- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Can data modeling be enhanced by incorporating bus...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-04-2022
10:03 PM
If the answer is yes, then in what extent and how?
In this blog post we will try to answer the question by approaching a real-life scenario. We will discuss the challenges related to high amounts of data and the resulting processing times if the access to that data is not optimally planned and the structure of the data is not designed in a proper way. Finally, we will see how business knowledge about the scenario will provide information about the data modelling, which will boost the performance significantly..
Use Case
In a recent engagement, we worked with a company which decided to install Entry-Exit logging systems, as well as beacons at multiple locations inside its large plant area in order to monitor the entries and exits of the employees, as well as their movements within the plant. All employees were provided with a Bluetooth-equipped bracelet in order to be registered by beacons. Beacons are small, wireless transmitters that use low-energy Bluetooth technology to send signals to other smart devices nearby, bracelets on our scenario. The number of the beacons installed depends on the coverage that each company wants to achieve and the frequency of Beacon transmission is related to the level of detail required for the movement analysis. Details can be seen in the following figure

In addition to simply tracking the employees, the data can be used in further Analytic and Data Science projects, such as
- Working behavior / efficiency of any employee.
- Total working hours.
- Overtime stay within the plant.
- Security constraints.
- Identify all employees which interacted with a Covid diagnosed colleague within the last N day(s).
As a next step, let us review the data model.
Data model in SAP HANA Cloud
For the engagement with the customer, the information described above was used to create a data model in SAP HANA Cloud. The level of detail depends always on our requirements and needs, but in our scenario we will concentrate on information regarding shift period and beacon appearance. Of course, many other entities can be created if needed, such as Beacon, Entry-Exit ones or information from external API's(such as weather, etc.). Moreover, employee information can be imported from any other internal system (e.g., census data like age, married status, years of work) and any organization structure.
In order to keep our scenario as simple as possible, let's assume that all needed information is already populated to two main tables. The first table keeps information regarding the shift period per employee and the second one information regarding the beacon appearance of all employees. A simplified example of the structure of those tables is shown below.
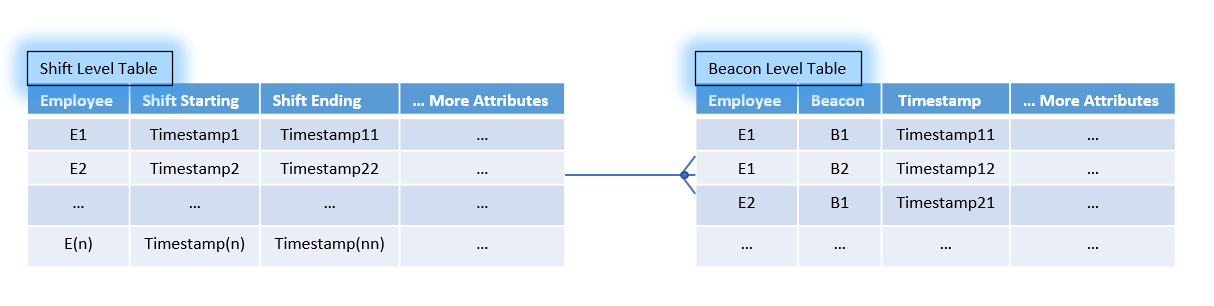
Since we want to use the combined information from both tables, a quick solution is a join between them on Employee level and a selection of all beacon appearances per employee between starting and ending of his/her shift, as shown below :

In the context of as POC, when dealing with small amounts of information, this approach could be accepted. But if we translate this scenario into a productive one with realistic numbers, we will easily realize that this can go really wild. A real-life production scenario could involve the following
- Calculation for more than 10.000 employees. (I)
- Period of observation is at least three months. E.g. 70 working days per employee during this period. (II)
- Average working hours per shift is nine hours. (III)
- Average appearance of Employee on beacon is 60 times per hour (1 appearance per minute, in reality it can even down to seconds). (IV)
So, let's do the math and try to calculate how many records we will require per employee to describe his movement data :
10.000 (I) * 70 (II) * 9 (III) * 60 (IV) = 378 million rows
378 million rows will need to be accessed for every employee, to assign his/her correct Beacon appearance per shift. Even if we still have not realized the performance issue, we will understand it after couple of hours when the query finally finishes. But, what if we bring Business and IT worlds together , taking advantage the SAP HANA partition feature, is it possible to enhance the Physical model and thus accelerate processing?
SAP HANA database provides the partition feature in order really big datasets from a table to be splitted on smallest ones based on one or more column(s).When a user will access the table, through SQL, providing appropriate values for the partitioned column(s), instead of a full table scan taken place, a search on the specific subsets will occur.
In our case, the key words that drive the scenario are "Employee" and "Shift Date". How can we provide this information to our SAP HANA model in order to take advantage of them. What if we use those to partition our table and thus break down the million rows into smaller chunks for further processing. As we can see, "Employee" information is already there but "Shift Date" is missing on both tables. But, we have information regarding shift Starting / Ending as well as all Beacons appearances with corresponding timestamp. So, why not create a derived Date column on both tables from the timestamp ones, as shown in the figure below. To make SAP HANA aware about those two relationships, a two level of partitioning on both tables must take place, first level on Employee and second on the previous derived Date Column.
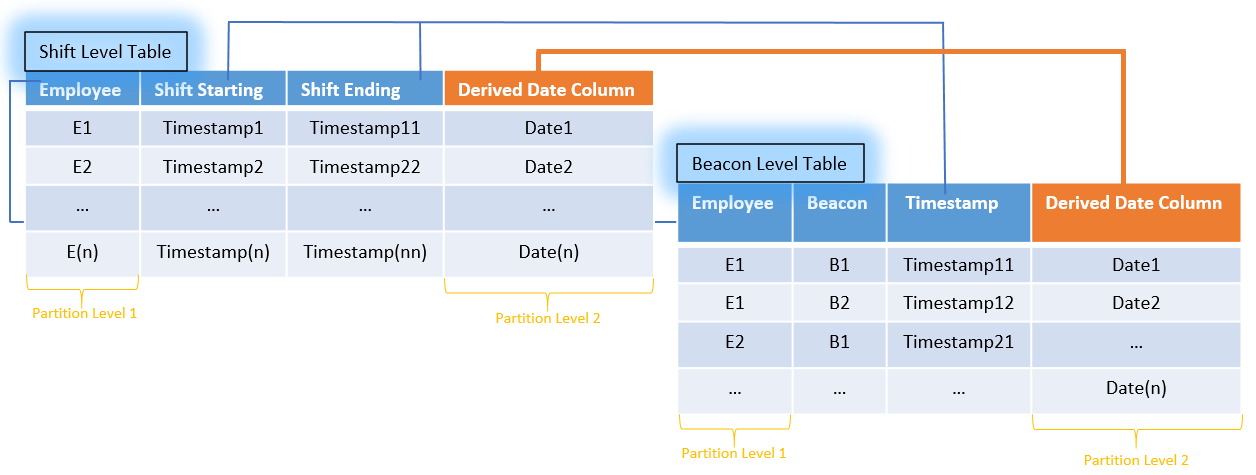
So, let’s do the math again and calculate how many records we will require to search per employee to describe his movement now:
70 (II) * 9 (III) * 60 (IV) = 37.800 rows
This means that per employee we will need to access 37.800 rows for all his/her 70 shifts.
Summary
In a summary, after understanding our business needs and using our knowledge on the use case, we took advantage of SAP HANA partitioning functionality to reduce and limit the searched rows. By doing so , SAP HANA is now checking every time only the needed data an doesn't perform a full table search. This translated in our use case to a gain of 60 times of less CPU and memory needed.
Two important tips to keep in mind:
- Always check the explain plan to verify that a partition oriented plan is taken place, do not rely on theory.
- It is useful to validate the gain on Performance from these two implementations not on execution time, but on SAP HANA metrics (like CPU / Memory).
We have shown in this example how we can reduce time and metrics. But this is not the only gain here. If we look at the bigger picture, we have won in other aspects as well:
- Project-related benefits, which result from the decreased Development time.
- Faster implementation of changes during development cycles.
- More time for testing and UAT concepts.
- Extended capacity planning time-life of Testing / Development environments.
- In production systems, less CPU and Memory do not only translate to a faster execution but also to an increase of the concurrent number of users who are accessing the system without delays, etc..
Please check the following blog for more details on this use case, Connected Workforce
- SAP Managed Tags:
- SAP HANA
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
295 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
341 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
419 -
Workload Fluctuations
1
Related Content
- Start page of SAP Signavio Process Insights, discovery edition, the 4 pillars and documentation in Technology Blogs by SAP
- SAP Signavio is the highest ranked Leader in the SPARK Matrix™ Digital Twin of an Organization (DTO) in Technology Blogs by SAP
- Best Practice: How to Structure the Shared Document Folder in Technology Blogs by SAP
- Introducing Blog Series of SAP Signavio Process Insights, discovery edition – An in-depth exploratio in Technology Blogs by SAP
- Empowering Retail Business with a Seamless Data Migration to SAP S/4HANA in Technology Blogs by Members
Popular Blog Posts
| Subject | Kudos |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Top kudoed authors
| User | Count |
|---|---|
| 35 | |
| 25 | |
| 17 | |
| 13 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |