





- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Intelligence – What’s New in 3.2
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-19-2021
10:36 PM
SAP Data Intelligence 3.2, on-premise edition is now available.
Within this blog post, you will find updates on the latest enhancements in 3.2. We want to share and describe the new functions and features of SAP Data Intelligence for the Q4 2021 release.
If you would like to review what was made available in the previous release, please have a look at this blog post.
This section will give you only a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
This topic area focuses mainly on all kinds of connection and integration capabilities which are used across the product – for example in the Metadata Explorer or on operator level in the Pipeline Modeler.
Configure TLS encryption for Oracle and SAP IQ connections in Connection Management application.
Flowagent based Structured File Consumer supports consumption of valid JSON files with JSON or JSONL extension.
Configure the Structured File Consumer operator using the new form-based editor. The custom editor lets you to define the projection of columns, apply filters, and preview data.

In the Data Intelligence Modeler under the category 'Structured Data Operators', the Table Consumer and SQL Consumer operators now provide configurations to support partitioning across data boundaries, allowing loading in parallel to increase performance. For all sources, users can define a logical partition by filtering. For Oracle sources they can define row ID and physical partitions in the Table consumer operator.

Users may now create connections of type HDL_DB which allows connection to SAP HANA Data Lake, to be used in conjunction with the following structured operators in pipelines: Structured Table Consumer, Structured Table Producer, Structured Data Transform, Structured SQL Consumer, and Flowagent SQL Executor.

Ability to run Data Quality Validation rules on SAP HANA calculation views with parameters to determine the quality of the data.
Introduction of a new connection type that allows to connect to HANA Data Lake Files. It is possible to:
Connections using ABAP_LEGACY connection type now support load balancing.
New connection type for Snowflake that can be browsed from within Metadata Explorer and provide new Data Pipeline Operators for reading data and executing statements.
Graph templates in form of snippets that can be used to replicate data from ABAP-based systems into a data lake based on object store or Kafka.
Support SNC encryption for connection type ABAP via RFC protocol for ABAP-based on-premise systems.
In case of questions regarding the connection, “created by” will be the go-to person.
Please note that this functionality is depending on the connected ABAP system and not directly included in DI 2110 as a feature. You can check SAP note 3105880 for more details.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
Introduction of new operators with unified table type and efficient recovery support to implement core integration scenarios
Operators are available as a new ”Generation 2” category and do not interfere with existing graphs and operators
In this topic area you will find all features dealing with discovering metadata, working with it and also data preparation functionalities. Sometimes you will also find information about newly supported systems.
APIs have been added to Metadata Explorer that allow to import tag and tag hierarchies from external metadata catalog and data governance systems. This enables the enrichment of metadata with auto classifications, correlations, and suggestions stemming from outside systems.
The Metadata Rules advanced condition script editor now allows functions is_unique and is_data_dependent to be used in rule condition scripts. Information Steward rules containing functions is_unique and is_data_dependent can be imported to Metadata Explorer and added to rulebooks for execution.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
with necessary enforcement of governance with necessary roles.
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
BUSINESS VALUE – BENEFITS:
Note: * and ** new with SAP Data Intelligence 3.2
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
USE CASE DESCRIPTION:
BUSINESS VALUE – BENEFITS:
This topic area covers new operators or enhancements of existing operators. Improvements or new functionalities of the Pipeline Modeler and the development of pipelines.
Operators such as the ABAP readers have dynamic attributes that could not be handled by snippets for now. With the new version, these attributes are supported to build domain-specific snippets.
The ”Data Transform” operator now allows to model cases in the ETL process.
The Structured Table Consumer operator UI has been enhanced to support additional features such as projection and filtering, input parameters, variables, and value help for calculation views, as well as preview of the adapted data set. Also, the Table and File Producers have an improved UI to select columns.
Compression support for Kafka Producer operator.
The trace tab is now moved to graph specific runtime view. You can do an initial troubleshoot of running graphs in the Pipeline Modeler UI. You can view the trace records based on selected GROUP and TRACE LEVEL settings. Modify the group and trace level settings anytime and fetch recent K8s pod logs. You can also perform a search through the trace records on text editor.
The Table Replicator operator offers a configuration option to produce compressed Parquet or Orc files in the target.
Using 'append' write mode with the Structured Table Producer operator will surface a new property 'upsert' which allows the user to specify that the pipeline should overwrite records in the target based on the table primary key.
This topic area includes all improvements, updates and way forward for Machine Learning in SAP Data Intelligence.
There are new operators available that represent pre-trained ML services:
This topic area includes all services that are provided by the system – like administration, user management or system management.
Allow tenant administrators to monitor the pipelines of all users.
When importing solutions to the User Workspace the meta data gets persisted and can be re-used when exporting to the filesystem or solution repository.
Administrators can enforce a password change on first login or force existing users to change the password.
Credentials such as username are partly masked (depending on connection type). Administrators are able to see the full credentials (except passwords and secrets) to simplify troubleshooting.
Using kubectl and the shipped “dhinstaller” script for the certificates of a cluster to be renewed. The tool is aimed to be called by automation scripts to maintain the cluster.
The logs in elastic can be configured to retain until a certain time in addition to be retained up to a certain size.
User can output results as json and yaml and show age column for scheduled workloads, amongst others.
Cluster administrator can assign resource-quota's (CPU, Memory, Pod) to the tenant (via policy).
It is now possible to import/export files with vctl using impersonation. This allows an admin to manage the files of other users.
Protected application parameters can not be changed by users, even if they are tenant administrators.
For REST API use cases, users can now request client certificates from the vSystem server when previously authenticated and use them for the duration of the configured validity duration. Admins are also able to revoke certificates or (tenant-scoped) certificate authorities. Additionally, certificate status lists can be requested to confirm the validity out-of-band.
If an internal user enters incorrect password five consecutive times within a minute, the user will be locked-out temporarily for ten seconds until next attempt.
These are the new functions, features and enhancements in SAP Data Intelligence 3.2, on-premise edition release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
If you are interested, please refer to What’s New in Data Intelligence – Central Blog Post.
For more updates, follow the tag SAP Data Intelligence.
We recommend visiting our SAP Data Intelligence community topic page to check helpful resources, links and what other community members post. If you have a question, feel free to check out the Q&A area and ask a question here.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
Within this blog post, you will find updates on the latest enhancements in 3.2. We want to share and describe the new functions and features of SAP Data Intelligence for the Q4 2021 release.
If you would like to review what was made available in the previous release, please have a look at this blog post.
Overview
This section will give you only a quick preview about the main developments in each topic area. All details will be described in the following sections for each individual topic area.
SAP Data Intelligence 3.2



Connectivity & Integration
This topic area focuses mainly on all kinds of connection and integration capabilities which are used across the product – for example in the Metadata Explorer or on operator level in the Pipeline Modeler.
Support TLS for Oracle and SAP IQ Connection Types
Configure TLS encryption for Oracle and SAP IQ connections in Connection Management application.
JSON Consumer Operator with Flatten Schema, Metadata definition, preview
Flowagent based Structured File Consumer supports consumption of valid JSON files with JSON or JSONL extension.
Custom Editor support of Structured File Consumer
Configure the Structured File Consumer operator using the new form-based editor. The custom editor lets you to define the projection of columns, apply filters, and preview data.
Partitioning Support for Structured Operators
In the Data Intelligence Modeler under the category 'Structured Data Operators', the Table Consumer and SQL Consumer operators now provide configurations to support partitioning across data boundaries, allowing loading in parallel to increase performance. For all sources, users can define a logical partition by filtering. For Oracle sources they can define row ID and physical partitions in the Table consumer operator.
SAP HANA Data Lake Connection Type
Users may now create connections of type HDL_DB which allows connection to SAP HANA Data Lake, to be used in conjunction with the following structured operators in pipelines: Structured Table Consumer, Structured Table Producer, Structured Data Transform, Structured SQL Consumer, and Flowagent SQL Executor.
Support HANA Calculation View with Input Parameters for Rules
Ability to run Data Quality Validation rules on SAP HANA calculation views with parameters to determine the quality of the data.
- Selection a HANA Calculation View that contains parameters as the source for rule execution within a rulebook.
- Ability to specify the parameter values to use when performing a rulebook execution against a HANA Calculation View with parameters.
- User access to parameter help that is available when entering Calculation View parameter information.
Support HANA Data Lake Files as a dedicated Connection type
Introduction of a new connection type that allows to connect to HANA Data Lake Files. It is possible to:
- Write and read files using associated SAP Data Intelligence operators
- Use the new connection type in the Metadata Explorer for browsing purposes, Metadata preview and data preparation actions
Support Load Balancing for connection type ABAP_LEGACY
Connections using ABAP_LEGACY connection type now support load balancing.
Support Snowflake connection and operator
New connection type for Snowflake that can be browsed from within Metadata Explorer and provide new Data Pipeline Operators for reading data and executing statements.

Standard Template for ABAP to Data Lake scenarios
Graph templates in form of snippets that can be used to replicate data from ABAP-based systems into a data lake based on object store or Kafka.
Support of SNC encryption for RFC based ABAP connections
Support SNC encryption for connection type ABAP via RFC protocol for ABAP-based on-premise systems.
Connection Manager: show "created by" in connection list
In case of questions regarding the connection, “created by” will be the go-to person.
Support of additional ABAP Data Format Conversions
Please note that this functionality is depending on the connected ABAP system and not directly included in DI 2110 as a feature. You can check SAP note 3105880 for more details.
USE CASE DESCRIPTION:
- Support of different data type conversions using SAP source systems with SLT / ECC and S/4 HANA source systems using Generation 1 Operators.

BUSINESS VALUE – BENEFITS:
- When extracting the data out of legacy ABAP system to target system, users can switch between pre-defined different format conversions.
Simplified Operators for Core Integration Scenarios
Introduction of new operators with unified table type and efficient recovery support to implement core integration scenarios
- Connections: HANA, 3rd Party Databases (Table Consumer),
File Readers, and Application Consumer - Processing: Structured Data Transform, Python, and standardized Table Encode/Decoder (CSV, JSON, Parquet, ORC)
Operators are available as a new ”Generation 2” category and do not interfere with existing graphs and operators

Metadata & Governance
In this topic area you will find all features dealing with discovering metadata, working with it and also data preparation functionalities. Sometimes you will also find information about newly supported systems.
Import Metadata Explorer Tags and Tag Hierarchies Using Public APIs
APIs have been added to Metadata Explorer that allow to import tag and tag hierarchies from external metadata catalog and data governance systems. This enables the enrichment of metadata with auto classifications, correlations, and suggestions stemming from outside systems.
Rules Advanced Condition Script Supports New Functions
The Metadata Rules advanced condition script editor now allows functions is_unique and is_data_dependent to be used in rule condition scripts. Information Steward rules containing functions is_unique and is_data_dependent can be imported to Metadata Explorer and added to rulebooks for execution.
Role-based access and coarse-grain policies in data governance
USE CASE DESCRIPTION:
- Support Metadata Explorer (ME) resource types containing a list of corresponding activities to allow creation of custom policies.
- Consume exposed predefined Policies pre-configured with resource types/activities corresponding to standard roles such as Business User, Data Steward, Publisher, and so on.
- Policies will apply on the type of resource (rulebook, metadata catalog, glossary,...), and have one configurable activity.
BUSINESS VALUE – BENEFITS:
- Democratization of metadata management capabilities to multiple personas
- data steward
- business analyst
- data engineer
- data scientist
with necessary enforcement of governance with necessary roles.

Export failed data quality rule records to SAP HANA Cloud
USE CASE DESCRIPTION:
- Ability to export / write failed data to an existing supported SAP HANA source
- Ability for an administrator to set a global configuration to use for populating the failed record data.
- Allow users to select either overwrite or append modes
BUSINESS VALUE – BENEFITS:
- Allow users to export all the failed records from data quality validation rulebook so further analysis can be made.
- Provide ability for failed record information to be able to accumulate within the same schema over time.
- Understand detailed information about failed rules, including:
- Information to be able to uniquely identify which rule failed in cases where a rulebook has multiple rules present.
- Rule, rulebook, and dataset metadata to be able to match with results shown within the Metadata Explorer

Scheduler for publications within Metadata Explorer
USE CASE DESCRIPTION:
- Scheduling of publication of metadata
- Ability to create a publication and setup a schedule
BUSINESS VALUE – BENEFITS:
- Automate the maintenance of publications with the latest metadata
- Provide scheduling to create, modify, and view scheduled publications
- View end-to-end tracking of scheduled events

SAP Information Steward connector (Hybrid EIM)
USE CASE DESCRIPTION:
- Connect to an existing SAP Information Steward - browse, preview, and select projects to import rules into SAP Data Intelligence rules.
- Support new "INFORMATION_STEWARD" connection type in SAP Data Intelligence Connection Management.
- Metadata Explorer allows users to pick an Information Steward connection to import rules and its bindings.
BUSINESS VALUE – BENEFITS:
- Seamlessly reuse approved SAP Information Steward rules within SAP Data Intelligence.
- Enables validation and quality rules to apply to a widely expansive cloud and on premise of sources and applications.
- Substantial reduction of time to redevelop rules while gaining faster insight into quality and trustworthiness of newly added sources and applications.
- Improves governance and quality control by sharing, maintaining, managing, and governing all rules.
- Increases collaboration between users, as well as SAP applications.


Lineage support for BW extensions
USE CASE DESCRIPTION:
- Collect and browse additional BW InfoProviders
- Add support for SAP HANA Views used in BW Composite Providers
- Object-level lineage
- View lineage from the BW composite provider to the SAP HANA view
BUSINESS VALUE – BENEFITS:
- Greater insight into SAP HANA Calc Views metadata
- Collect additional BW object-level lineage
- Provide Data Stewards and IT users a way to quickly search metadata
- More meaningful metadata discovery with enhanced filtering and improved dependency collection
- End-to-end data lineage
- Extend analytical and operational system scope of metadata object collection and relationship detection for a more complete system landscape

Public APIs for Metadata exchange
USE CASE DESCRIPTION:
- Enable bi-directional exchange of data with 3rd party catalog solutions
- Crawl metadata sources that are not natively supported
BUSINESS VALUE – BENEFITS:
- Improve metadata understanding and discovery
- Expand catalog with data classifications
- Enhance auto-tagging
- Enrich metadata with auto classifications, correlations, and suggestions from non-SAP solutions
- Seamless integration with 3rd party tools, such as, BigID


Improve scalability with async loading and tenant app
- Multiple concurrent users can use Metadata Explorer without running out of cluster resources
- Concurrent publications can be started without performance degradation
- Response time reduced when publication is running in parallel
- Very slow initial call to metadata to start up user pod eliminated
Improve column handling
- Previously, when a user retrieves dataset factsheet, the backend creates an adapted dataset that will be used to preview. This is generated by call flowagent dataset definition or catalog definition depending on where the user is in the UI and if it is published or not, which filter out any unknown columns that cause preview to fail.
- New, set flags to control the UI actions if preview is supported and if user interaction is require before preview is allowed (require parameters with no default value). Information is added into properties and exposed to user. When the hidden or read-only capabilities are set they will show up in the fact sheet > column details card
Expand sources for Metadata capabilities
- Add ability to profile SAP IQ
- Add Metadata Explorer extraction and publication for Amazon Redshift -- support browsing Amazon Redshift
- Add Metadata Explorer extraction and publication for Google Big Query -- support browsing Google Big Query
Scheduling Rulebooks in Metadata Explorer
USE CASE DESCRIPTION:
- Scheduling of rulebooks in Metadata Explorer
- Select to have a rulebook run on a schedule to keep your data quality information up to date
- Ability to create a rulebook and setup a schedule to automatically run the rulebook on a reoccurring basis
BUSINESS VALUE – BENEFITS:
- Always monitor the most updated rulebook results
- Automate the maintenance of rulebooks with the latest metadata
- Provide scheduling to create, modify, and view scheduled rulebooks
- View end-to-end tracking of scheduled events

Support Data Preparation on Failed Records
USE CASE DESCRIPTION:
- Ability to execute a rulebook and choose to have all failed rule results populated to an SAP HANA connection.
- Easily create a data preparation based a sample records that failed defined validation and quality rules.
- After creating a preparation recipe, the user will be able to apply the recipe on all the records from the source.
BUSINESS VALUE – BENEFITS:
- Increase the quality of the data
- Use data preparation to correct and improve data quality and compliance of the data.
- Effortlessly add the result of a preparation back into a rulebook to monitor quality and make sure that the results on the full dataset are improved.

Ability to support rules on SAP HANA Calc Views with parameters
USE CASE DESCRIPTION:
- Execute rules against a HANA Calculation View that contains parameters.
- Ability within a rulebook for the user to select a HANA Calculation View that contains parameters as the source for rule execution.
- Power to allow users to specify the parameter values to use when performing a rulebook execution against a HANA Calculation View with parameters.
BUSINESS VALUE – BENEFITS:
- Understand the quality of data in SAP HANA Calc Views with parameters.
- Monitor quality of SAP HANA Calc View with parameters.
- View and understand the quality trend of the HANA Calc View with parameters.

Add Profiling – Add Data Preparation – Add Publishing… within Metadata Explorer
BUSINESS VALUE – BENEFITS:
- Improved performance of lineage extraction using lineage delta extraction
- New sources supported in Metadata Explorer (Snowflake and SAP Data Lake Files) *
- Expanded functionality support for sources **
Note: * and ** new with SAP Data Intelligence 3.2

Rule column in remediation preparation UI
USE CASE DESCRIPTION:
- Run a rulebook and create a preparation based on failed records
- Open preparation to remediate the records that failed the defined rules
- Use self service data preparation to correct, standardize, and enrich data

BUSINESS VALUE – BENEFITS:
- Improve quality and trustworthiness of data
- Identify and remediate data to comply with organizational standards
- Easy to use and intuitive data preparation to correct data

Schedule Profiling Tasks in Metadata Explorer
USE CASE DESCRIPTION:
- Scheduling of profiling tasks in Metadata Explorer
- Select to a profile task to run on a schedule to ensure you data insight is the most current
- Ability to create a profile task and setup a schedule to automatically run the profile task on a reoccurring basis

BUSINESS VALUE – BENEFITS:
- Always view the most updated rulebook results
- Automate the profiling tasks with the latest metadata
- Provide scheduling to create, modify, and view scheduled profiling tasks
- View end-to-end tracking of scheduled events
Support Custom Attributes with Rules
USE CASE DESCRIPTION:
- Support custom attributes within rules to add extra insight to a defined rule
- Ability to import SAP Information Steward's custom attributes for a rule into Metadata Explorer

BUSINESS VALUE – BENEFITS:
- Gain greater insight and understanding around data quality and validation rules
- Tightly link glossary terms, custom attributes to rules
- Reuse existing and approved custom attributes used within SAP Information Steward through IS Connection type or zip file

Copy Rule and Rule Bindings
USE CASE DESCRIPTION:
- Ability to copy an existing rule to save time from having to recreate shared functionality
- Copy an existing rule bindings to a dataset instead of having to recreate a dataset and binding to columns in the dataset
- Copy rule binding(s) from one rulebook to another rulebook

BUSINESS VALUE – BENEFITS:
- Save time and protects users from missing mapping input parameters
- Save time by copyingrule binding(s) from one rulebook to another and not have to recreate from scratch

Public (Rule) APIs in Metadata Explorer for Metadata Exchange
USE CASE DESCRIPTION:
- Export out Data Intelligence rules
- Create public API to access rule definitions, rulebooks, and rule results
- Gain access to rule results outside of SAP Data Intelligence
- Ability to access bound rules through rule APIs users can create their own reports
BUSINESS VALUE – BENEFITS:
- Ability to share definition or rules, rulebooks, and rule results with external reporting tools
- Capacity to build custom data quality reports
- Ability to view quality improvements of data over time
- Identify datasets with bad quality of data – untrustworthy data

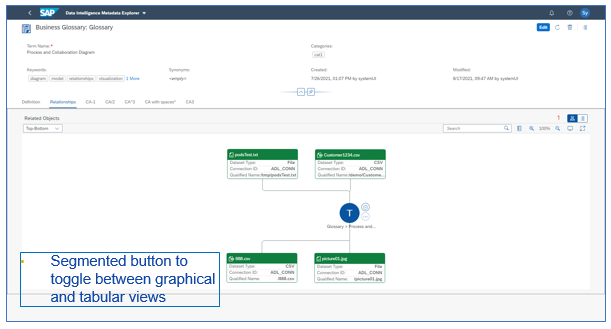
Ux refactoring of Glossary Term View / Edit
USE CASE DESCRIPTION:
- Combined view and edit of term modes into one screen
- Support to include a tabular view for relationships

BUSINESS VALUE – BENEFITS:
- Improved seamless experience between viewing and editing a term
- Improve user experience and usability for glossary
Pipeline Modelling
This topic area covers new operators or enhancements of existing operators. Improvements or new functionalities of the Pipeline Modeler and the development of pipelines.
Graph snippets for dynamic operators
Operators such as the ABAP readers have dynamic attributes that could not be handled by snippets for now. With the new version, these attributes are supported to build domain-specific snippets.

Support case transform operation
The ”Data Transform” operator now allows to model cases in the ETL process.

Enhanced UI for Structured Table and File Consumers/Producers
The Structured Table Consumer operator UI has been enhanced to support additional features such as projection and filtering, input parameters, variables, and value help for calculation views, as well as preview of the adapted data set. Also, the Table and File Producers have an improved UI to select columns.

Compression for Kafka operators
Compression support for Kafka Producer operator.

New Trace UI
The trace tab is now moved to graph specific runtime view. You can do an initial troubleshoot of running graphs in the Pipeline Modeler UI. You can view the trace records based on selected GROUP and TRACE LEVEL settings. Modify the group and trace level settings anytime and fetch recent K8s pod logs. You can also perform a search through the trace records on text editor.

Compression Option for Table Replicator
The Table Replicator operator offers a configuration option to produce compressed Parquet or Orc files in the target.

Graph Debugging with Breakpoints

Upsert Mode for Structured Table Producer
Using 'append' write mode with the Structured Table Producer operator will surface a new property 'upsert' which allows the user to specify that the pipeline should overwrite records in the target based on the table primary key.

Automated recovery of pipelines
- Pipelines can automatically re-start in case of (temporary) failures
- Configured by maximum number of re-starts in recovery interval
- Pipelines can be paused and re-started with given configuration
- Restarted pipelines are grouped in Modeler and can be fully analyzed (traces, logs, metrics)


New Data Types for Low-code Scenarios
- Introduction of general table type to simplify data processing pipelines
- Replacement of the “message” types used in the existing operators
- New underlying Data Type Framework:
- Existing core data types (int16, int64, …)
- Ability to build complex data types (structs)
- Primary table type for structured data processing
- Read and write of data using streams for lower memory consumption
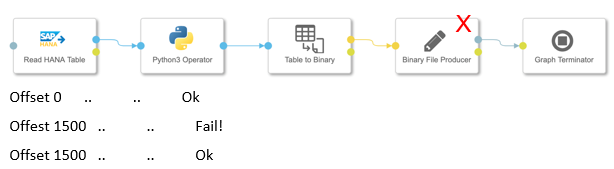
Stateful Pipelines for efficient recovery
- Operators save snapshots with processing state(e.g., offset state in HANA reader)
- On failure, the pipeline can be re-started from the last saved snapshot for efficient recovery
- Allows to implement resilient and long running pipelines
- Introduced as part of new operator category (Generation 2), existing pipelines and operators are not affected
Intelligent Processing
This topic area includes all improvements, updates and way forward for Machine Learning in SAP Data Intelligence.
Jupyter Operator for Pipeline Development:
- launches a Jupyter notebook application where you can create new notebooks / open existing notebooks from within the respective location.
- allows execution in either an “interactive” mode or a “productive” mode.
- Interactive mode: Jupyter notebook UI is accessible and identified cells can be manually executed to interact with the current data flow
- Productive mode: Jupyter Operator behaves like a Python 3 operator and no user interaction is required to run identified cells

New Functional Service Operators
There are new operators available that represent pre-trained ML services:
- Optical Character Recognition (OCR)
- Image feature extraction
- Image classification
- Similarity Scoring
- Text classification
- Topic detection

Administration
This topic area includes all services that are provided by the system – like administration, user management or system management.
Admin features for pipelines
Allow tenant administrators to monitor the pipelines of all users.

Solution handling in User Workspace
When importing solutions to the User Workspace the meta data gets persisted and can be re-used when exporting to the filesystem or solution repository.

Password reset for internal users
Administrators can enforce a password change on first login or force existing users to change the password.

Improved credential handling for connections
Credentials such as username are partly masked (depending on connection type). Administrators are able to see the full credentials (except passwords and secrets) to simplify troubleshooting.

Simplified certificate renewal
Using kubectl and the shipped “dhinstaller” script for the certificates of a cluster to be renewed. The tool is aimed to be called by automation scripts to maintain the cluster.
Time-based retention for elastic search logs
The logs in elastic can be configured to retain until a certain time in addition to be retained up to a certain size.
Various vctl improvements
User can output results as json and yaml and show age column for scheduled workloads, amongst others.
Resource Quota Tenant Policy Assignment
Cluster administrator can assign resource-quota's (CPU, Memory, Pod) to the tenant (via policy).

Command line client improvements (vctl)
It is now possible to import/export files with vctl using impersonation. This allows an admin to manage the files of other users.

Protected application parameters
Protected application parameters can not be changed by users, even if they are tenant administrators.
Allow client certificate authentication for vsystem users
For REST API use cases, users can now request client certificates from the vSystem server when previously authenticated and use them for the duration of the configured validity duration. Admins are also able to revoke certificates or (tenant-scoped) certificate authorities. Additionally, certificate status lists can be requested to confirm the validity out-of-band.

Temporary internal user lock-out after successive erroneous password attempts
If an internal user enters incorrect password five consecutive times within a minute, the user will be locked-out temporarily for ten seconds until next attempt.

These are the new functions, features and enhancements in SAP Data Intelligence 3.2, on-premise edition release.
We hope you like them and, by reading the above descriptions, have already identified some areas you would like to try out.
If you are interested, please refer to What’s New in Data Intelligence – Central Blog Post.
For more updates, follow the tag SAP Data Intelligence.
We recommend visiting our SAP Data Intelligence community topic page to check helpful resources, links and what other community members post. If you have a question, feel free to check out the Q&A area and ask a question here.
Thank you & Best Regards,
Eduardo and the SAP Data Intelligence PM team
- SAP Managed Tags:
- SAP Data Intelligence
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
85 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
269 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
10 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,578 -
Product Updates
317 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
388 -
Workload Fluctuations
1
Related Content
- Experiencing Embeddings with the First Baby Step in Technology Blogs by Members
- Understanding AI, Machine Learning and Deep Learning in Technology Blogs by Members
- If I run Cross-Model Copy while doing a lot of data mapping in SAC, what should I do? in Technology Q&A
- Harnessing the Power of SAP HANA Cloud Vector Engine for Context-Aware LLM Architecture in Technology Blogs by SAP
- S/4HANA 2023 FPS00 Upgrade in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 15 | |
| 12 | |
| 11 | |
| 9 | |
| 9 | |
| 9 | |
| 9 | |
| 9 | |
| 8 | |
| 8 |