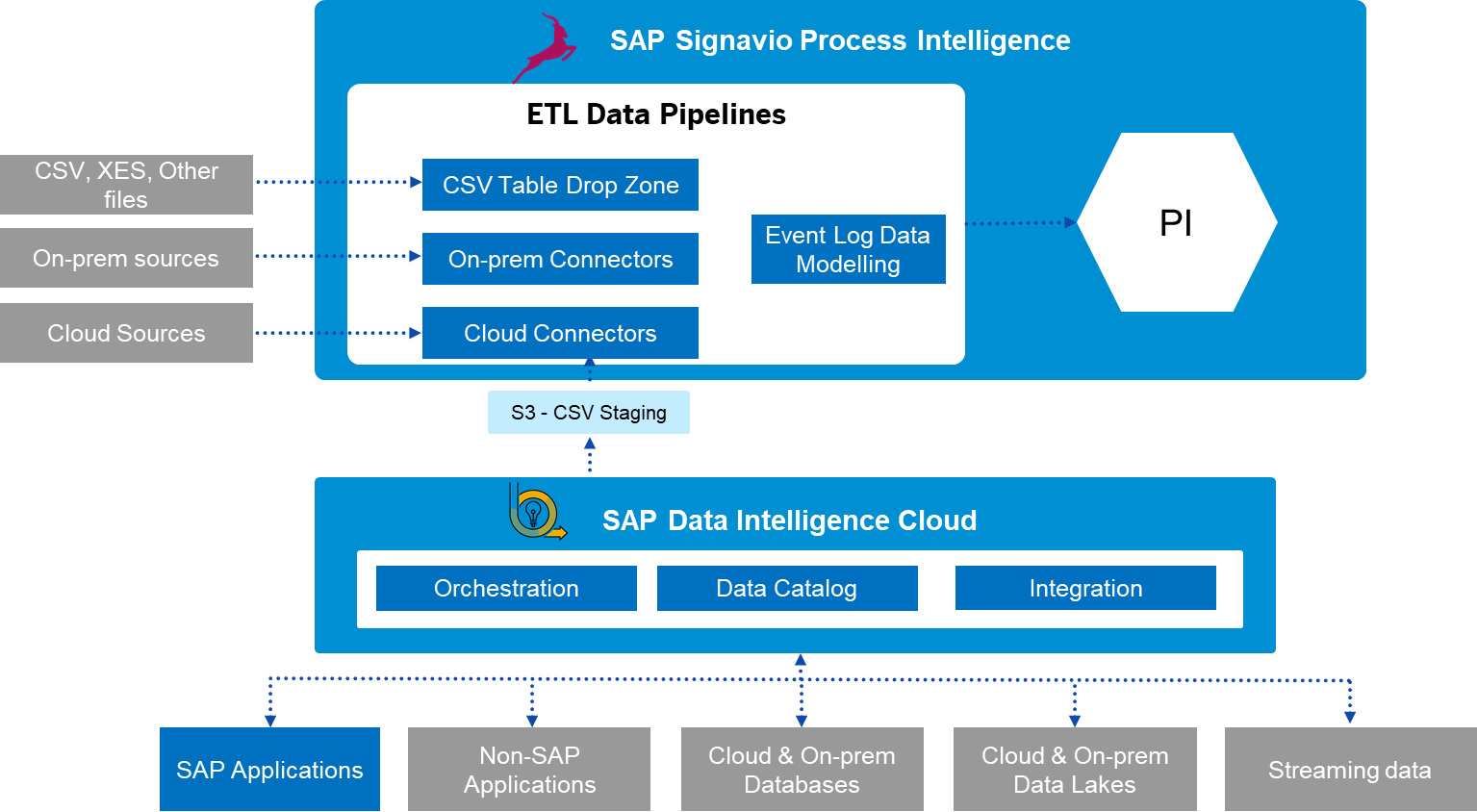
Leveraging an enterprise-grade data integration and data orchestration engine in conjunction with a best-in-class process mining engine yields very powerful synergies, as I recently explained in my previous blog post on this topic.
July 2022 Update: we now published also a third blog post for this series, where fabioferrari covers another concrete example that leverages the recently released ingestion API. The products now communicate directly, using a dedicated operator in SAP Data Intelligence Cloud. The related sample artifacts are share in GitHub project within the SAP Samples repository. The approach described in the post below, which was instead using a staging are, is therefore outdated now, despite still working.
Every process mining project will benefit from a streamlined data integration capability. In particular, the synergy between SAP Signavio Process Intelligence and SAP Data Intelligence Cloud can enable some significant advantages:
In this additional post I’ll describe a concrete example, developed jointly with my colleagues thorsten.hapke and Sebastian Lesser, that shows how you can use a SAP Data Intelligence pipeline to feed data into SAP Signavio Process Intelligence. This first approach uses a staging area, that we implemented in an Amazon S3 bucket, and can be applied already on the current versions of the products.
Note that the staging area can be implemented also on storage layers different than AWS S3, like for example SAP HANA Cloud. The implementation would be totally similar.
In a few months, likely by summer 2022, we plan to deliver a direct integration, bypassing the need for a staging area and providing a dedicated operator to use in DI Cloud pipelines. (Note that this reflects the current state of planning, and might be changed by SAP at any time, as with any of our roadmap statements!).
The example implemented in this blog reads in particular an ABAP CDS view from an S4/HANA system, and feeds the data into Signavio Process Intelligence. But the approach can actually be applied to any of the numerous sources supported by SAP Data Intelligence Cloud, and can be enriched also with any kind of processing and transformation in the middle.
First of all, let’s open the DI Cloud pipeline modeler, and create a new pipeline. We’ll use our recent generation 2 operators in this example. In this new pipeline, drag and drop the “Read Data From SAP Application” operator, as the starting step:
Click on the configuration of the operator, select your S4 system in the ABAP Connection field (here we assume you have already configured your connection in DI’s Connection Management), select “Initial Load” as Transfer Mode, and select your target CDS view by clicking on the “browse” button in the Object Name field:
After that, add a “Structured File Producer” operator in your pipeline, connecting it to the output of the previous operator:
Click on the configuration of the operator, and on the “Edit” button of its Target. Here, you will select the connection to your S3 bucket (which we assume you already setup in DI’s Connection Management) and define the target path to the CSV file where DI will dump the content of the CDS View. Also, make sure to enable the “Header” radio button, so that column names are included in the output file:
Now, you can complete the pipeline by just adding a Wiretap operator (for debugging purposes only), and a Graph Terminator.
To execute a first test, click on “Run As” to test the pipeline, enabling snapshot configuration and recovery configuration for full resiliency:
You can then verify the correct execution of the pipeline through the Wiretap UI:
Also, you can open DI’s Metadata Explorer, and check the new CSV file which was created in the S3 bucket:
The pipeline is ready, now you would only have to schedule its execution so that it gets triggered automatically with the required frequency.
In SAP Signavio Process Intelligence’s UI, click on the “Manage Data” button, and there in the “Data Sources” tab. Here, make sure you configured a connection to the S3 bucket we’re using as staging area, or otherwise create a new one with the “New data source” button:
In our case, we created a new dedicated data source, named DataIntelligenceS3:
Then move to the “Integrations” tab, and create a new Integration, leveraging the previously created data source:
Click on “Add Table”, and select the CSV file produced by your pipeline:
Click on “Next”, and then select all columns:
Click on “Next”, and then select the column(s) which act as primary key:
Finally, click on “Extract”:
Verify the successful execution of the extraction:
The data is now ready to be used for process mining!
Stay tuned for more content that we’ll be publishing in the coming weeks and months, while we develop and evolve this integration.
If you’re interested in this topic, don’t hesitate to reach out to us via the SAP BPI Community and the SAP Data Intelligence Community.
July 2022 Update: we now published also a third blog post for this series, where fabioferrari covers another concrete example that leverages the recently released ingestion API. The products now communicate directly, using a dedicated operator in SAP Data Intelligence Cloud. The related sample artifacts are share in GitHub project within the SAP Samples repository. The approach described in the post below, which was instead using a staging are, is therefore outdated now, despite still working.
Every process mining project will benefit from a streamlined data integration capability. In particular, the synergy between SAP Signavio Process Intelligence and SAP Data Intelligence Cloud can enable some significant advantages:
- Deliver enterprise-grade data integration and orchestration for process mining, leveraging the wide and deep capabilities built into Data Intelligence, which include native connectivity to SAP applications and to all major data lakes, databases, messaging systems, non-SAP systems and open-source technologies
- Easily connect sources across both cloud and on-premise landscapes, leveraging the SAP Cloud Connector to speed up and simplify network setup
- Support the data integration efforts with a built-in data catalog, to provide data discovery and profiling, and self-service data preparation
- Enforce proper data quality monitor, to ensure reliability of the insights you get out of your process mining
- Provide flexible and powerful data pipelines to transform, adjust or pre-process the data if and when needed, before ingesting it into the process mining engine.
In this additional post I’ll describe a concrete example, developed jointly with my colleagues thorsten.hapke and Sebastian Lesser, that shows how you can use a SAP Data Intelligence pipeline to feed data into SAP Signavio Process Intelligence. This first approach uses a staging area, that we implemented in an Amazon S3 bucket, and can be applied already on the current versions of the products.
Note that the staging area can be implemented also on storage layers different than AWS S3, like for example SAP HANA Cloud. The implementation would be totally similar.
In a few months, likely by summer 2022, we plan to deliver a direct integration, bypassing the need for a staging area and providing a dedicated operator to use in DI Cloud pipelines. (Note that this reflects the current state of planning, and might be changed by SAP at any time, as with any of our roadmap statements!).
The example implemented in this blog reads in particular an ABAP CDS view from an S4/HANA system, and feeds the data into Signavio Process Intelligence. But the approach can actually be applied to any of the numerous sources supported by SAP Data Intelligence Cloud, and can be enriched also with any kind of processing and transformation in the middle.
Configuring an SAP Data Intelligence Cloud pipeline to move data from an ABAP CDS View to a staging area
First of all, let’s open the DI Cloud pipeline modeler, and create a new pipeline. We’ll use our recent generation 2 operators in this example. In this new pipeline, drag and drop the “Read Data From SAP Application” operator, as the starting step:

Click on the configuration of the operator, select your S4 system in the ABAP Connection field (here we assume you have already configured your connection in DI’s Connection Management), select “Initial Load” as Transfer Mode, and select your target CDS view by clicking on the “browse” button in the Object Name field:

After that, add a “Structured File Producer” operator in your pipeline, connecting it to the output of the previous operator:

Click on the configuration of the operator, and on the “Edit” button of its Target. Here, you will select the connection to your S3 bucket (which we assume you already setup in DI’s Connection Management) and define the target path to the CSV file where DI will dump the content of the CDS View. Also, make sure to enable the “Header” radio button, so that column names are included in the output file:

Now, you can complete the pipeline by just adding a Wiretap operator (for debugging purposes only), and a Graph Terminator.

To execute a first test, click on “Run As” to test the pipeline, enabling snapshot configuration and recovery configuration for full resiliency:

You can then verify the correct execution of the pipeline through the Wiretap UI:

Also, you can open DI’s Metadata Explorer, and check the new CSV file which was created in the S3 bucket:

The pipeline is ready, now you would only have to schedule its execution so that it gets triggered automatically with the required frequency.
Ingesting the data into SAP Signavio Process Intelligence
In SAP Signavio Process Intelligence’s UI, click on the “Manage Data” button, and there in the “Data Sources” tab. Here, make sure you configured a connection to the S3 bucket we’re using as staging area, or otherwise create a new one with the “New data source” button:

In our case, we created a new dedicated data source, named DataIntelligenceS3:

Then move to the “Integrations” tab, and create a new Integration, leveraging the previously created data source:

Click on “Add Table”, and select the CSV file produced by your pipeline:

Click on “Next”, and then select all columns:

Click on “Next”, and then select the column(s) which act as primary key:

Finally, click on “Extract”:

Verify the successful execution of the extraction:

The data is now ready to be used for process mining!
Further steps
Stay tuned for more content that we’ll be publishing in the coming weeks and months, while we develop and evolve this integration.
If you’re interested in this topic, don’t hesitate to reach out to us via the SAP BPI Community and the SAP Data Intelligence Community.
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
299 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
423 -
Workload Fluctuations
1
Related Content
- AI Core - on-premise Git support in Technology Q&A
- Up Net Working Capital, Up Inventory and Down Efficiency. What to do? in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 40 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |