
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- High availability and Disaster Recovery in SAP HAN...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member43
Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-26-2021
4:47 AM
SAP HANA Cloud offers options to replicate your SAP HANA Cloud database synchronously within the same availability zone or asynchronously to other availability zones since October 2021.
With these options, you can set up a Highly Available (HA) architecture and/or a Disaster Recovery (DR) architecture in a few clicks.
In the graph below, SAP HANA Cloud database is represented as a yellow box. The SYNCHRONOUS and ASYNCHRONOUS replication architectures are illustrated.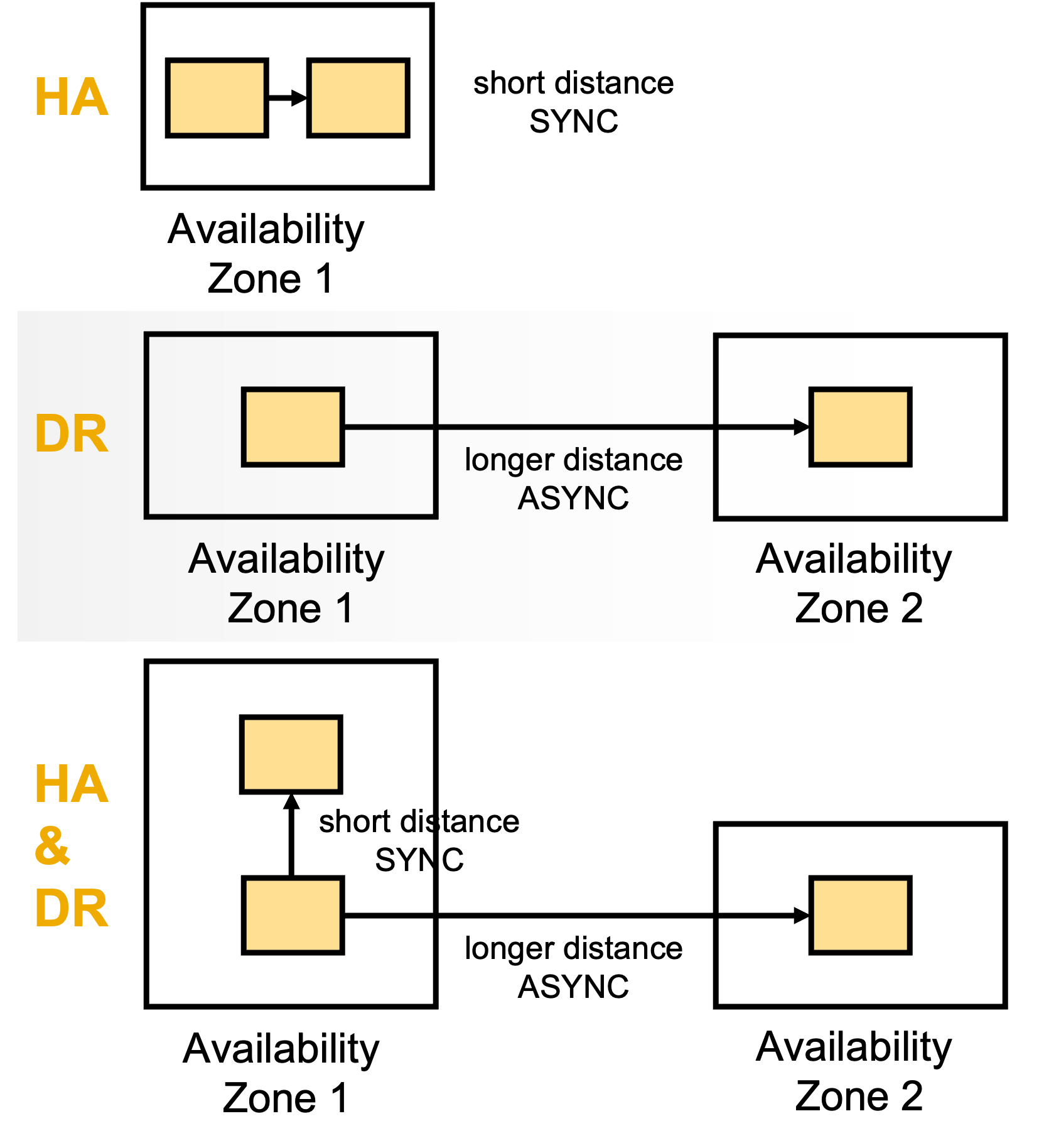 SAP HANA Cloud High availability and Disaster recovery options
SAP HANA Cloud High availability and Disaster recovery options
The technology used to ensure maximum reliability of the synchronous replicas combines SAP HANA System Replication and the failure detection mechanisms of Host auto-failover.
SAP HANA System Replication is the recommended mechanism to ensure the high availability of SAP HANA systems. With SAP HANA System Replication, customers running SAP HANA Platform on-premise can reduce outages due to planned maintenance, faults, and disasters. It supports a recovery point objective (RPO) of 0 seconds and a recovery time objective (RTO) measured in minutes.
Of course, setting up SAP HANA System Replication and Host auto-failover on-premise requires an excellent understanding of the physical infrastructure : hardware setup, server setup, and networking. It also takes weeks to test the robustness of the whole SAP HANA setup for enterprise-critical applications.
For example, when creating an automatic fail-over architecture, engineers have to consider split-brain scenarios. What should the database do when several hosts are active but cannot talk to each other ? This problem is solved in SAP HANA Cloud via a third-party token check.
With SAP HANA Cloud, the whole installation is automated, continuously monitored and managed by SAP. Customers gain access to years of expertise amassed by SAP's Cloud Operation teams in a few clicks.
With Single-Zone Replication, SAP HANA Cloud database offers a controlled synchronous replication with autonomous failover capability. The goal is to ensure database availability.
SAP HANA Cloud replicates all persistent data and changes to a secondary server in the same availability zone. The replication mode 'sync' is used, where a commit on the source service is only confirmed if the related log is also persisted on the replica service.
Fail detection is autonomous: when the nameserver detects a fault in the primary database, the host automatically fails over to the replica.
The system availability SLA of SAP HANA Cloud, SAP HANA database is 99.9% uptime.
If you enable the synchronous replica for the entire month, the System Availability SLA is 99.95% uptime.
All details regarding the Service Level Agreements of SAP HANA Cloud and other platform services are available on the SAP Trust Center.
You can enable/disable replicas at any time using SAP HANA Cloud Central in a few minutes.
The steps are described in the "Steps to use Database Replication" section of this blog.
With a Multi-Zone replication architecture, you can enable both Synchronous replication to the same availability zone, as well as Asynchronous replication to another availability zone within the same region. The goal of asynchronous replication is to ensure business continuity even in the case of a whole availability zone failing.
Availability zones (AZs) are isolated locations within data center regions from which public cloud services originate and operate.
Regions are geographic locations in which public cloud service providers' data centers reside.
Businesses choose one or multiple worldwide availability zones for their services depending on business needs. Learn more about the availability zones on each infrastructure provider website : AWS, Azure, GCP.
Disaster Recovery assumes that the primary site is not recoverable (at least for some time) and represents a process of restoring data and services to a secondary survived site.
With Asynchronous replication, SAP HANA Cloud sends data over the network to another availability zone within the same region. This ensures that the database can be used even if a whole availability zone fails. The primary system commits each transaction after sending the log without waiting for a response. Sending the data over a long distance over the network takes several hundreds of milliseconds, but there is no delay because the data transmission is asynchronous to the transaction in the primary system. Asynchronous replication provides better performance because it is not necessary to wait for log I/O on the secondary system. Database consistency across all services on the secondary system is guaranteed. However, it is vulnerable to data loss, data changes may be lost during takeover.
If a technical issue happens within your main SAP HANA Cloud instance, a takeover is automatically triggered to the replica within the same Availability Zone. The latency is extremely minimal and takeover time is measured in seconds.
With multi-zone replication, all persistent data is also replicated to another availability zone. If a disaster happens at the data center where your SAP HANA Cloud database is located, you will be able to manually trigger a takeover to your Disaster recovery instance with minimal down-time and data loss.
Additional costs incurred by creating replicas are based on the size (CPU, memory, disk) of the replica database and its location. You see an estimate of the costs while creating a new instance. You can also use the SAP HANA Cloud Capacity Unit estimator to estimate costs.
From The SAP Business Technology Platform Cockpit, select the space where you want to create a SAP HANA Cloud instance, then select "SAP HANA Cloud" on the left panel. From this screen, you can click "Create SAP HANA database" to create a new instance.
First, you must choose the type of instance to be created. Here I create a SAP HANA Database instance.
Then, give a name and a description to the instance. You also define a password for your administrator DBADMIN. On the right, you can see an estimation of the cost of running SAP HANA Cloud 24/7 for a month.
The next step is to define the memory and storage of instance. This can also be changed anytime after the instance is created.
You can define your availability zone to specify where the database instances should be placed.
This allows you to place your database instance closer to application servers or other systems that you would like to connect to with the lowest possible latency.
To ease the selection of the desired availability zone, we provide two options of availability zone lists: “SAP HANA Cloud” and “Microsoft Azure”. The “Microsoft Azure” option allows you to derive the availability zones used on your Microsoft Azure account, based on our individual subscription ID.
In this example, I am creating an instance on AWS with the "SAP HANA Cloud" list. The availability zone is assigned automatically. Here I am not setting up any replica.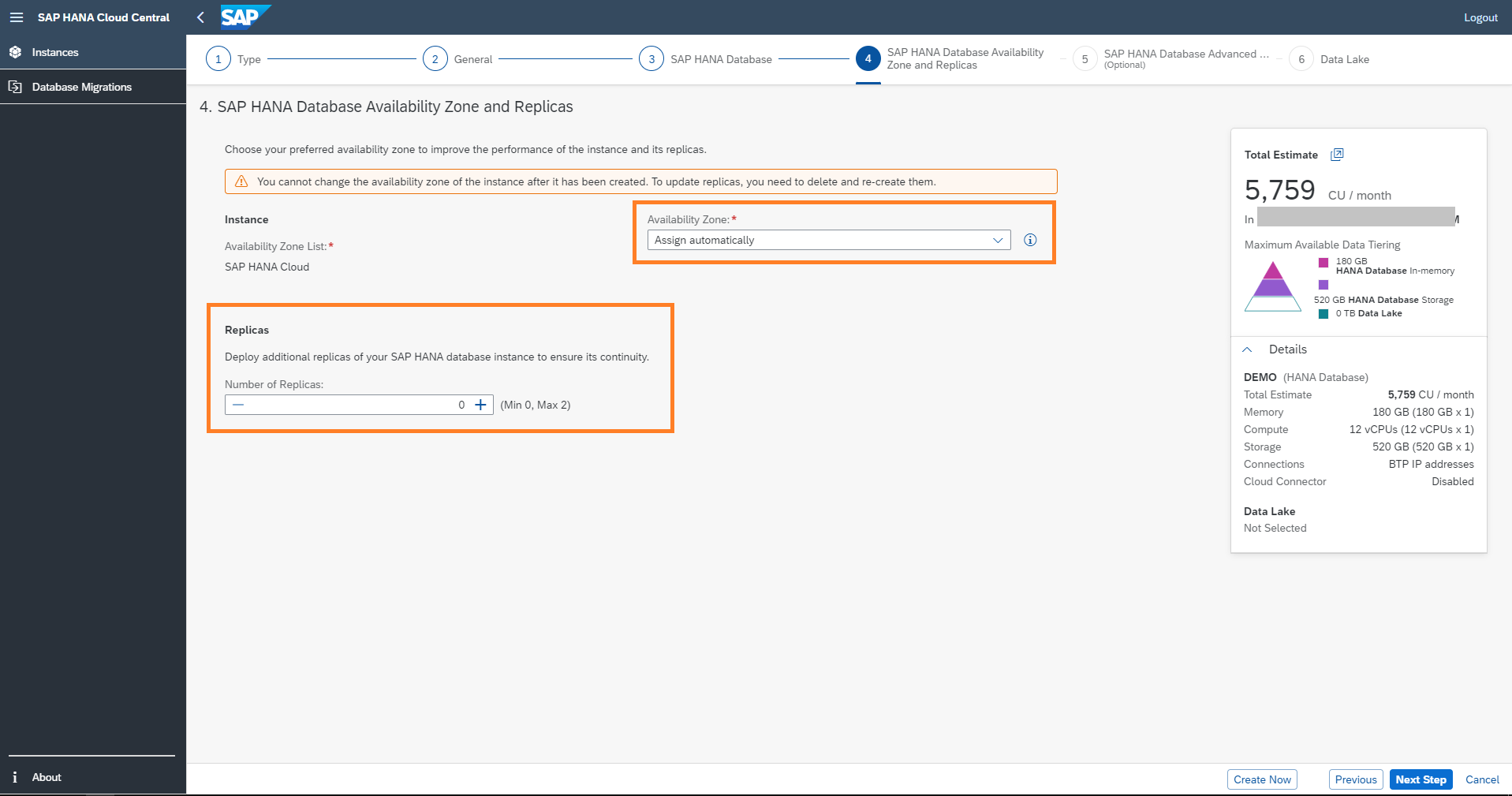
If you choose to set up 1 replica, you can choose between Synchronous replication to the same availability zone, or Asynchronous replication to another availability zone.
You can also set up 2 replicas. In this case, 1 replica will be synchronous, and the other will be asynchronous. This is the most robust architecture offered by SAP HANA Cloud.
Until now, the availability zone was assigned automatically. You can also decide on the availability zones which you want to use, depending on your cloud provider( AWS, Azure, GCP ).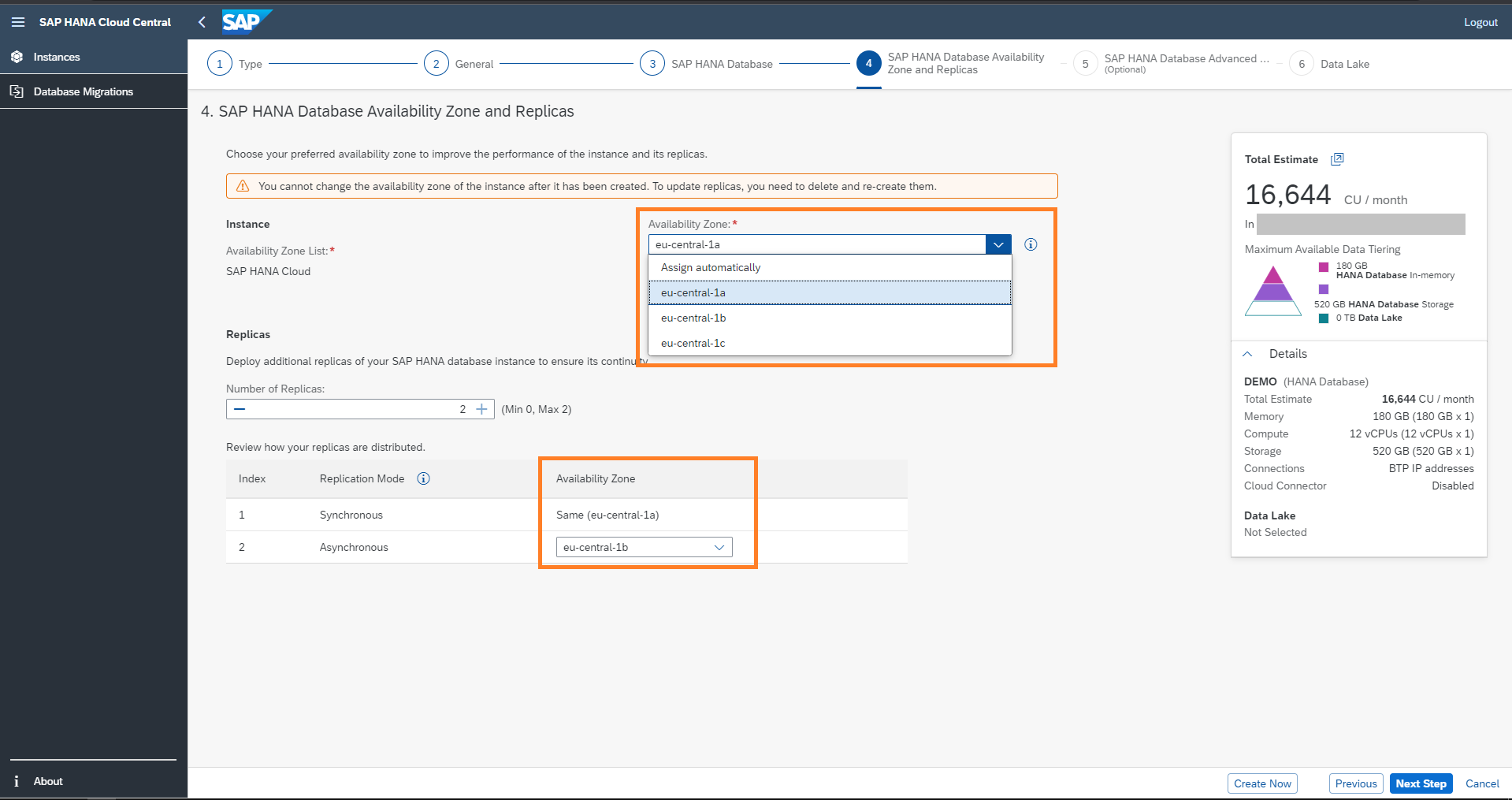
Once you have set up the replicas, you can enable additional features : Script Server, Document Store, IP Allowlist and Cloud Connector.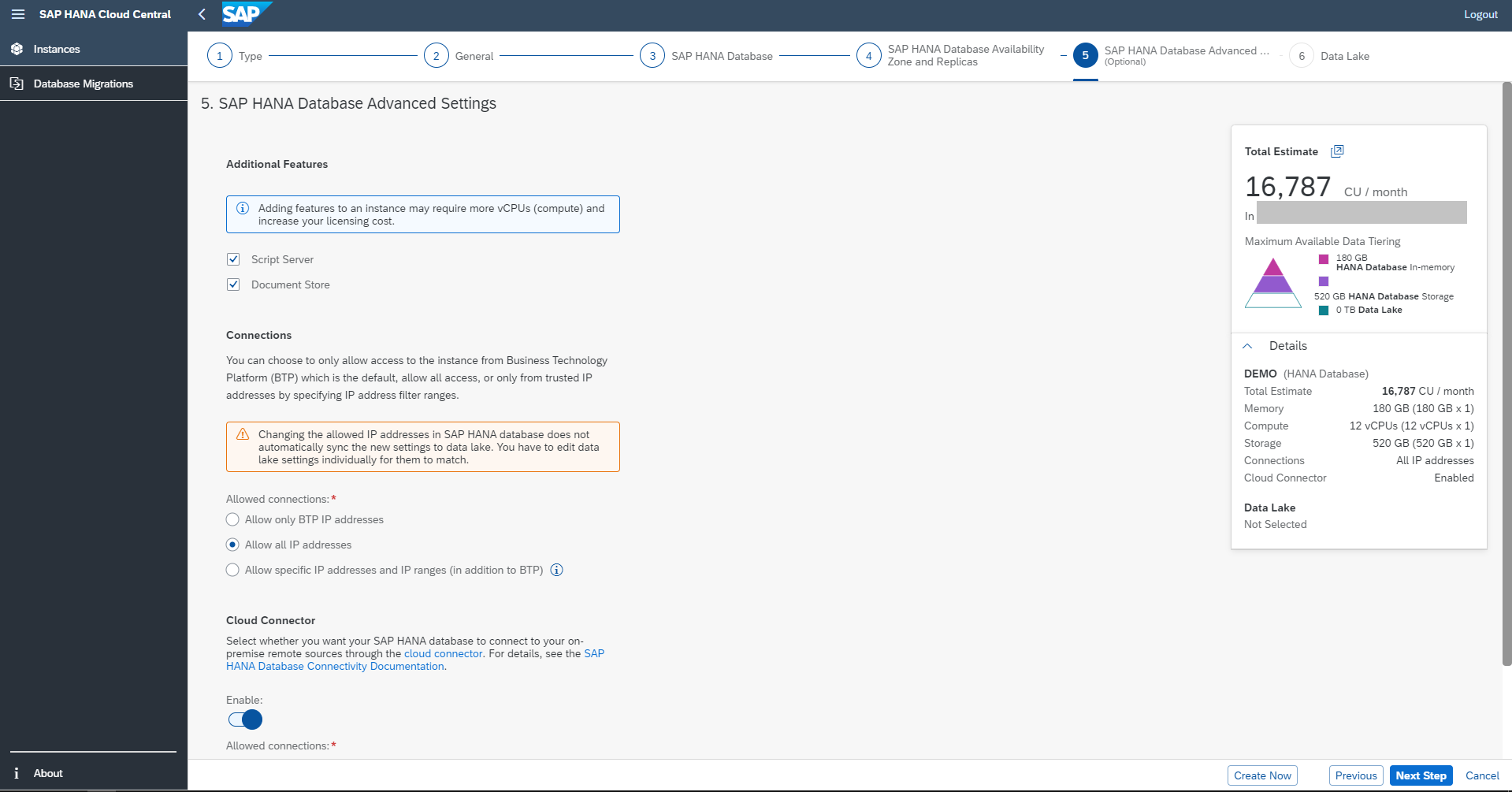
Then you can choose to set up a Data Lake. This finishes the creation of your HANA Cloud instance.
Once a synchronous replica is created, you can monitor it through SAP HANA Cockpit as a regular HANA Cloud database. It will appear on your cockpit as a second host with the same HANA instance. The name of the replica will be the name of your main instance suffixed with a number. On this screenshot, you can see the memory and CPU usage of my main database as well as the replica.
On the "Manage Services" page below, my HANA Instance is now operating on 2 hosts. The replica host shares the same name as the main host with a "-1" at the end. All services are up and running, the replica instance is ready to automatically take over if an issue happens.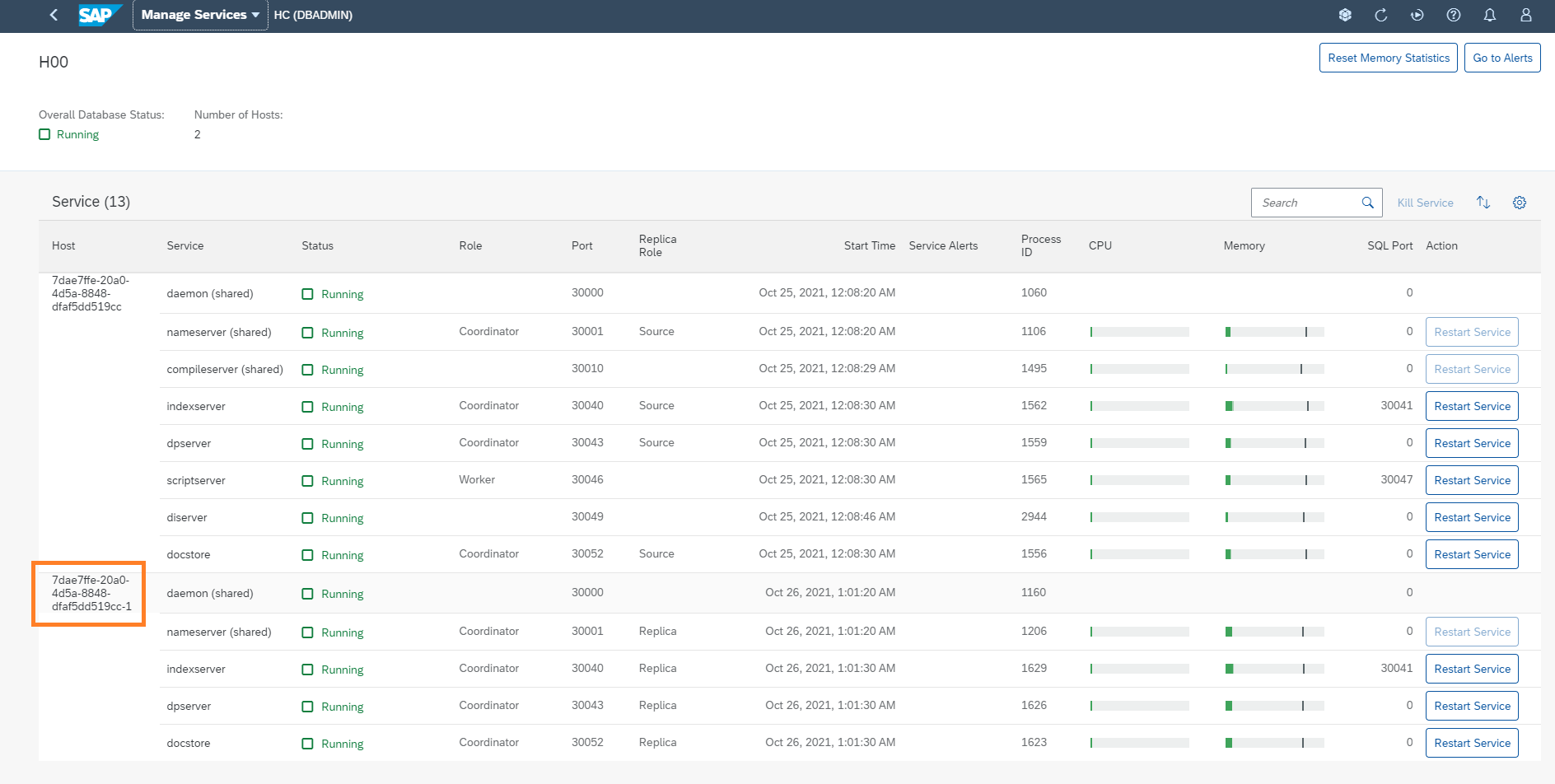
The asynchronous replica does not appear on the HANA cockpit. It is a different SAP HANA Cloud instance, which users do not need to access under normal circumstances.
You can verify that the system replication is operating correctly in the M_SERVICE_REPLICATION and M_SYSTEM_REPLICATION system views.
When a disaster happens on the primary database, you can manually perform a takeover to the replica through SAP HANA Cloud Central.
Through SAP HANA Cloud Central, you can edit existing instances: deploy additional replicas for your existing database instance or delete existing replicas.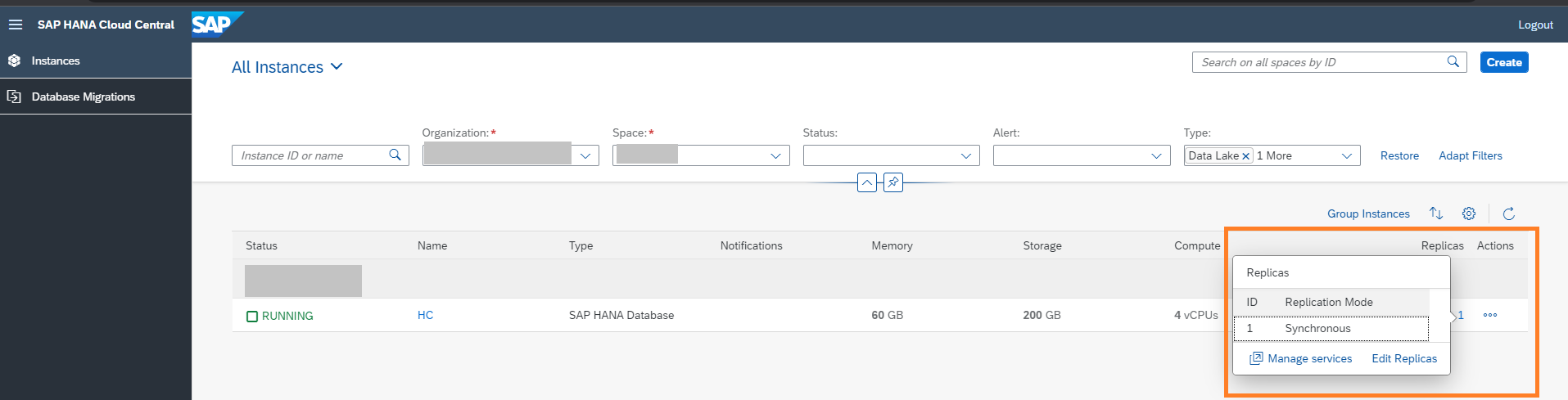
SAP HANA Cloud database performs a full backup every day and delta backups every 15 minutes.
Daily backups are only created when the database is online. Up to 15 daily backups are retained.
Delta backups ensure that up-to-date data can be recovered speedily. Thanks to delta backups, the recovery point objective (RPO) is no more than 15 minutes.
Backups are encrypted using the capabilities of the infrastructure as a service provider and replicated in additional availability zones in the same region.
You can display information about available database backups in the SAP HANA cockpit.
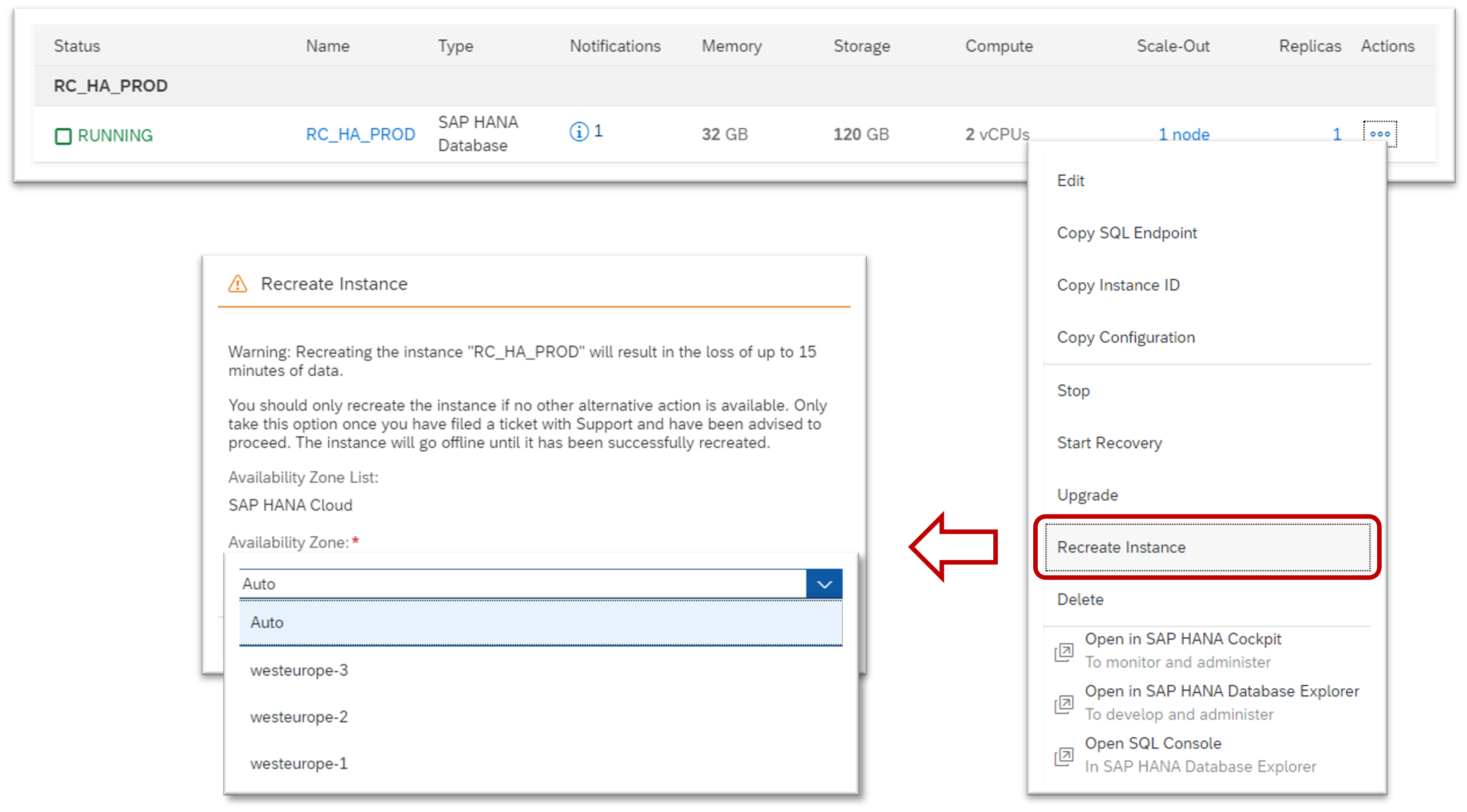
SAP HANA Cloud Central also offers the functionality to recreate existing database instances in other availability zones from a backup.
Since the database is recreated from a backup, it does not need to be active to be recreated. Therefore recreating a database is also an effective disaster recovery measure.
The instance will go offline until it has been successfully recreated.
Recreating an instance is free of cost.
Thank you for reading.
Maxime SIMON
With these options, you can set up a Highly Available (HA) architecture and/or a Disaster Recovery (DR) architecture in a few clicks.
In the graph below, SAP HANA Cloud database is represented as a yellow box. The SYNCHRONOUS and ASYNCHRONOUS replication architectures are illustrated.
SAP HANA Cloud High availability and Disaster recovery optionsThe technology used to ensure maximum reliability of the synchronous replicas combines SAP HANA System Replication and the failure detection mechanisms of Host auto-failover.
SAP HANA System Replication is the recommended mechanism to ensure the high availability of SAP HANA systems. With SAP HANA System Replication, customers running SAP HANA Platform on-premise can reduce outages due to planned maintenance, faults, and disasters. It supports a recovery point objective (RPO) of 0 seconds and a recovery time objective (RTO) measured in minutes.
Of course, setting up SAP HANA System Replication and Host auto-failover on-premise requires an excellent understanding of the physical infrastructure : hardware setup, server setup, and networking. It also takes weeks to test the robustness of the whole SAP HANA setup for enterprise-critical applications.
For example, when creating an automatic fail-over architecture, engineers have to consider split-brain scenarios. What should the database do when several hosts are active but cannot talk to each other ? This problem is solved in SAP HANA Cloud via a third-party token check.
With SAP HANA Cloud, the whole installation is automated, continuously monitored and managed by SAP. Customers gain access to years of expertise amassed by SAP's Cloud Operation teams in a few clicks.
Design a fault-resistant architecture for your organization
Single-Zone Replication (High Availability architecture)
With Single-Zone Replication, SAP HANA Cloud database offers a controlled synchronous replication with autonomous failover capability. The goal is to ensure database availability.
SAP HANA Cloud replicates all persistent data and changes to a secondary server in the same availability zone. The replication mode 'sync' is used, where a commit on the source service is only confirmed if the related log is also persisted on the replica service.
Fail detection is autonomous: when the nameserver detects a fault in the primary database, the host automatically fails over to the replica.

Single zone replication of SAP HANA Database in SAP HANA Cloud
The system availability SLA of SAP HANA Cloud, SAP HANA database is 99.9% uptime.
If you enable the synchronous replica for the entire month, the System Availability SLA is 99.95% uptime.
All details regarding the Service Level Agreements of SAP HANA Cloud and other platform services are available on the SAP Trust Center.
You can enable/disable replicas at any time using SAP HANA Cloud Central in a few minutes.
The steps are described in the "Steps to use Database Replication" section of this blog.
Multi-Zone Replication (Disaster Recovery architecture)
With a Multi-Zone replication architecture, you can enable both Synchronous replication to the same availability zone, as well as Asynchronous replication to another availability zone within the same region. The goal of asynchronous replication is to ensure business continuity even in the case of a whole availability zone failing.
Availability zones (AZs) are isolated locations within data center regions from which public cloud services originate and operate.
Regions are geographic locations in which public cloud service providers' data centers reside.
Businesses choose one or multiple worldwide availability zones for their services depending on business needs. Learn more about the availability zones on each infrastructure provider website : AWS, Azure, GCP.
Disaster Recovery assumes that the primary site is not recoverable (at least for some time) and represents a process of restoring data and services to a secondary survived site.
With Asynchronous replication, SAP HANA Cloud sends data over the network to another availability zone within the same region. This ensures that the database can be used even if a whole availability zone fails. The primary system commits each transaction after sending the log without waiting for a response. Sending the data over a long distance over the network takes several hundreds of milliseconds, but there is no delay because the data transmission is asynchronous to the transaction in the primary system. Asynchronous replication provides better performance because it is not necessary to wait for log I/O on the secondary system. Database consistency across all services on the secondary system is guaranteed. However, it is vulnerable to data loss, data changes may be lost during takeover.

Multi-Zone Replication of SAP HANA Cloud, SAP HANA database
If a technical issue happens within your main SAP HANA Cloud instance, a takeover is automatically triggered to the replica within the same Availability Zone. The latency is extremely minimal and takeover time is measured in seconds.
With multi-zone replication, all persistent data is also replicated to another availability zone. If a disaster happens at the data center where your SAP HANA Cloud database is located, you will be able to manually trigger a takeover to your Disaster recovery instance with minimal down-time and data loss.
Additional costs incurred by creating replicas are based on the size (CPU, memory, disk) of the replica database and its location. You see an estimate of the costs while creating a new instance. You can also use the SAP HANA Cloud Capacity Unit estimator to estimate costs.
Steps to use Database Replication
Create a new SAP HANA Cloud database instance
From The SAP Business Technology Platform Cockpit, select the space where you want to create a SAP HANA Cloud instance, then select "SAP HANA Cloud" on the left panel. From this screen, you can click "Create SAP HANA database" to create a new instance.

First, you must choose the type of instance to be created. Here I create a SAP HANA Database instance.
Then, give a name and a description to the instance. You also define a password for your administrator DBADMIN. On the right, you can see an estimation of the cost of running SAP HANA Cloud 24/7 for a month.
The next step is to define the memory and storage of instance. This can also be changed anytime after the instance is created.
Then, we enter the core of this blog : Availability zones and replicas.
You can define your availability zone to specify where the database instances should be placed.
This allows you to place your database instance closer to application servers or other systems that you would like to connect to with the lowest possible latency.
To ease the selection of the desired availability zone, we provide two options of availability zone lists: “SAP HANA Cloud” and “Microsoft Azure”. The “Microsoft Azure” option allows you to derive the availability zones used on your Microsoft Azure account, based on our individual subscription ID.
In this example, I am creating an instance on AWS with the "SAP HANA Cloud" list. The availability zone is assigned automatically. Here I am not setting up any replica.
If you choose to set up 1 replica, you can choose between Synchronous replication to the same availability zone, or Asynchronous replication to another availability zone.
You can also set up 2 replicas. In this case, 1 replica will be synchronous, and the other will be asynchronous. This is the most robust architecture offered by SAP HANA Cloud.
Until now, the availability zone was assigned automatically. You can also decide on the availability zones which you want to use, depending on your cloud provider( AWS, Azure, GCP ).
Once you have set up the replicas, you can enable additional features : Script Server, Document Store, IP Allowlist and Cloud Connector.
Then you can choose to set up a Data Lake. This finishes the creation of your HANA Cloud instance.
Manage Synchronous Replicas
Once a synchronous replica is created, you can monitor it through SAP HANA Cockpit as a regular HANA Cloud database. It will appear on your cockpit as a second host with the same HANA instance. The name of the replica will be the name of your main instance suffixed with a number. On this screenshot, you can see the memory and CPU usage of my main database as well as the replica.
On the "Manage Services" page below, my HANA Instance is now operating on 2 hosts. The replica host shares the same name as the main host with a "-1" at the end. All services are up and running, the replica instance is ready to automatically take over if an issue happens.
Manage Asynchronous Replicas
The asynchronous replica does not appear on the HANA cockpit. It is a different SAP HANA Cloud instance, which users do not need to access under normal circumstances.
You can verify that the system replication is operating correctly in the M_SERVICE_REPLICATION and M_SYSTEM_REPLICATION system views.
When a disaster happens on the primary database, you can manually perform a takeover to the replica through SAP HANA Cloud Central.
Edit an existing instance
Through SAP HANA Cloud Central, you can edit existing instances: deploy additional replicas for your existing database instance or delete existing replicas.
Backup and Recovery
SAP HANA Cloud database performs a full backup every day and delta backups every 15 minutes.
Daily backups are only created when the database is online. Up to 15 daily backups are retained.
Delta backups ensure that up-to-date data can be recovered speedily. Thanks to delta backups, the recovery point objective (RPO) is no more than 15 minutes.
Backups are encrypted using the capabilities of the infrastructure as a service provider and replicated in additional availability zones in the same region.
You can display information about available database backups in the SAP HANA cockpit.
When you want to restore a back-up, use the Start Recovery menu option to recover the database instance up to a selected point in time in the past for which a backup is available.
This 'point in time' recovery option does not apply to instances where SAP HANA Cloud, data lake is attached. Recovery for data lake instances can only be done through a service request.
The database instance will be offline during the recovery.
 There is no additional cost for backup storage in HANA Cloud. Backups cannot be disabled for HANA Cloud databases, but they can be disabled for the data lake.
There is no additional cost for backup storage in HANA Cloud. Backups cannot be disabled for HANA Cloud databases, but they can be disabled for the data lake.
Recreate an existing instance
SAP HANA Cloud Central also offers the functionality to recreate existing database instances in other availability zones from a backup.
Since the database is recreated from a backup, it does not need to be active to be recreated. Therefore recreating a database is also an effective disaster recovery measure.
The instance will go offline until it has been successfully recreated.
Recreating an instance is free of cost.
Thank you for reading.
Maxime SIMON
- SAP Managed Tags:
- SAP HANA Cloud
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
91 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
297 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
343 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
420 -
Workload Fluctuations
1
Related Content
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Explore Business Continuity Options for SAP workload using AWS Elastic DisasterRecoveryService (DRS) in Technology Blogs by Members
- BCP: Business Continuity Planning for SAP S/4HANA - made easy with Enterprise Blockchain 🚀 in Technology Blogs by Members
- What’s New in SAP HANA Cloud – March 2024 in Technology Blogs by SAP
- Automate Sybase ASE Backups using DBA Cockpit (Sybase:v15.7.0.021+) in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 37 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |