Introduction
PaPM is a versatile application. Unlike many traditional SAP modules (like FICO) which runs based on configuration, PaPM works like building blocks. We can build the solution/environment in our own way for variety of business requirements and scenarios.
While designing an environment in PaPM, our focus will be on getting results as per business requirement. However, we should also consider certain design aspects which impacts performance, memory usage, flexibility, and maintenance.
In my experience of implementing PaPM, I have learnt certain practices/tips which have positively impacted on performance and memory usage. In this blog, will try to bring out such practices/tips which can help build an efficient environment in PaPM.
Practices/Tips
Tip 1: Consider fields which are required
In Function Types Model View or Model Table, when referred to a view or table, include only those fields which are relevant for further processing. We can exclude the non-relevant by ticking the Exclude option as below.

This will drastically reduce memory used by non-relevant fields/columns and improves performance.
Note: Do not exclude field Client. Otherwise, data from all the clients will be considered.
Tip 2: Filter data at the very beginning
Before we start processing of the external/huge data, filter the relevant data (within the relevant fields) at the earliest possible using Selection Condition.
For instance, in a Join Function referring to the Model View or Model Table, apply filter (on fields like ledger) in the Input Section to consider only the relevant data for further processing as below.
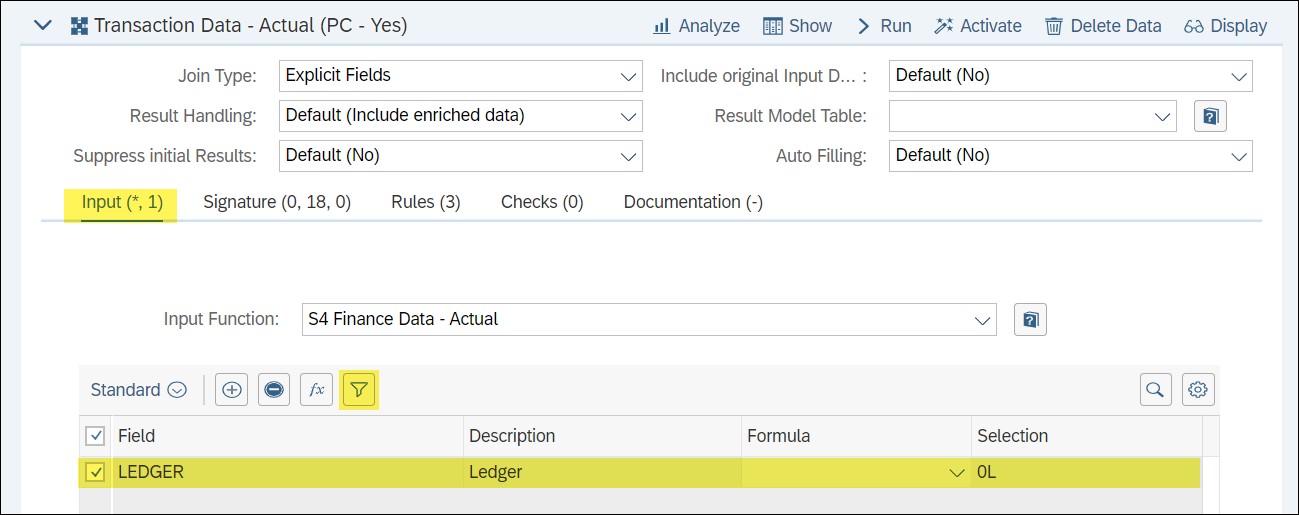 This will drastically reduce the data (lines) to be processed and has positive impact on performance and memory.
This will drastically reduce the data (lines) to be processed and has positive impact on performance and memory.
Tip 3: Using Parameters in Selection Condition
In continuation to the earlier tip, we can also parameters to further filter down the relevant data. Parameters are like user variables which will be provided by the user while deploying the Processes in Fiori App: Processes – Manage & Deploy.
Let’s take an example of monthly cost allocation run. Here a particular period data is only relevant. The user will maintain parameter information like period while deploying the Processes. We can use the same in function.
We can’t directly use parameters in the Selection Condition, instead we use Complex Selection as below.
 In the above complex selection, P_YEAR and P_PERIOD are the Parameters. This will help filter data relevant to the Fiscal Year and Fiscal Period for which cost allocation is executed. (In certain cases, parameters must be maintained preceded with a colon “:P_YEAR”).
In the above complex selection, P_YEAR and P_PERIOD are the Parameters. This will help filter data relevant to the Fiscal Year and Fiscal Period for which cost allocation is executed. (In certain cases, parameters must be maintained preceded with a colon “:P_YEAR”).
Using parameter will make sure we effectively process data which is required and don’t overrun on memory.
Tip 4: Combine and reduce the number of functions
Each function when executed stores result in an underlying table. More the functions, more are the underlying tables consuming memory. So, take care to avoid unnecessary functions and try to merge in a single function.

For instance, in case we have to a use join function to select transactions relating to a group of cost elements (GLs) and cost centres. Instead of creating 2 different functions, first to join cost elements and then to join cost centres, use one single function with multiple rules as below.
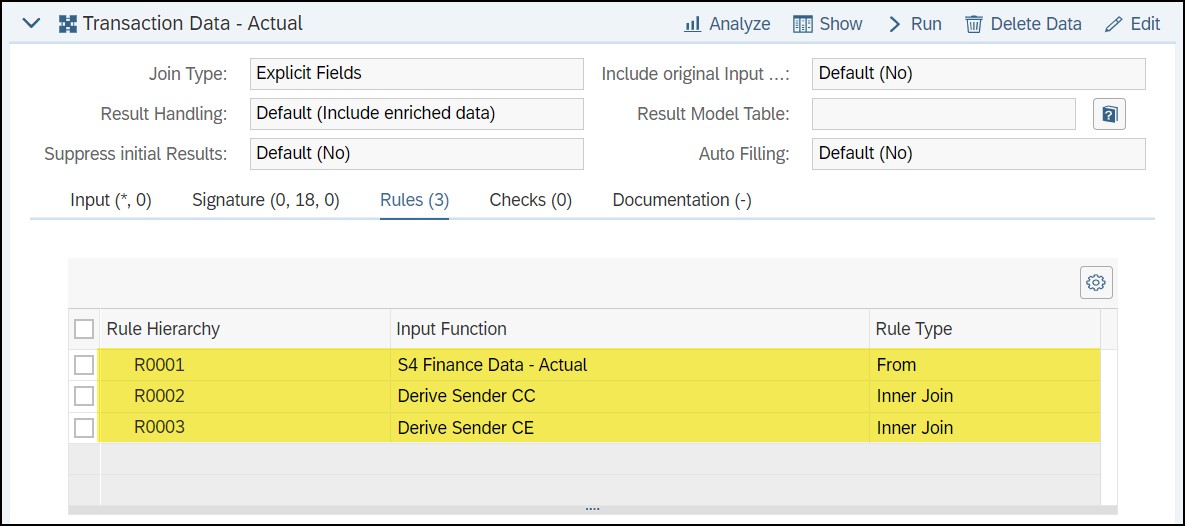
Tip 5: Using Parameter in File Adapter
Using of a Parameter in the File Adapter function gives flexibility and reusability of the function. Please refer to the detail
blog on the same.
Tip 6: Using Environment CDS in Query Function
When we define Query function report as one of the user activities in a Process, the results shown to the users in the report are not limited to the RUN ID but all the entries in the underlying table.
This surprisingly not only gives access of the resulted data to unrelated and unauthorized parties, but also eats upon processing and loading of all the data into the report. Ideally only the relevant data for the Run ID would be appreciated.
Though we can’t do anything on unauthorized access, there is a workaround to restrict (manually) loading of the data relevant to the RUN ID, thus reducing the processing and loading time of the report.
In Query Function, use Environment CDS option in Query Source. Then in Fixed Values add the fields which we ask user to provide input before showing results in the report. For instance, RUN ID or any other field available. We should also take care that other attributes (Variable Represents and Variable is) are set correctly as in the below image.

With the above, reports when launched (Fiori App: My Activities) will ask for mandatory input from the user. This will help restricting the reports from loading full data from the underlying table.

Note: Using ‘Environment’ option only supports standard fields to filter the data.
Tip 7: Getting RUN ID as a column
In the earlier tip, it is suggested to use RUN ID field to restrict data manually. However, we should note that the technical RUN ID field (FS_PER_RUN_ID_) generated by the system is not accessible in the Query Function.
As a solution, create an Environment Field which represents RUN ID. Fill this field with RUN ID by using the below formula in the immediate input function called by the Query Function.

Tip 8: Setting functions as Executable
Keep only those functions executable which are either part of Process Template or input to a query function, to avoid unwanted memory consumption.
SAP Note
Below SAP Note is a must read.
2967291 - FS-PER 3.0: Performance related Modeling Best Practices
Conclusion
Hope you will find this blog and practices/tips helpful.
There will be lot many such practices/tips in your experience, please do add in the comments.
