

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Import Event Push of Configuration Text Tables to ...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Ryan-Crosby
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-09-2022
9:39 PM
Introduction
I was recently posed with a problem that needed a new solution for our planned S4 migration in a few weeks. How to get the configuration domain text data to an external database to retain some existing reporting capabilities? I'm betting that a lot of folks work in heterogenous landscapes and sometimes it requires getting creative with how to tackle a problem. I have seen a couple of approaches in the past and have to admit that I'm not a fan of either, but I'll let you decide for yourself which one is least preferred. First example - two synchronous ABAP Proxies of megalith proportions statically defined to return data on several dozen configuration domains based on daily or weekly frequency. The second - several recurring job instances throughout the day (four or five maybe) that extract the data whenever change pointers are detected on dependent business objects, and saved as files on the application server, which requires some other process to fetch the data and load it. Is a many times daily, daily, or weekly cadence appropriate given the relatively infrequency that configuration tables are updated in a productive environment?
Proposal
What if there were an event that could push the data for a pit stop into Integration Suite for some transformation before reaching its final destination in the external database? I spent a few hours pondering the question and came up with the following: Implement BADI CTS_IMPORT_FEEDBACK along with BRF+ to evaluate customizing requests and push table names to Integration Suite. Start with an iterating splitter, and sprinkle a little graphical mapping, content enricher via OData, and XSL transform and arrive at XML that can be processed by the JDBC adapter to initiate stored procedures for UPSERT. What follows is the culmination of a day and a half of build, learning, and experimentation with a couple of gotchas along the way.
ABAP
The original intent was to execute the entirety of ABAP within this BADI method, but after I had completed the full service layer in Integration Suite and worked backward into this method, I discovered that it executes in client 000, and received a ST22 dump when the BRF+ application could not execute. The BRF+ code was pushed into the RFC function module. Consequently, after working in SAP software for 14 years and having never logged in to client 000, I have for the first time (SM59 destination), and doubtful I ever would again. You may also wonder why I wouldn't simply read keys and use a combination of RTTS and web services to push the data to Integration Suite. Beyond avoiding the megalith mentioned above, dealing with situations where some columns are ignored for certain tables, and determining appropriate structure, it certainly wouldn't be blog worthy and you wouldn't be reading this! After following the remaining steps I think it will be clear why I decided to go with the chosen route.
METHOD if_ex_cts_import_feedback~feedback_after_import.
DATA: corr TYPE trwbo_request,
tables TYPE tt_tabnames.
* Read object keys for import
CLEAR: tables.
LOOP AT requests INTO DATA(request).
CLEAR corr.
CALL FUNCTION 'TR_READ_REQUEST'
EXPORTING
iv_read_objs_keys = 'X'
iv_trkorr = request-trkorr
CHANGING
cs_request = corr
EXCEPTIONS
error_occured = 1
no_authorization = 2
OTHERS = 3.
IF sy-subrc = 0.
* Record any tables for evaluation in BRF+
LOOP AT corr-keys INTO DATA(key)
WHERE object = 'TABU'.
APPEND key-objname TO tables.
ENDLOOP.
ELSE.
* Should never happen based on data requested in FM
ENDIF.
ENDLOOP.
* Sort and remove duplicates and pass to RFC for
* communication
SORT tables.
DELETE ADJACENT DUPLICATES FROM tables.
CALL FUNCTION 'ZCA_WS_CONFIG_UPDATE_DISPATCH'
DESTINATION 'CFGUPDDISP'
EXPORTING
table = tables.
ENDMETHOD.Originally, this RFC was only intended to be a shell for my enterprise service consumer proxy generation (we do not have an ESR), but after experiencing the client 000 problem it became a suitable surrogate to execute the BRF+ application in the appropriate client, as well as the ABAP proxy.
FUNCTION zca_ws_config_update_dispatch.
*"----------------------------------------------------------------------
*"*"Local Interface:
*" IMPORTING
*" VALUE(TABLE) TYPE TT_TABNAMES
*"----------------------------------------------------------------------
DATA:timestamp TYPE timestamp,
t_name_value TYPE abap_parmbind_tab,
name_value TYPE abap_parmbind,
r_data TYPE REF TO data,
input TYPE zzca_ws_config_update_dispatch,
proxy TYPE REF TO zco_zws_config_update_dispatch.
CONSTANTS: function_id TYPE if_fdt_types=>id VALUE '005056977E091EECA1F05A7D5FE1B25F'.
* Set timestamp for processing and move input data into reference
GET TIME STAMP FIELD timestamp.
name_value-name = 'TT_TABNAMES'.
GET REFERENCE OF table INTO r_data.
cl_fdt_function_process=>move_data_to_data_object( EXPORTING ir_data = r_data
iv_function_id = function_id
iv_data_object = '005056977E091EECA1F05DC93384D25F' "TT_TABNAMES
iv_timestamp = timestamp
iv_trace_generation = abap_false
iv_has_ddic_binding = abap_true
IMPORTING er_data = name_value-value ).
INSERT name_value INTO TABLE t_name_value.
CLEAR name_value.
TRY.
* Execute BRF+ function
cl_fdt_function_process=>process( EXPORTING iv_function_id = function_id
iv_timestamp = timestamp
IMPORTING ea_result = input-table-item
CHANGING ct_name_value = t_name_value ).
* Only execute proxy if any tables of interest are found
IF input-table-item[] IS NOT INITIAL.
CREATE OBJECT proxy.
CALL METHOD proxy->zca_ws_config_update_dispatch
EXPORTING
input = input.
COMMIT WORK.
ENDIF.
CATCH cx_fdt.
* Do what on error?
CATCH cx_ai_system_fault.
* Do what on error?
ENDTRY.
ENDFUNCTION.BRF+
I find BRF+ to be an often underutilized gem in the system. If I have a simple question for the system to answer, pass the necessary input and let it determine the outcome. The true beauty is that I can add or remove a table for this scenario without writing a single line of ABAP!!
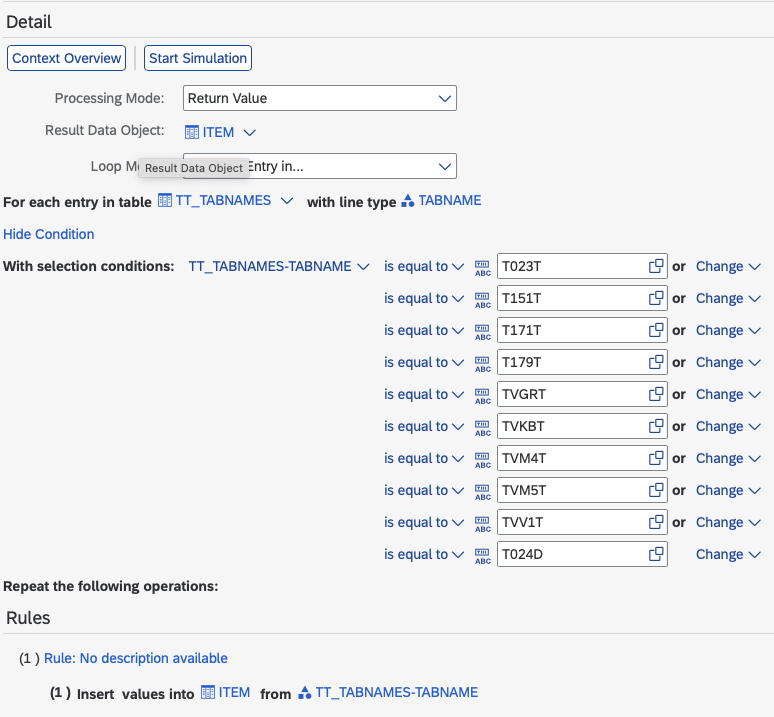
Integration Flow
The first two steps of the flow are setup steps to determine the backend OData host and split the incoming message by each table. The last three steps will be presented in more detail below.

Full E2E Integration Process
Graphical Mapping
This mapping serves the purpose of mapping a backend table name into four corresponding bits of data... stored procedure, OData service name, resource, and query using a combination of the fixValues function and a couple of simple Groovy scripts. Folks could be wondering why not use value mapping, but I feel like that is a lot of overkill to maintain several input fields instead of simple 1:1 mappings with fixValues. Also, note the use of the query parameter is used because for one table we don't want the full field list. If we use $select query options for one table in the OData adapter we must maintain it for all (Tried the empty string and it did not work). This leaves me with a choice dilemma:
Option 1 - Add a query parameter, which is more stuff to maintain in the graphical mapping
Option 2 - Do not add query parameter and handle stripping of extra fields in XSL transform
Since I'd rather not select fields and transport extra data over the network that is of no consequence, I went with the first option.
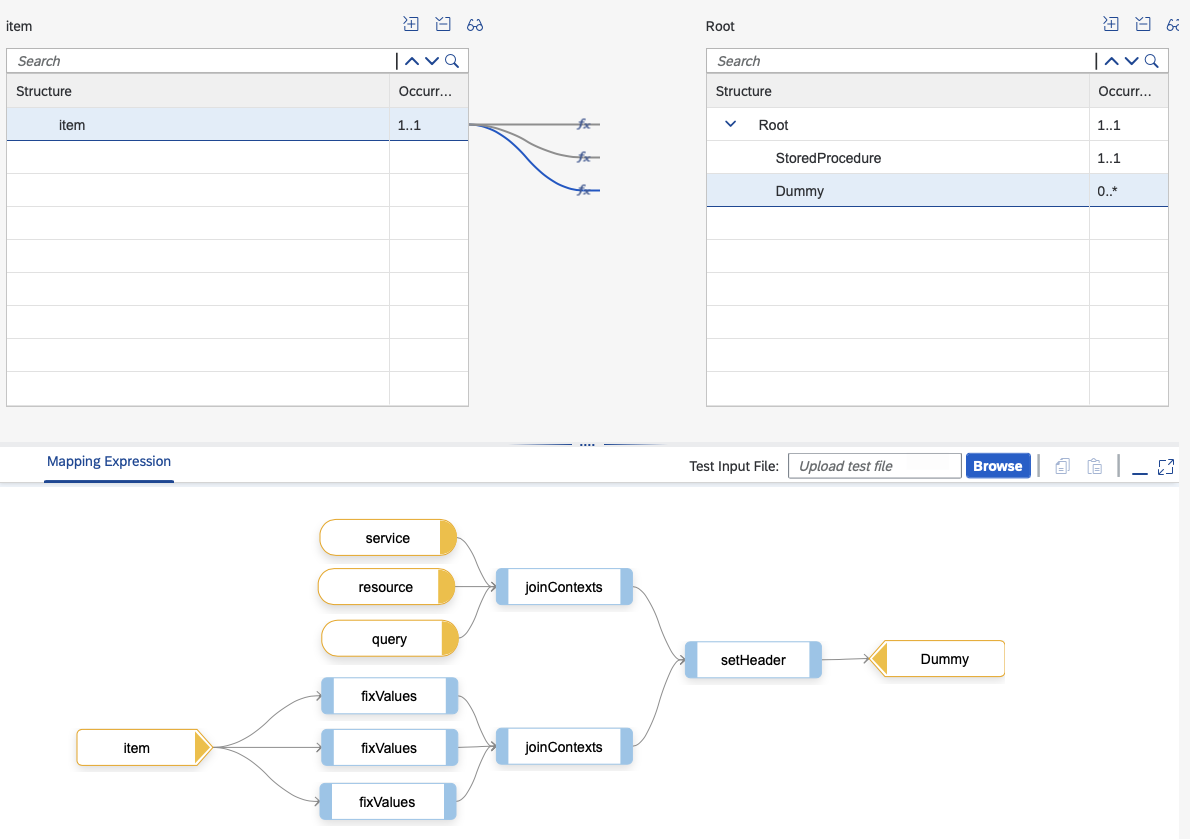
Graphical mapping for OData/Stored procedure determination
The setHeader function should be self explanatory, but the joinContexts function is to establish a queue like some of the older PI/PO functions. I could not find an equivalent in Integration Suite, so I constructed my own (Feel free to share if there is some out of the box option that I could not find).
// Insert message headers
def void setHeader(String[] keys, String[] values, Output output, MappingContext context){
def i = 0;
while(i < keys.size()) {
context.setHeader(keys[i], values[i]);
i++;
}
}
// Create context queue to match keys with values
def void joinContexts(String[] input1, String[] input2, String[] input3, Output output, MappingContext context){
output.addValue(input1[0]);
output.addValue(input2[0]);
output.addValue(input3[0]);
}Content Enricher via OData
The first image includes basic host and service metadata that is handled in the first step, and the graphical mapping step. I was unsure if externalized parameters and headers would be concatenated like two headers, so I went with this option. If externalized parameters do work in this way, then I could eliminate the first step in the flow. The second image shows the processing tab with the other metadata required for the OData service call. You may be wondering at this point... what about V2 vs. V4? For the 10 tables I need to push, I was able to identify 2 services that are both V2. If I have to cross that bridge in the future, I can manage with the addition of a version metadata field in the graphical mapping and an appropriate routing step.
OData Connection Information

OData Processing Information
The following XML is the result after the content enricher via OData using the combine algorithm. The nice feature/outcome being that I did not have to statically define any table structures or field types anywhere in the solution.
<?xml version='1.0' encoding='UTF-8'?>
<multimap:Messages xmlns:multimap="http://sap.com/xi/XI/SplitAndMerge">
<multimap:Message1>
<Root>
<StoredProcedure>sp_TVV1T</StoredProcedure>
</Root>
</multimap:Message1>
<multimap:Message2>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID>T01</AdditionalCustomerGroup1_ID>
<AdditionalCustomerGroup1Text>Tier 1</AdditionalCustomerGroup1Text>
</AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID>T02</AdditionalCustomerGroup1_ID>
<AdditionalCustomerGroup1Text>Tier 2</AdditionalCustomerGroup1Text>
</AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID>T03</AdditionalCustomerGroup1_ID>
<AdditionalCustomerGroup1Text>Tier 3</AdditionalCustomerGroup1Text>
</AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID>T04</AdditionalCustomerGroup1_ID>
<AdditionalCustomerGroup1Text>Tier 4</AdditionalCustomerGroup1Text>
</AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID>T05</AdditionalCustomerGroup1_ID>
<AdditionalCustomerGroup1Text>Tier 5</AdditionalCustomerGroup1Text>
</AdditionalCustomerGroup1>
<AdditionalCustomerGroup1>
<AdditionalCustomerGroup1_ID/>
<AdditionalCustomerGroup1Text/>
</AdditionalCustomerGroup1>
</AdditionalCustomerGroup1>
</multimap:Message2>
</multimap:Messages>XSL Transform
For the sake of brevity, I have included a truncated XSL transform that only includes 3 tables despite my requirement being 10 tables. If you happen to be a savvy XSL veteran, and find my work to be rudimentary, keep in mind that this is my first XSL transform after spending 30 minutes reading and learning on W3Schools. I did implement the XSL transform in such a way that empty string key records would be removed from the stream.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:multimap="http://sap.com/xi/XI/SplitAndMerge">
<xsl:template match="/">
<root>
<StatementName>
<storedProcedureName action="EXECUTE">
<table><xsl:value-of select="multimap:Messages/multimap:Message1/Root/StoredProcedure"/></table>
<ProcedureParameter type="CLOB">
<xsl:text disable-output-escaping="yes"><![CDATA[</xsl:text>
<!-- TVM4T Procedure -->
<xsl:for-each select="multimap:Messages/multimap:Message2/AdditionalMaterialGroup4">
<List>
<xsl:for-each select="AdditionalMaterialGroup4[AdditionalMaterialGroup4_ID!='']">
<Item>
<MaterialGroup4><xsl:value-of select="AdditionalMaterialGroup4_ID"/></MaterialGroup4>
<MaterialGroup4Text><xsl:value-of select="AdditionalMaterialGroup4Text"/></MaterialGroup4Text>
</Item>
</xsl:for-each>
</List>
</xsl:for-each>
<!-- TVM5T Procedure -->
<xsl:for-each select="multimap:Messages/multimap:Message2/AdditionalMaterialGroup5">
<List>
<xsl:for-each select="AdditionalMaterialGroup5[AdditionalMaterialGroup5_ID!='']">
<Item>
<MaterialGroup5><xsl:value-of select="AdditionalMaterialGroup5_ID"/></MaterialGroup5>
<MaterialGroup5Text><xsl:value-of select="AdditionalMaterialGroup5Text"/></MaterialGroup5Text>
</Item>
</xsl:for-each>
</List>
</xsl:for-each>
<!-- TVV1T Procedure -->
<xsl:for-each select="multimap:Messages/multimap:Message2/AdditionalCustomerGroup1">
<List>
<xsl:for-each select="AdditionalCustomerGroup1[AdditionalCustomerGroup1_ID!='']">
<Item>
<CustomerGroup1><xsl:value-of select="AdditionalCustomerGroup1_ID"/></CustomerGroup1>
<CustomerGroup1Text><xsl:value-of select="AdditionalCustomerGroup1Text"/></CustomerGroup1Text>
</Item>
</xsl:for-each>
</List>
</xsl:for-each>
<xsl:text disable-output-escaping="yes">]]></xsl:text>
</ProcedureParameter>
</storedProcedureName>
</StatementName>
</root>
</xsl:template>
</xsl:stylesheet>The resulting XML is JDBC adapter ready
<root xmlns:multimap="http://sap.com/xi/XI/SplitAndMerge">
<StatementName>
<storedProcedureName action="EXECUTE">
<table>sp_TVV1T</table>
<ProcedureParameter type="CLOB">
<![CDATA[
<List>
<Item><CustomerGroup1>T01</CustomerGroup1><CustomerGroup1Text>Tier 1</CustomerGroup1Text></Item>
<Item><CustomerGroup1>T02</CustomerGroup1><CustomerGroup1Text>Tier 2</CustomerGroup1Text></Item>
<Item><CustomerGroup1>T03</CustomerGroup1><CustomerGroup1Text>Tier 3</CustomerGroup1Text></Item>
<Item><CustomerGroup1>T04</CustomerGroup1><CustomerGroup1Text>Tier 4</CustomerGroup1Text></Item>
<Item><CustomerGroup1>T05</CustomerGroup1><CustomerGroup1Text>Tier 5</CustomerGroup1Text></Item>
</List>
]]>
</ProcedureParameter>
</storedProcedureName>
</StatementName>
</root>JDBC
Disclaimer: This part has not actually been tested, but instead the above XML was dumped to an FTP site for extraction during unit testing.
Once the DB admins are able to create the necessary stored procedures I will include an editorial update. In the past, I have used the JDBC adapter in PI/PO where we can do bulk inserts, but I did stumble upon some blog/answer posts, and an OSS note indicating that bulk inserts are not supported in Integration Suite unless using a splitter in batch mode. I referred to the following blog on the topic of using stored procedures, which I had used in the past in PI/PO - Stored procedure as XML Type I opted not to split an already split message, along with the fact that this approach fares far better from a performance perspective.
Conclusion
After reaching a point where I can successfully unit test the full solution outside of of the JDBC handling, I'm pleased with the outcome. For future's sake, if I need to add a new table in the future the process is quite simple:
- Add table to BRF+ expression
- Identify/build an OData service - Note: if you have spent inordinate amounts of time working backward from tables to a usable OData service, then you are not alone, and I would rather reuse than build. I don't need draft capabilities for this type of thing and I'm still presented with choosing from multiple options... whatever happened to software reusability, but that's a topic for another day
- Add four bits of metadata (maybe five if versioning enters the picture) for OData and a stored procedure into the graphical mapping step
- Add a new block to the XSL transform
- Get a DB Admin to create the required stored procedure
Hope folks can get something useful out of this... enjoy!
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
2 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
absl
1 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
AEM
1 -
AI
7 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
4 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
1 -
aws
2 -
Azure
1 -
Azure AI Studio
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
bitcoin
1 -
Blockchain
3 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
11 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
1 -
Business Data Fabric
3 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
1 -
CA
1 -
calculation view
1 -
CAP
3 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
2 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
database tables
1 -
Datasphere
2 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
1 -
Fiori
14 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
Flask
1 -
Full Stack
8 -
Funds Management
1 -
General
1 -
Generative AI
1 -
Getting Started
1 -
GitHub
8 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
5 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
8 -
Kerberos for JAVA
8 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
1 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
2 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-Record Scenarios
1 -
Multiple Event Triggers
1 -
Neo
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
2 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Process Automation
2 -
Product Updates
4 -
PSM
1 -
Public Cloud
1 -
Python
4 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
Research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
3 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
8 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
2 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
20 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
5 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
2 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Odata
2 -
SAP on Azure
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP SuccessFactors
2 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapmentors
1 -
saponaws
2 -
SAPS4HANA
1 -
SAPUI5
4 -
schedule
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
1 -
Technology Updates
1 -
Technology_Updates
1 -
Threats
1 -
Time Collectors
1 -
Time Off
2 -
Tips and tricks
2 -
Tools
1 -
Trainings & Certifications
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
2 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
1 -
Vector Engine
1 -
Visual Studio Code
1 -
VSCode
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- SAP Analytics Cloud - Performance statistics in Technology Blogs by SAP
- Kyma Integration with SAP Cloud Logging. Part 2: Let's ship some traces in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- Capture Your Own Workload Statistics in the ABAP Environment in the Cloud in Technology Blogs by SAP
- Kerberos Error when task "deploy" from db-deployer in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 11 | |
| 10 | |
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |