
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- Top-Down Distribution in SAP S/4HANA
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-09-2021
9:39 AM
Introduction
This blog post continues a series of Controlling related topics, which circle around showcasing new functionalities in SAP S/4HANA Cloud, comparing functionalities between SAP S/4HANA Cloud and SAP S/4HANA (on premise), as well as general topics to be considered from Management reporting/Controlling point of view when implement SAP S/4HANA.
Focus of this blog posting is on the functionality of Top-down Distribution, which is available in both SAP S/4HANA Cloud and SAP S/4HANA (on premise) and is part of the Universal Allocation.
- It is a powerful tool to distribute costs and revenue
- If you are new or interested in SAPs Universal allocation you can refer to e.g. following postings (LINK 1 and LINK 2 ) or SAP help (LINK) for more information.
Top-Down Distribution vs. Allocations
Top-down distribution is a functionality within Margin Analysis, in which revenue or costs can be distributed from an aggregated level to a more granular level, to enable a more detailed profitability analysis. This makes sense for those costs that can only be captured at a higher level e.g. a freight invoice that does not specify the products carried.
Top-down distribution differs from allocations in the way that it does not change the amount on the sending object, it only distributes it to a more granular level (Comparing to allocations, where the sender is typically reduced with certain amount). An example is shown in figure 1, comparing and Overhead Allocation with top-down distribution.

Figure 1: Example showing difference between fixed percentage cost center overhead allocation and Top-down Distribution using revenue as reference.
Common examples of when to use top-down distributions are e.g. freight invoices, insurance expenses, advertising costs, or other items which are booked on an aggregated level (e.g. product group or customer group) and could be distributed to a more granular, e.g. using revenue postings as “reference”.
In case the original posting is not posted on a profitability segment (e.g. customer group), but only on cost center. Then, before doing the top-down distribution you can run an allocation to margin analysis (from cost center to profitability characteristic dimension), after which you can perform the top-down distribution. This approach can also be used to reduce number of records. It is also worth noticing that you cannot perform top-down distribution for attributed profitability segments.
Figure 2 shows an example where freight and insurance costs are initial booked on a product group level (without product information), and then distributed to product level with top-down distribution. Top-Down Distribution is done with reference to the revenue accounts for which postings have been captured on product level (and by product group). This allows the system to distribute the product group values (higher level) to the products (more granular).

Figure 2: Example of top-Down Distribution
Some further key highlights:
- Top-down distributions can be done for actual values, but the reference values can also be planned values (or quantities).
- Meaning that the allocated cost, can be based on plan quantities or amounts (e.g., if the actuals are not yet available).
- The distributed amount and the reference postings do not need to be within same period interval but can be in different periods.
- g., sale of the products where in January, while the freight costs to be distributed are in February.
- Top-down distribution, supports Cumulative amounts
- You can define which characteristics are to be distributed (this is done when defining the template)
- In case you are using SAP Situation handling
- Top-down distribution supports situation handling via standard situation template FIN_ALLOCATION_RUN_WARNING_ERROR. For additional information, refer to SAP Best practice scope item Situation Handling (31N).
System example
In this system example there are advertising and sales costs which are initially posted on customer group level (figure 3 showing the posting from Manage Journal Entries Fiori), which I would like to allocate to customer level, using revenue amounts as reference. This system example is from an SAP S/4HANA (on premise) 2020.
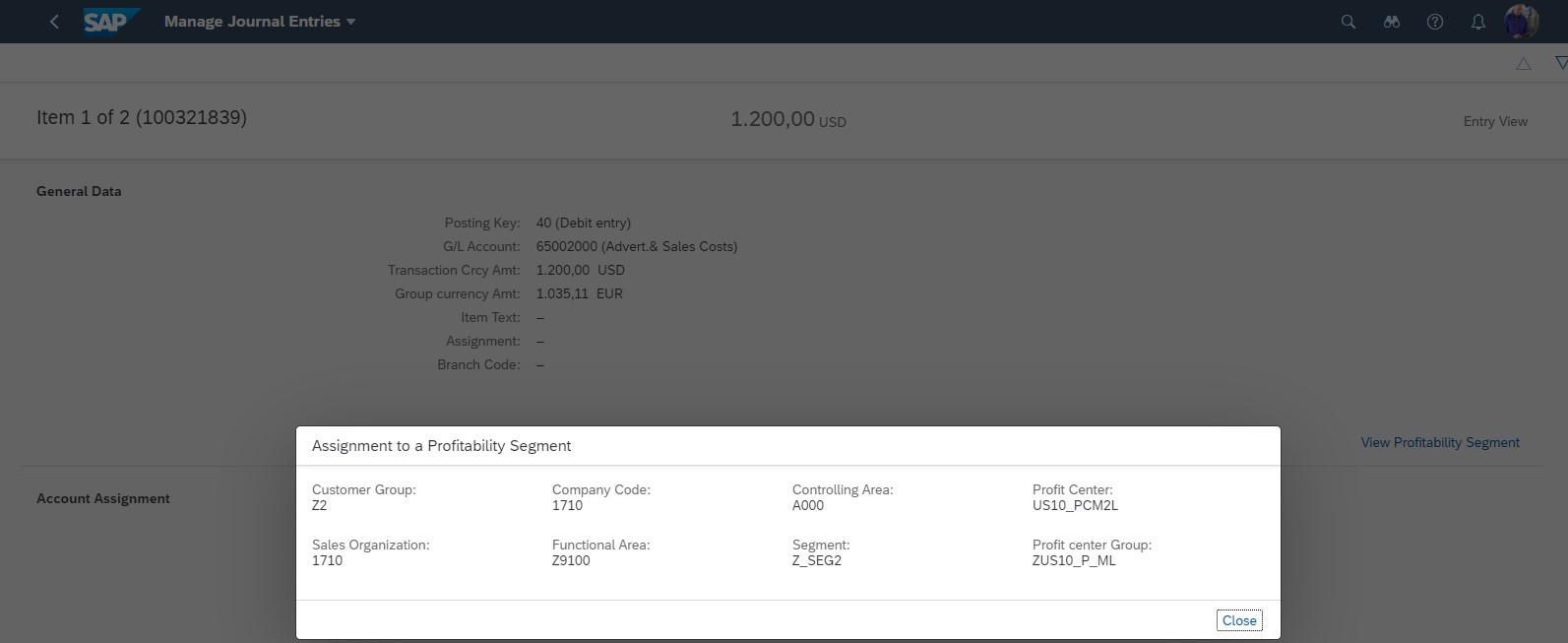
Figure 3: Manage Journal Entries Fiori, showing Initial cost posting on Customer group level “Z2”.
Creating the cycle
Before the top-down distribution can be executed, a cycle needs to be created, which contains the rules for the top-down distribution. Creating the cycle can be considered as a yearly activity, but it might need updates on certain interval (e.g. if underlying master data or postings change).
When opening the Manage Allocations fiori and clicking on “create” you can select Margin analysis and top-down distribution. When you select the allocation type “Top Down distribution” you always need to select a template to be used (Figure 4 below shows a template that can be used to allocate to customer level).

Figure 4: Manage Allocations Fiori, Example of creating a top-down distribution cycle.
In SAP S/4HANA Cloud you have three ready-made templates (Distribution by customer, By product, and by customer and product). In SAP S/4HANA (on premise) you can select to use the best practice SAP Best Practices Margin Analysis J55 or then you can configure the template(s) to be used (this is a one-time configuration and is quick to do). If you are in SAP S/4HANA (on premise), without the best practice, you should check also that your CO transaction type is assigned to a number range (AAAT – Univ.Allocation Top Dw. Dist).
Defining a Template
This section will show how to create an own template in SAP S/4HANA (on premise), to better understand how it impacts the top-down distribution results. This is an activity can be considered as a one-time activity (or seldomly to be done), but might need to be reviewed when you have new use cases for top-down distributions.
When creating a template, you need to start by giving it a description and optionally adding a tolerance limit (figure 5 below). By adding a tolerance limit, you can reduce the data volume caused by the distribution, which can improve performance. Also, it might not always be very value-adding to distribute a 0,01 value.

Figure 5: Example of Template creation in configuration (in SAP S/4HANA (on premise).
The main part of the template creation includes maintaining the fields/dimensions we want to use in the distribution (figure 6 below).
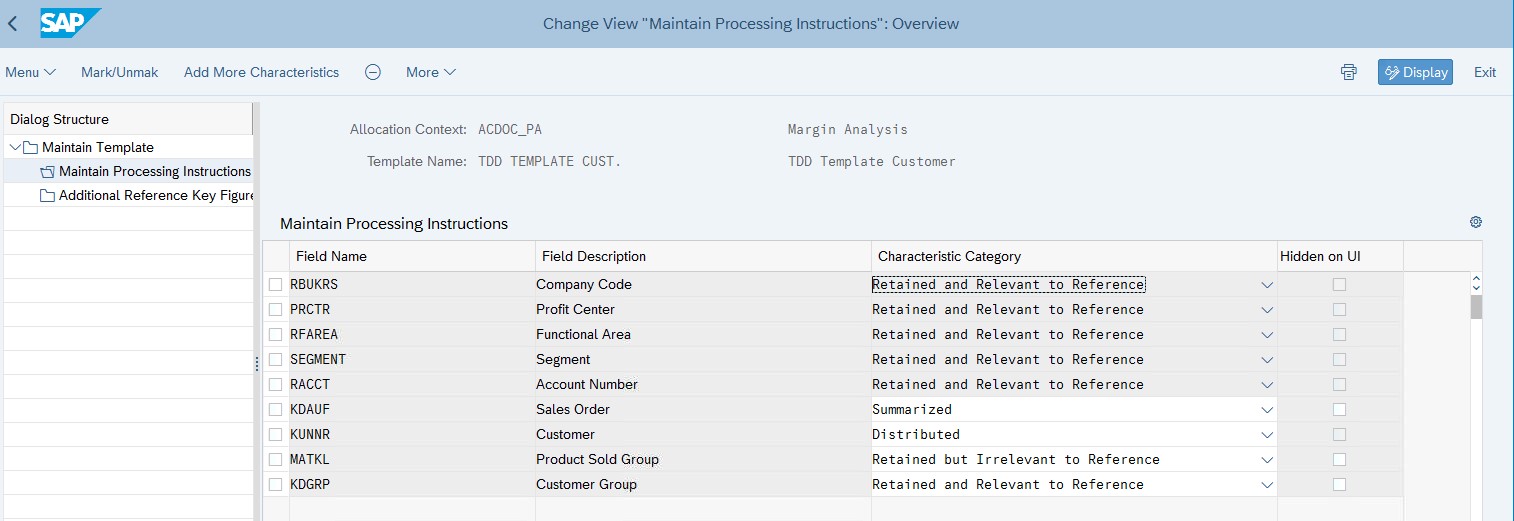
Figure 6: Example of template creation, maintaining fields for distribution in configuration.
The Characteristic category defines how different fields are handled in the top-down distribution. This is an important step, as it affects the allocation results.
- Distributed:
- This Characteristic set as this category is the detailed dimension you want to do the distribution.
- Retained and relevant for reference
- Characteristic set as this category is used for sender data and reference data selection.
- During distribution, this field is used to link sender data to corresponding reference data.
- In the distribution result, the value of this field is retained as it is in sender.
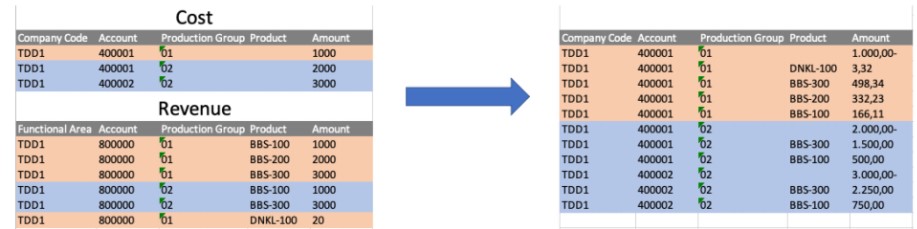
Figure 7: Example where Product group is Retained and relevant for reference.
- Retained but Irrelevant to Reference
- Characteristic set as this category is used for sender data and reference data selection.
- During distribution, this field is not used to link sender data to the corresponding reference data.
- After distribution, the value in this field is retained in the distribution result as it is in the sender.
- You should choose this category if you want more characteristic values retained in the distribution result

Figure 8: Example where Product Group is retained but Irrelevant to reference.
- Summarized
- Characteristic set as this category is used for sender data and reference data selection.
- After sender data and reference data are selected, the value in this field is cleaned up. So, the corresponding sender data and reference data will be summarized.
- In the distribution result, the value of this field will be empty. However, if the derivation logic is defined, the value will be filled from derivation.
Therefor it is worth noticing that the more fields you maintain as retained, the more data volume your top-down distribution will require. Also, you will need to maintain reference mapping “Retained and relevant for reference”, e.g. to map cost account and revenue accounts (which can require more maintenance efforts to keep the cycle up-to date).
There is also possibility to add further fields for the template (e.g. if you have created your own profitability characteristic/dimension, which you want to use in the distribution, as shown in figure 9).

Figure 9: Adding further fields to template in configuration.
Additional amount and quantity fields can be used for additional key figure reference. However, it is important that all accounting document line items should have the same unit of measurement for the chosen key figure.

Figure 10: Option of adding additional data fields for key figure reference in configuration in SAP S/4HANA (On premise).
Creating the segment for the cycle continued.
The next step is creating the segment for the cycle – In this case the segment sender is customer and initial values. The sender details are what identifies which documents should be distributed to more granular level.
- Figure 11 shows the selection of account number, company code and customer group, that have been used to select the specific cost posting to be distributed – but these can be maintained and changed according to your specific needs.

Figure 11: Manage Allocations Fiori, Example of sender details for the segment.
In the receiver Basis you need to maintain the values for selecting the receiver (Figure 12), as well as reference base mappings, for fields where senders and receiver values need to be mapped (e.g. account in below example, shown in figure 13).

Figure 12: Manage Allocations Fiori, Example of Receiver basis

Figure 13: Manage Allocations Fiori, Example of Cost account mapping to revenue account.
If so wished, it would be possible to select reference data based on plan values or quantities, instead of actuals which can be useful in certain cases (figure 14).

Figure 14: Manage Allocations Fiori, Example showing possibility of having receiver basis as based on planned values.
Executing the Cycle
Once the cycle is created it can be run by pressing the “Run” button in the “Manage allocations” Fiori or going to the “Run Allocations” Fiori. If your cycle doesn’t change too much, then this is the only activity you would need to run on a regular basis. You can also schedule the run of these cycles.
The interesting part here, is that you can select the reference period, e.g. if the reference posting are from different periods. You can also select to cumulate the reference periods.

Figure 15: Run allocation fiori app – for running the top-down distribution cycle, showing period selection.
Viewing results
To view the results, we can use the “Allocation Results” Fiori app.

Figure 16: Allocation results Fiori app.
The top-down distribution can be viewed by network graph to visualize the results, as shown in figure 17.

Figure 17: Allocation Results fiori app - Network graph showing the results of the top-down distribution.
You can also select to view only Receivers and the journal entries that occur from the top-down distribution.

Figure 18: Allocation Results fiori app, showing receivers of the top-down distribution.

Figure 19: Allocation Results fiori app, showing Journal entries from top-down distribution.
You can also drill down to the journal entry itself, below is the journal entry of the top-down distribution in this example.

Figure 20: Example of the journal entry posting from the top-down distribution – Total amount of the sender does not change.
As actuals are updated in the universal journal, you can also view it in the details from multiple different reports. Below an example using the “Journal Entry Analyzer” fiori report to look at the customer profitability.

Figure 21: Journal Entry Analyzer report showing details on customer profitability.
News for release SAP S/4HANA (on premise) 2021 which relate to top-down distribution:
With the SAP S/4HANA (on premise) 2021 release a new functionality of Calculate records is available - When using the Top-Down Distribution allocation type, you can use the Calculate Records button to calculate the theoretical data volume that will be created when you run the allocation cycle.
For further new functionalities, please visit: Universal Allocation (sap.com)
Conclusion
This blog post was focusing on top-down distribution, which can be used to distribute revenue or costs from an aggregated level to a more granular level. We covered some use-cases, how to set it up and how to view the results.
I hope it shed more light and know-how on the functionality within SAP S/4HANA.
What do you think of this functionality and can you see your organization benefitting from it (or are you already using it)?
- SAP Managed Tags:
- SAP S/4HANA Finance,
- FIN (Finance),
- FIN Controlling,
- FIN Profitability Analysis
Labels:
17 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
21 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
24 -
Expert Insights
114 -
Expert Insights
152 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
415 -
Life at SAP
2 -
Product Updates
4,685 -
Product Updates
208 -
Roadmap and Strategy
1 -
Technology Updates
1,502 -
Technology Updates
88
Related Content
- SAP ERP Functionality for EDI Processing: UoMs Determination for Inbound Orders in Enterprise Resource Planning Blogs by Members
- Deep Dive into SAP Build Process Automation with SAP S/4HANA Cloud Public Edition - Retail in Enterprise Resource Planning Blogs by SAP
- manual financial adjustments in Enterprise Resource Planning Q&A
- Continuous Influence Session SAP S/4HANA Cloud, private edition: Results Review Cycle for Q4 2023 in Enterprise Resource Planning Blogs by SAP
- SAP ERP Functionality for EDI Processing: Material Determination for Inbound Orders in Enterprise Resource Planning Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 8 | |
| 6 | |
| 5 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 |