
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by Members
- Your SAP on Azure – Part 27 – Understand your supp...
Enterprise Resource Planning Blogs by Members
Gain new perspectives and knowledge about enterprise resource planning in blog posts from community members. Share your own comments and ERP insights today!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
BJarkowski
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
01-19-2022
12:46 PM
I see a lot of benefits from using Artificial Intelligence and Machine Learning to optimize your supply chain, improve your forecasting and planning capabilities and learn more about your suppliers and customers. There is a lot of content available on the internet, and within a couple of minutes, you can find records and examples that document the tremendous effect of applying complex algorithms to solve everyday challenges. There are use cases for Machine Learning in every industry – and we witness its impact on our life.
A common challenge that many organizations face is the difficulty to implement machine learning algorithms. They are complex, require specialized knowledge and enough computing resources to drive calculations. As a big enthusiast of Artificial Intelligence, I’m very excited about innovations that come with Cloud Computing. Over the last five years, the way you access and use advanced algorithms has been simplified. Instead of spending weeks training your model, you can deploy a ready-to-use service that can recognize objects on an image or detect anomalies on telemetry data. A couple of months ago, I published a blog post on how you can use such a service to automate invoice processing in SAP. I used the AI-Powered Azure Form Recognizer to transform a scanned invoice into a JSON file containing business-relevant information, which I could further process and import to the ERP system. hobruche, on his fantastic YouTube channel, also shows a couple of exciting scenarios of working with AI technologies. For example, he built a solution that improves user experience when looking for support information. We all suffered in the past when trying to identify the exact model of the notebook, just to get a troubleshooting document or update drivers. In Holger’s demo, you can see how to incorporate machine learning to simplify the process by using computer vision to identify the hardware automatically, based on the photo taken with a smartphone. Using Artificial Intelligence is a great way to simplify and automate repetitive tasks that allow us to focus on essential things.
Today I would like to show you a slightly more complex scenario. We will build and train a machine learning model. That was always a big challenge for me, as I'm not a professional developer, and despite the fact I can write basic code, I was always intimidated by the complex algorithms I'd have to use. The last time I touched on the topic of statistics was probably over ten years ago when I was a student, which doesn't help. So I look forward to seeing what innovations are available for me and if I can onboard the machine learning process to identify strategic suppliers using low-code development? The idea came to my mind after reading an excellent blog post written by puneet.sikarwar, he provides step-by-step guidance on performing supplier clustering. You can then use the results to further classify and evaluate the most critical ones for your business. After reading the article, I immediately thought it was an excellent use case, and I wondered if I could get a similar result.
The main requirement was to limit writing code as much as possible. Initially, I played around with PowerBI capabilities that let you cluster data with a click of a button. It worked well, but I wanted to have more control of the process. I thought it is an excellent opportunity to explore the Azure Machine Learning service, which lets you rapidly build and train models using a low-code approach.
ALGORITHM
You can classify machine learning algorithms into the following groups:
Before you start thinking about which machine learning algorithm to use, you should classify the problem into one of the above categories. Supplier clustering, which I discuss today, is part of Unsupervised Learning as we want the algorithm to discover similarities autonomously. I follow Puneet's recommendation, and I use the following KPIs to group suppliers:
There are so many algorithms available that finding the right one may seem difficult. To simplify the process, Microsoft prepared an easy to understand Cheat Sheet which you can use:
Before we start designing the AI model, we have to prepare data.
DATA
One thing that is always very important when you work with machine learning is data quality. Using the best algorithms and the most powerful computing won’t give you reliable results if you have poor data. Imagine that your supplier is defined more than once in your SAP system. That’s not an uncommon scenario, and I saw it many times. In such a case, all transactions with this business partner are distributed across three entities, and as a result, the classification may be incorrect. I saw many terrifying examples where making data-driven decisions was impossible due to poor data quality. Before starting with machine learning, you must ensure your data represents reality accurately. Otherwise, it won’t solve your problems. Moreover, it can give you false insights.
I start with extracting purchase orders information from my SAP IDES system to get my dataset. It’s not an ideal data source as it has a limited amount of suppliers, but it should be enough for this proof of concept. Puneet, in his blog, uses invoices, but I think purchase orders can give me equally good results. They are stored in two tables: EKKO containing header information that I’ll use to get supplier id’s and document dates, and EKPO containing line items to calculate the value of transactions. I use Synapse Pipelines to extract data to Azure Data Lake and perform necessary calculations. Once I have the data, I use the following query to list all information to calculate suppliers KPIs:
Having a quick look at the dataset confirms my worries that I have some data quality issues that I need to sort out before training my machine learning model. The total value equals zero for some purchase orders, which means no items were delivered. I decided to exclude them when calculating my KPIs. For some other purchase orders there was no supplier assigned – and I’ll add an extra step in my AI pipeline to fix that for me.
I use the following three select statements to calculate Recency, Frequency and Monetary KPIs:
I save the results of each query as an external table. Then I join them to have all KPIs available in a single dataset.
The above table, containing Recency, Frequency and Monetary KPIs, is my source table that I’ll use to train my model.
AZURE MACHINE LEARNING
Creating the Azure Machine Learning workspace is a straightforward process, and the wizard guide you through the deployment process. There are a couple of dependencies on other resources like Storage Account or Key Vault, but Azure deploys them automatically during workspace provisioning.
You can directly jump to the Review and Create section to confirm the deployment unless you want to configure advanced network settings like a private endpoint. Once it’s completed, you can navigate to the workspace and immediately start designing the workflow.
When you see the welcome page for the first time, you may feel a bit lost and overwhelmed. Don't worry too much about it. I will guide you on everything you should do to design and run your experiment. But I also strongly suggest taking some time to finish the Microsoft Learning course that talks about Azure Machine Learning.
Microsoft Azure AI Fundamentals: Explore visual tools for machine learning - Learn | Microsoft Docs
In addition, you can check out the rich library of sample scenarios:
After opening the workspace, we should firstly focus on referencing our dataset to the Machine Learning service. There are two ways to do it. You can download the table containing KPIs to your local computer and then upload it to the workspace. But as I highly appreciate how all Azure services are seamlessly integrated, I want to connect to the external table defined in Synapse directly. This way, if there is ever an update to my source dataset, the Machine Learning model will always use the latest data without any further action.
From the left menu of the AI workspace, choose Datasets, then New Dataset -> From Datastore.
In the first step provide the name of the dataset and choose Tabular as the type.
In the Datastore Selection step, you have to reference the Storage Account where your dataset exists. As external tables in Synapse are basically parquet files, I choose Azure Blob Storage and provide connection details.
Then, provide the path to the source dataset:
In the third step you have the opportunity to look at the content of the datasets:
And then influence the data schema. In my case all types were automatically discovered and I didn’t have to make any changes.
Executing machine learning processes requires computing power. I decided to use a small virtual machine with four cores and 14GB of memory. My algorithm isn’t too complex, and I also don’t have many data records, so I can deploy a single virtual machine to perform all tasks.
Choose Compute from the left menu and then New.
I don’t make any changes in the Advanced Settings. Click Create to start the deployment, which takes a couple of minutes. You don’t have to wait until it’s ready. You can begin designing the first workflow.
WORKFLOW
Do you remember what I said about being a bit lost when seeing the Machine Learning workspace for the first time? The feeling is even stronger when you start the designer. There are over ninety predefined actions that you can choose from and then organize in the correct order. I again recommend checking out the learning content I shared before. After you go through provided examples, everything starts to be clear (and almost intuitive!).
The source dataset is the first building block that you have to place in the workflow. It references the data that the algorithm uses during the execution. Then I add Clean Missing Data step to remove the record with an empty Supplier ID. In the Cleaning Mode, you can decide what to do with missing values – for numeric columns, you could choose to replace it with a Mean or Median, but as this won't work for Supplier ID, I decided to delete the entire row.
I use part of the data from the SupplierKPI table to train the model. The Split Data action allows me to create a randomized sample of suppliers.
It’s time to choose the algorithm. For clustering, the only available one is the K-Means one. Please select it from the Machine Learning Algorithms section and place it on the diagram. You can choose the desired number of clusters in the Number of Centroids field in the advanced settings. Next, place the Train Model action. It accepts two inputs: the chosen algorithm and the data source to use. Connect building block as on the image below:
In the Train Model settings, provide the list of columns that the model should use to calculate clusters. It's crucial to select only Recency, Frequency and Monetary fields. You should not choose the Supplier ID as it's not the KPI.
The last two missing elements are Assign Data to Clusters which applies the model to the subset of data, and then Evaluate Model to verify the results. You don't have to maintain any additional settings. My entire workflow looks as follows:
Once the workflow is ready, we can start the processing. Click the big Submit button – and create an Experiment to groups jobs.
Confirm by clicking the Submit button again. Take a break. It will take a couple of minutes to complete all steps.
EVALUATION
For every completed action, you can display processing results and detailed logs. For example, how the dataset looks like after cleaning missing values:
Similarly, you can see the Supplier and cluster allocation. Open the Result Data set of the Assign Data to Cluster action.
Raw data is great, but I think I can get a better picture by opening the results dataset in PowerBI. I use the Scatter Chart to visualise allocations.
You can clearly see how the allocation works. The first group of suppliers, marked in light blue colour, represents suppliers with a high frequency of orders. Suppliers marked in a darker shade of blue are the most recent ones. These two groups are probably the most interesting ones to focus on during further evaluation. The third cluster forms suppliers that I haven't traded with for a long time, and we could probably ignore them in further processing.
I'm pleased with my results, and I hope you enjoyed today's episode of the Your SAP on Azure blog series. Creating the AI Model required some additional learning, but overall it was pretty straightforward. I want to expand my skills in the AI area, and soon you can expect more articles on how to use it with SAP data.
A common challenge that many organizations face is the difficulty to implement machine learning algorithms. They are complex, require specialized knowledge and enough computing resources to drive calculations. As a big enthusiast of Artificial Intelligence, I’m very excited about innovations that come with Cloud Computing. Over the last five years, the way you access and use advanced algorithms has been simplified. Instead of spending weeks training your model, you can deploy a ready-to-use service that can recognize objects on an image or detect anomalies on telemetry data. A couple of months ago, I published a blog post on how you can use such a service to automate invoice processing in SAP. I used the AI-Powered Azure Form Recognizer to transform a scanned invoice into a JSON file containing business-relevant information, which I could further process and import to the ERP system. hobruche, on his fantastic YouTube channel, also shows a couple of exciting scenarios of working with AI technologies. For example, he built a solution that improves user experience when looking for support information. We all suffered in the past when trying to identify the exact model of the notebook, just to get a troubleshooting document or update drivers. In Holger’s demo, you can see how to incorporate machine learning to simplify the process by using computer vision to identify the hardware automatically, based on the photo taken with a smartphone. Using Artificial Intelligence is a great way to simplify and automate repetitive tasks that allow us to focus on essential things.
Today I would like to show you a slightly more complex scenario. We will build and train a machine learning model. That was always a big challenge for me, as I'm not a professional developer, and despite the fact I can write basic code, I was always intimidated by the complex algorithms I'd have to use. The last time I touched on the topic of statistics was probably over ten years ago when I was a student, which doesn't help. So I look forward to seeing what innovations are available for me and if I can onboard the machine learning process to identify strategic suppliers using low-code development? The idea came to my mind after reading an excellent blog post written by puneet.sikarwar, he provides step-by-step guidance on performing supplier clustering. You can then use the results to further classify and evaluate the most critical ones for your business. After reading the article, I immediately thought it was an excellent use case, and I wondered if I could get a similar result.
The main requirement was to limit writing code as much as possible. Initially, I played around with PowerBI capabilities that let you cluster data with a click of a button. It worked well, but I wanted to have more control of the process. I thought it is an excellent opportunity to explore the Azure Machine Learning service, which lets you rapidly build and train models using a low-code approach.
ALGORITHM
You can classify machine learning algorithms into the following groups:
- Supervised learning – where you teach the model how to recognize patterns (for example, objects on images)
- Unsupervised learning – where the model discover patterns on its own (for example, to group data points based on similarity)
- Reinforcement learning – where the model learns to react to the environment (for example, in autonomously driving a car)
Before you start thinking about which machine learning algorithm to use, you should classify the problem into one of the above categories. Supplier clustering, which I discuss today, is part of Unsupervised Learning as we want the algorithm to discover similarities autonomously. I follow Puneet's recommendation, and I use the following KPIs to group suppliers:
- Recency - How recently I did business with a supplier
- Frequency - How often do I do business with a supplier
- Monetary - What is the value of transactions I did with a supplier
There are so many algorithms available that finding the right one may seem difficult. To simplify the process, Microsoft prepared an easy to understand Cheat Sheet which you can use:

(source: Microsoft.com)
Before we start designing the AI model, we have to prepare data.
DATA
One thing that is always very important when you work with machine learning is data quality. Using the best algorithms and the most powerful computing won’t give you reliable results if you have poor data. Imagine that your supplier is defined more than once in your SAP system. That’s not an uncommon scenario, and I saw it many times. In such a case, all transactions with this business partner are distributed across three entities, and as a result, the classification may be incorrect. I saw many terrifying examples where making data-driven decisions was impossible due to poor data quality. Before starting with machine learning, you must ensure your data represents reality accurately. Otherwise, it won’t solve your problems. Moreover, it can give you false insights.
I start with extracting purchase orders information from my SAP IDES system to get my dataset. It’s not an ideal data source as it has a limited amount of suppliers, but it should be enough for this proof of concept. Puneet, in his blog, uses invoices, but I think purchase orders can give me equally good results. They are stored in two tables: EKKO containing header information that I’ll use to get supplier id’s and document dates, and EKPO containing line items to calculate the value of transactions. I use Synapse Pipelines to extract data to Azure Data Lake and perform necessary calculations. Once I have the data, I use the following query to list all information to calculate suppliers KPIs:
WITH [EKKO] AS
(
SELECT
*
FROM
OPENROWSET(
BULK 'https://<datalake>.dfs.core.windows.net/data/raw/EKKO/EKKO.parquet',
FORMAT = 'PARQUET'
) AS [result]
),
[EKPO] AS
(
SELECT
*
FROM
OPENROWSET(
BULK 'https://<datalake>.dfs.core.windows.net/data/raw/EKPO/EKPO.parquet',
FORMAT = 'PARQUET'
) AS [result]
)
SELECT
EKKO.EBELN AS 'DocumentID',
EKPO.IDNLF AS 'SupplierMaterialNumber',
EKPO.NETWR AS 'NetValueInDocumentCurrency',
EKKO.LIFNR AS 'SupplierID' ,
EKKO.BEDAT AS 'DocumentDate',
EKKO.WAERS AS 'DocumentCurrency'
FROM EKKO
INNER JOIN EKPO ON EKKO.EBELN = EKPO.EBELN
Having a quick look at the dataset confirms my worries that I have some data quality issues that I need to sort out before training my machine learning model. The total value equals zero for some purchase orders, which means no items were delivered. I decided to exclude them when calculating my KPIs. For some other purchase orders there was no supplier assigned – and I’ll add an extra step in my AI pipeline to fix that for me.
I use the following three select statements to calculate Recency, Frequency and Monetary KPIs:
- Recency
SELECT SupplierID, MIN(DATEDIFF(day, DocumentDate, GETDATE())) as Recency
from supplierOverviewClean
GROUP BY SupplierID

- Frequency
SELECT SupplierID, COUNT(DISTINCT DocumentID) as Frequency
from supplierOverviewClean
GROUP BY SupplierID

- Monetary
SELECT SupplierID, SUM(NetValue) as Monetary
from supplierOverviewClean
GROUP BY SupplierID

I save the results of each query as an external table. Then I join them to have all KPIs available in a single dataset.

The above table, containing Recency, Frequency and Monetary KPIs, is my source table that I’ll use to train my model.
AZURE MACHINE LEARNING
Creating the Azure Machine Learning workspace is a straightforward process, and the wizard guide you through the deployment process. There are a couple of dependencies on other resources like Storage Account or Key Vault, but Azure deploys them automatically during workspace provisioning.
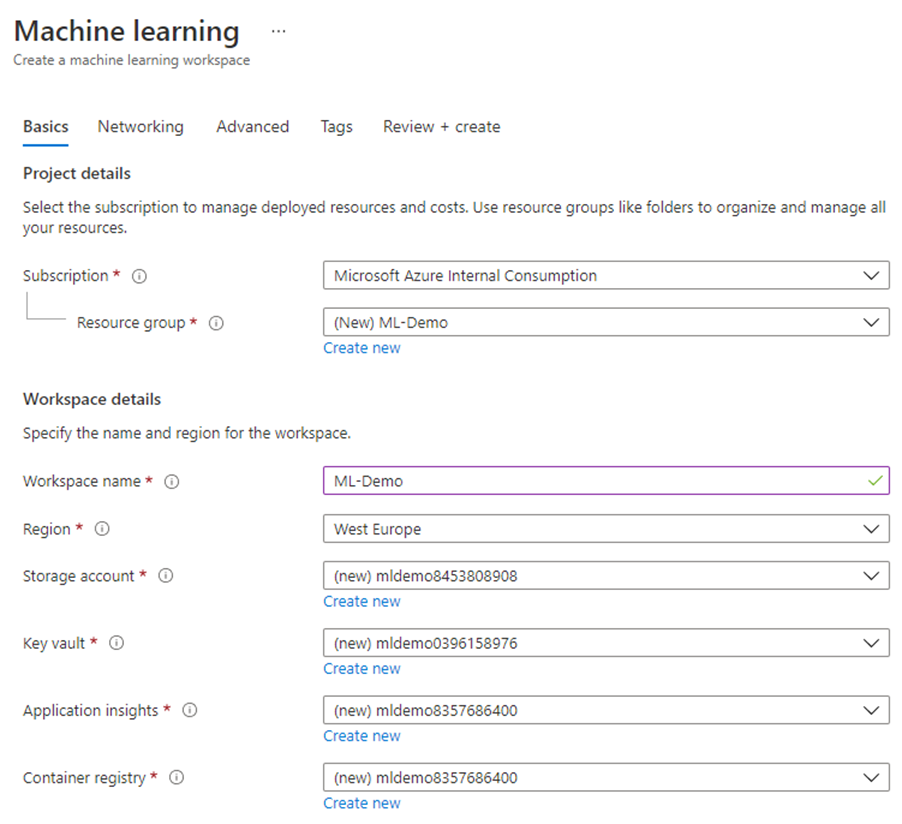
You can directly jump to the Review and Create section to confirm the deployment unless you want to configure advanced network settings like a private endpoint. Once it’s completed, you can navigate to the workspace and immediately start designing the workflow.

When you see the welcome page for the first time, you may feel a bit lost and overwhelmed. Don't worry too much about it. I will guide you on everything you should do to design and run your experiment. But I also strongly suggest taking some time to finish the Microsoft Learning course that talks about Azure Machine Learning.
Microsoft Azure AI Fundamentals: Explore visual tools for machine learning - Learn | Microsoft Docs
In addition, you can check out the rich library of sample scenarios:

After opening the workspace, we should firstly focus on referencing our dataset to the Machine Learning service. There are two ways to do it. You can download the table containing KPIs to your local computer and then upload it to the workspace. But as I highly appreciate how all Azure services are seamlessly integrated, I want to connect to the external table defined in Synapse directly. This way, if there is ever an update to my source dataset, the Machine Learning model will always use the latest data without any further action.
From the left menu of the AI workspace, choose Datasets, then New Dataset -> From Datastore.

In the first step provide the name of the dataset and choose Tabular as the type.

In the Datastore Selection step, you have to reference the Storage Account where your dataset exists. As external tables in Synapse are basically parquet files, I choose Azure Blob Storage and provide connection details.

Then, provide the path to the source dataset:

In the third step you have the opportunity to look at the content of the datasets:

And then influence the data schema. In my case all types were automatically discovered and I didn’t have to make any changes.

Executing machine learning processes requires computing power. I decided to use a small virtual machine with four cores and 14GB of memory. My algorithm isn’t too complex, and I also don’t have many data records, so I can deploy a single virtual machine to perform all tasks.
Choose Compute from the left menu and then New.
I don’t make any changes in the Advanced Settings. Click Create to start the deployment, which takes a couple of minutes. You don’t have to wait until it’s ready. You can begin designing the first workflow.
WORKFLOW
Do you remember what I said about being a bit lost when seeing the Machine Learning workspace for the first time? The feeling is even stronger when you start the designer. There are over ninety predefined actions that you can choose from and then organize in the correct order. I again recommend checking out the learning content I shared before. After you go through provided examples, everything starts to be clear (and almost intuitive!).
The source dataset is the first building block that you have to place in the workflow. It references the data that the algorithm uses during the execution. Then I add Clean Missing Data step to remove the record with an empty Supplier ID. In the Cleaning Mode, you can decide what to do with missing values – for numeric columns, you could choose to replace it with a Mean or Median, but as this won't work for Supplier ID, I decided to delete the entire row.

I use part of the data from the SupplierKPI table to train the model. The Split Data action allows me to create a randomized sample of suppliers.

It’s time to choose the algorithm. For clustering, the only available one is the K-Means one. Please select it from the Machine Learning Algorithms section and place it on the diagram. You can choose the desired number of clusters in the Number of Centroids field in the advanced settings. Next, place the Train Model action. It accepts two inputs: the chosen algorithm and the data source to use. Connect building block as on the image below:

In the Train Model settings, provide the list of columns that the model should use to calculate clusters. It's crucial to select only Recency, Frequency and Monetary fields. You should not choose the Supplier ID as it's not the KPI.

The last two missing elements are Assign Data to Clusters which applies the model to the subset of data, and then Evaluate Model to verify the results. You don't have to maintain any additional settings. My entire workflow looks as follows:

Once the workflow is ready, we can start the processing. Click the big Submit button – and create an Experiment to groups jobs.

Confirm by clicking the Submit button again. Take a break. It will take a couple of minutes to complete all steps.
EVALUATION
For every completed action, you can display processing results and detailed logs. For example, how the dataset looks like after cleaning missing values:

Similarly, you can see the Supplier and cluster allocation. Open the Result Data set of the Assign Data to Cluster action.

Raw data is great, but I think I can get a better picture by opening the results dataset in PowerBI. I use the Scatter Chart to visualise allocations.

You can clearly see how the allocation works. The first group of suppliers, marked in light blue colour, represents suppliers with a high frequency of orders. Suppliers marked in a darker shade of blue are the most recent ones. These two groups are probably the most interesting ones to focus on during further evaluation. The third cluster forms suppliers that I haven't traded with for a long time, and we could probably ignore them in further processing.
I'm pleased with my results, and I hope you enjoyed today's episode of the Your SAP on Azure blog series. Creating the AI Model required some additional learning, but overall it was pretty straightforward. I want to expand my skills in the AI area, and soon you can expect more articles on how to use it with SAP data.
- SAP Managed Tags:
- Machine Learning,
- Artificial Intelligence,
- SAP ERP,
- SAP S/4HANA
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"mm02"
1 -
A_PurchaseOrderItem additional fields
1 -
ABAP
1 -
ABAP Extensibility
1 -
ACCOSTRATE
1 -
ACDOCP
1 -
Adding your country in SPRO - Project Administration
1 -
Advance Return Management
1 -
AI and RPA in SAP Upgrades
1 -
Approval Workflows
1 -
ARM
1 -
ASN
1 -
Asset Management
1 -
Associations in CDS Views
1 -
auditlog
1 -
Authorization
1 -
Availability date
1 -
Azure Center for SAP Solutions
1 -
AzureSentinel
2 -
Bank
1 -
BAPI_SALESORDER_CREATEFROMDAT2
1 -
BRF+
1 -
BRFPLUS
1 -
Bundled Cloud Services
1 -
business participation
1 -
Business Processes
1 -
CAPM
1 -
Carbon
1 -
Cental Finance
1 -
CFIN
1 -
CFIN Document Splitting
1 -
Cloud ALM
1 -
Cloud Integration
1 -
condition contract management
1 -
Connection - The default connection string cannot be used.
1 -
Custom Table Creation
1 -
Customer Screen in Production Order
1 -
Data Quality Management
1 -
Date required
1 -
Decisions
1 -
desafios4hana
1 -
Developing with SAP Integration Suite
1 -
Direct Outbound Delivery
1 -
DMOVE2S4
1 -
EAM
1 -
EDI
2 -
EDI 850
1 -
EDI 856
1 -
edocument
1 -
EHS Product Structure
1 -
Emergency Access Management
1 -
Energy
1 -
EPC
1 -
Financial Operations
1 -
Find
1 -
FINSSKF
1 -
Fiori
1 -
Flexible Workflow
1 -
Gas
1 -
Gen AI enabled SAP Upgrades
1 -
General
1 -
generate_xlsx_file
1 -
Getting Started
1 -
HomogeneousDMO
1 -
IDOC
2 -
Integration
1 -
Learning Content
2 -
LogicApps
2 -
low touchproject
1 -
Maintenance
1 -
management
1 -
Material creation
1 -
Material Management
1 -
MD04
1 -
MD61
1 -
methodology
1 -
Microsoft
2 -
MicrosoftSentinel
2 -
Migration
1 -
MRP
1 -
MS Teams
2 -
MT940
1 -
Newcomer
1 -
Notifications
1 -
Oil
1 -
open connectors
1 -
Order Change Log
1 -
ORDERS
2 -
OSS Note 390635
1 -
outbound delivery
1 -
outsourcing
1 -
PCE
1 -
Permit to Work
1 -
PIR Consumption Mode
1 -
PIR's
1 -
PIRs
1 -
PIRs Consumption
1 -
PIRs Reduction
1 -
Plan Independent Requirement
1 -
Premium Plus
1 -
pricing
1 -
Primavera P6
1 -
Process Excellence
1 -
Process Management
1 -
Process Order Change Log
1 -
Process purchase requisitions
1 -
Product Information
1 -
Production Order Change Log
1 -
Purchase requisition
1 -
Purchasing Lead Time
1 -
Redwood for SAP Job execution Setup
1 -
RISE with SAP
1 -
RisewithSAP
1 -
Rizing
1 -
S4 Cost Center Planning
1 -
S4 HANA
1 -
S4HANA
3 -
Sales and Distribution
1 -
Sales Commission
1 -
sales order
1 -
SAP
2 -
SAP Best Practices
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Cloud ALM
1 -
SAP Data Quality Management
1 -
SAP Maintenance resource scheduling
2 -
SAP Note 390635
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud private edition
1 -
SAP Upgrade Automation
1 -
SAP WCM
1 -
SAP Work Clearance Management
1 -
Schedule Agreement
1 -
SDM
1 -
security
2 -
Settlement Management
1 -
soar
2 -
SSIS
1 -
SU01
1 -
SUM2.0SP17
1 -
SUMDMO
1 -
Teams
2 -
User Administration
1 -
User Participation
1 -
Utilities
1 -
va01
1 -
vendor
1 -
vl01n
1 -
vl02n
1 -
WCM
1 -
X12 850
1 -
xlsx_file_abap
1 -
YTD|MTD|QTD in CDs views using Date Function
1
- « Previous
- Next »
Related Content
- Manage Supply Shortage and Excess Supply with MRP Material Coverage Apps in Enterprise Resource Planning Blogs by SAP
- The Role of SAP Business AI in the Chemical Industry. Overview in Enterprise Resource Planning Blogs by SAP
- SAP S/4HANA Structure for Developer in Enterprise Resource Planning Q&A
- Futuristic Aerospace or Defense BTP Data Mesh Layer using Collibra, Next Labs ABAC/DAM, IAG and GRC in Enterprise Resource Planning Blogs by Members
- SAP S/4HANA Cloud Extensions with SAP Build Best Practices: An Expert Roundtable in Enterprise Resource Planning Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 6 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |