

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Building a Covid-19 Chatbot powered by SAP BTP (Pa...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-18-2021
2:41 PM

Introduction
This article is the second of a four-part blog post series by Sebastian Schuermann and me. We met in the 2021 Career Starter Program and together we took the opportunity to discover and work with the latest technologies as part of the SAP Innovator Challenge 2021.
Together, we developed a COVID-19 chatbot (Vyri) as a solution to keep users updated regarding regulations, news, and statistics about the current pandemic. In this series, we will present our chatbot solution, which we implemented based on SAP Business Technology Platform (SAP BTP) components. The goal of the blogposts is to share our personal experience with the SAP BTP solution portfolio and its integration.
This second blog post, “Building a Covid-19 Chatbot powered by SAP BTP (Part 2/4): Accelerating Data Transformation and Governance with SAP Data Intelligence”, will highlight how SAP Data Intelligence's data extraction, data transformation, and data governance capabilities are incorporated within the Covid-19 use case presented.
The other articles in this series can be accessed here:
- Setting the Stage (Part 1/4)
- Creating a Chatbot with SAP Conversational AI (Part 3/4)
- Data Modeling and Advanced Analytics with SAP Data Warehouse Cloud and SAP Analytics Cloud (Part 4/4...
Agenda
- What is SAP Data Intelligence?
- Integration with SAP Data Warehouse Cloud
- Data Ingestion Pipelines
- Custom Python Operator with Dockerfile
- RESTful Web Service with SAP Data Intelligence
- Data Governance Capabilities
- Conclusion
1. What is SAP Data Intelligence?
SAP Data Intelligence is a comprehensive data management solution that aims to transform distributed data sources into vital insights and deliver innovation at scale. Data Intelligence is much more than an ETL tool. SAP Data Intelligence allows to manage metadata across different data landscapes and to create a comprehensive data catalog. Data processing from different SAP and 3rd party sources can be orchestrated by Data Intelligence via powerful data pipelines. Furthermore, Data Intelligence supports the operationalization of Machine Learning.
SAP Data Intelligence can be implemented both on-premises and in the cloud. SAP Data Intelligence is a container-based software and scales via Docker containers. More information about the SAP Data Intelligence product can be found in this blog post or on the official website.
2. Integration with SAP Data Warehouse Cloud
SAP Data Warehouse Cloud is a powerful Software as a Service (SaaS) solution that combines data warehousing, data integration, and analytic capabilities, built on the SAP HANA Cloud Database.
The integration of SAP Data Intelligence and SAP Data Warehouse Cloud is seamless. Data Warehouse Cloud can be used as a persistence layer into which the data pipelines in Data Intelligence ingest data or read it. Furthermore, the SAP Data Warehouse Cloud data can be managed within the Metadata Explorer in Data Intelligence.
The following figure shows how the tables of the Data Warehouse Cloud generated from Data Intelligence in our scenario can be consumed in the Metadata Explorer of Data Intelligence:

SAP Data Warehouse Cloud tables in Metadata Explorer in SAP Data Intelligence (Image Source: Own Image)
The technical connection between the solutions is not the focus of this article. There is a very good blog article by Yuliya Reich. I would just like to mention that the SAP Data Warehouse instance can be connected via the connection type "HANA_DB" in Data Intelligence and almost all HANA operators can also be used for the SAP Data Warehouse Cloud (see my blog post on HANA operators in Data Intelligence).

SAP Data Warehouse Cloud Connection in SAP Data Intelligence (Image Source: Own Image)
3. Data Ingestion Pipelines
As described in chapter 1, SAP Data Intelligence enables the orchestration and integration of disparate data sources via powerful data pipelines. In our first blog post (link here), we already described the use case and from which data sources we retrieve information. The pipelines developed for the Vyri chatbot are described in more detail below:
- Covid-19 Regulations
The current legal situation regarding Covid-19 is subject to rapid changes in Germany. With the pipeline, the current regulations in various areas of public life (gastronomy, tourism, sports, ...) are ingested per county. For this purpose, an Excel file is stored in the SAP Data Intelligence internal data lake, in which the rules were prototypically maintained. The pipeline looks as follows:

Pipeline for retrieving the Covid-19 Measures per German County (Image Source: Own Image)
With the Read File operator the current version of the Excel file with the regulations is retrieved from the Data Lake. With the SAP HANA Client the CSV file is written into a table in SAP Data Warehouse Cloud. The Graph Terminator terminates the pipeline. The Wiretap operator can be used to monitor and debug the messages.
- Covid-19 Statistics
The current statistics (number of cases, number of deaths, incidence rate, etc.) for the Covid-19 pandemic in Germany are provided daily by the Robert Koch Institute (RKI) per county (Ger.: Landkreis). The following pipeline is used to retrieve the data from the Robert Koch Institute API on a daily basis and then persist it in SAP Data Warehouse Cloud. The pipeline looks as follows:

Pipeline for consuming the current Covid-19 Statistics per German County (Image Source: Own Image)
In the RKI Request Generator (Java Script Operator) the parameters are defined which are sent to the RKI API. In the OpenAPI Client the connection to the RKI API is configured. The operator sends the request to the API and transmits the response of the interface (JSON file) to its output port. In the JSON Formatter operator (base Python operator), the JSON file is formatted so that it can be written to a table in the SAP Data Warehouse Cloud via the SAP HANA Client. I have published a blogpost on how a JSON file can be written to SAP HANA or SAP Data Warehouse Cloud via the SAP HANA Client operator.
- Covid-19 News
Since the reporting on the Covid-19 pandemic is constantly changing, the following pipeline is intended to ingest the latest news from the German media on the pandemic. A News API is connected to extract the news. The pipeline looks like this:

Pipeline for ingesting current Covid-19 News (Image Source: Own Image)
The pipeline is structured analogously to the Covid-19 Statistics pipeline. The difference is that the parameters for the News API are defined in the Covid News Request Generator operator and the connection to the News API is stored in the OpenAPI Client. The JSON Formatter and SAP HANA Client is adapted to the data model provided by the News API.
- Covid-19 Tweets
In addition to current Covid-19 news, current tweets on the topic of coronavirus are also collected for Vyri. For this purpose, Twitter is connected via the Python client Tweepy. The pipeline looks like this:
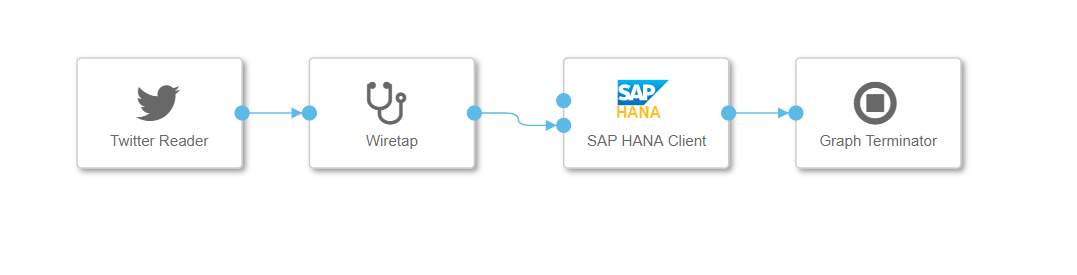
Pipeline for receiving current Tweets related to Covid-19 (Image Source: Own Image)
The Twitter Reader operator is a Python operator that reads the latest tweets via the Python library Tweepy. For this, it explicitly filters for keywords related to Covid-19 and the German language. Within the operator, the response of the Twitter client is converted into a suitable JSON format, so that the results can be written directly via the SAP HANA Client operator into an SAP Data Warehouse Cloud table.
- Sentiment Analysis of Covid-19 News and Covid-19 Tweets
To get a sense of the sentiment in the German media and Twitter community on the development of the Covid-19 pandemic, the sentiment of news stories and tweets is analyzed via a pipeline. For this purpose, the data is sent to Amazon Web Services' (AWS) Natural Language Processing service Comprehend and analyzed. The pipeline looks like this:

Pipeline for analysing the sentiment of current Covid-19 News and Tweets with AWS Comprehend
The SQL Statement Generator generates a SQL statement that reads the latest messages or tweets from the respective SAP Data Warehouse Cloud tables and the processing is then done by the SAP HANA Client. The AWS Comprehend Sentiment Analyzer (Custom Python Operator) uses a list of messages or tweets as input and sends them to AWS Comprehend. The result is further processed (e.g. average calculated) and then sent to the SAP HANA Client, which persists the results into an SAP Data Warehouse table. The AWS Comprehend Sentiment Analyzer is described in more detail in chapter 4.
4. Custom Python Operator with Dockerfile
In addition to the standard operators available for SAP Data Intelligence, it is possible to implement custom operators in various runtimes with their own logic. Currently, operators can be implemented in Python 3.6, Node.js, C++, ABAP, R, JavaScript and Go. The documentation for this can be accessed here and here.
Each programming language has its own basic operator. Own operators can then be created, which extend the respective basic operator. A custom icon can then be selected for the operators, input and output ports can be defined with data types, custom fields can be created for configuration, and documentation can also be created. Yuliya Reich has already written a helpful blogpost for the creation of a Python operator.
In our use case, we mainly extended the Python operator for custom logic (see Chapter 3). In the following, the operator AWS Comprehend Sentiment Analyzer is presented as an example. The command api.set_port_callback("input", on_input) is used to define that a message routed into the operator through the input port will call the on_input method. Then a client for the AWS service Comprehend is created and the input message (a list of strings) is sent to the sentiment analysis of AWS. The result of this analysis is used as the body for the output message. The api.send("output", api.Message([body], input_message_attributes)) command sends the output message to the output port of the operator.
def on_input(data):
# Credentials
ACCESS_KEY = 'XXX'
SECRET_KEY = 'XXX'
# Generate AWS Comprehend Client
comprehend = boto3.client(
service_name='comprehend',
aws_access_key_id=ACCESS_KEY,
aws_secret_access_key=SECRET_KEY,
region_name='eu-west-2'
)
# Get the input message
input_message_body = data.body
input_message_attributes = data.attributes
# Convert the message to a text list
textList = [i["CONTENT"] for i in input_message_body]
# Load sentiment from AWS Comprehend
sentiment = comprehend.batch_detect_sentiment(TextList=textList, LanguageCode='de')
# Calculate Sentiment Average and prepare output JSON for DWC table
body = calculate_sentiment_average(sentiment)
api.send("output", api.Message([body], input_message_attributes))
api.set_port_callback("input", on_input)The base Docker image of the base Python3 operator already contains some python libraries by default, such as Tweepy, the Python client for Twitter. The library "boto3", the Python client for using AWS services, is not included in this base image. Since the data pipelines in Data Intelligence run in Docker containers (see Chapter 1), the custom operator for AWS Sentiment Analysis might not run in the base container for the Python3 operator. Then, a Dockerfile must be created that extends the base image for Python3 with the boto3 library (see image below). A detailed description of how to create a Dockerfile and build the Docker image can be found in Thorsten Hapke's blogpost and in the official documentation.
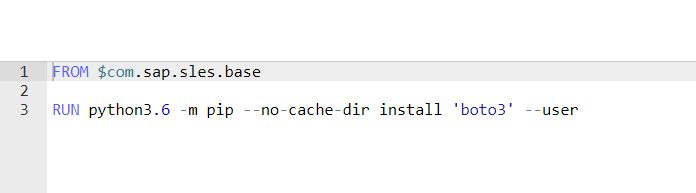
Simple Dockerfile for installing the „boto3“ library (Image Source: Own Image)
In this Dockerfile the added library must be added in the tags (optionally with a version number). The Dockerfile must then be initially built.

Tag the “boto3” library within the Dockerfile (Image Source: Own Image)
The custom operator must reference the required library's tag in the Tags tab (see next image). This will select the correct Docker image for the operator's container based on the operator's tags when the pipeline is started.

Custom Python Operator with “boto3” tag (Image Source: Own Image)
5. RESTful Web Service with SAP Data Intelligence
With the OpenAPI Servlow operator, RESTful web services can be offered in SAP Data Intelligence, which are built according to the OpenAPI specification. These provide a programmatic interface to a publicly exposed endpoint that provides messages via JSON format. Ian Henry and Jens Rannacher have written very good blogposts about how a Restful web service can be offered via SAP Data Intelligence. Furthermore, there is an openSAP Microlearning about it.
In our use case the OpenAPI Servlow operator is integrated in a pipeline which runs 24/7. The pipeline is shown below. The OpenAPI Servlow operator accepts authorized requests through the expost endpoint. The RKI Statement Generator (a custom Python operator) detects which of the endpoint's services was requested and with which parameters and generates an SQL statement from it. In the SAP HANA client, this SQL statement is then sent to the SAP Data Warehouse Cloud instance. The result of the query is sent back to the API endpoint in JSON format. The Wiretap operators are used in this use case to monitor and debug the queries.

Pipeline with “OpenAPI Servlow“ Operator (Image Source: Own Image)
There are several configuration options for the operator, details can be found in the documentation of the operator here. The "Base Path" option can be used to set the path under which the API endpoint can later be reached. Under "Swagger Specification" the offered RESTful Web Service can be defined and documented using Swagger. Swagger is an Interface Description Language that specifies the offered API using JSON. Under "Max Concurrency" it can be specified how many concurrent requests are made to the service. The following figure shows the prototype implementation of the operator in our graph:

Configuration Options of “OpenAPI Servlow” Operator (Image Source: Own Image)
In the following, the service "getLKData" with the parameter "name" (delivers the covid related statistics per county in Germany) shows how the services of an API endpoint can be documented using Swagger:
"/getLKData/{name}": {
"get": {
"description": "Show the RKI data for a specific German district (Landkreis)",
"produces": [
"application/json"
],
"summary": "Show the RKI data for a specific German district (Landkreis)",
"operationId": "getLKData",
"parameters": [
{
"type": "string",
"description": "Landkreis Name (district)",
"name": "name",
"in": "path",
"required": true
}
],
"responses": {
"200": {
"description": "RKI Data Landkreis"
}
}
}
},As soon as a pipeline with the OpenAPI Servlow operator is running, the web service can be reached via HTTP. The URL at which a service can be addressed is structured as follows:

URL for API Access (Image Source: Own Image)
Currently, only base authentication with an SAP Data Intelligence user can be used as an authentication option (username/password). Attention: The username must be specified as follows: <tenant name>/<username>. An HTTP request of a service via the tool "Postman" and the response as JSON are shown below:

HTTP Request of API Service of Vyri (Get Covid data for one county) via the tool POSTMAN (Image Source: Own Image)
6. Data Governance Capabilities
The following section deals with the data governance capabilities of Data Intelligence, looking at the creation of glossaries and data quality rules. This is just an overview of our implementation and not a guide on how to implement it. For this we can recommend the videos 3-6 of the SAP HANA Academy on Data Intelligence 3.1.
Data governance is intended to provide a unified view of the data as well as a consistent terminology. However, acronyms are not always easy and intuitive to understand. There is a need for a central and shared repository for defining terms and describing how and where the data is used. The Business Glossary allows you to create terms and categories and link them to Metadata Explorer objects. Terms provide definition and context to the data. Once the terms are defined and categorized, you can find related terms and objects when you search the glossary. This makes it easier to understand the relationship from business items and technical items used in your company.
Since we also used acronyms in our datasets, we decided to use the Business Glossary from Data Intelligence. For exemplary consideration, we have created the two glossary entries Landkreis and Source.

Glossary entries in Data intelligence (Image Source: Own Image)
Within the glossary entry, we have entered the relationship between the business term and the technical term. We have assigned the glossary entry to different records. The glossary entry Source was assigned to the tables GV_NEWS_COV_DATE and GV_NEWS_COVID. Furthermore, it was assigned to the columns Author, Sourceid, Sourcename and URL.

Selection of related objects for the respective glossary entry (Image Source: Own Image)
The glossary entries can subsequently also be found in the Data Intelligence data catalog in the datasets. Furthermore, they can also be found in the corresponding linked column details. Thus, the relationship between the business term and technical term is directly visible in the dataset.

Glossary entry linked to a database object (Image Source: Own Image)

Glossary entry linked to a table column (Image Source: Own Image)
Data quality rules
To make it possible for us to monitor the data quality of our data, we have defined rules and created dashboards to monitor the quality of the data and to view the trend of the data quality. Rules help us align data with business constraints and requirements. In combination with the Rule Books from Data Intelligence, the rules can be bound to the datasets. We did this by assigning a column to a specific parameter.
For our rules, we used the existing rule category Accuracy and did not create a new one. We created a rulebook and as an example we created two rules AGS_Team4131 and R-Value_Team4131. In the real world, of course, there would be several rules, this is just an example to show what is possible.

Rulebook in Data Intelligence (Image Source: Own Image)
For the rule R-Value_Team4131 we used the parameter R-Value. The condition here is that the R-Value is equal to or greater than 0.

Rule creation in Data Intelligence (Image Source: Own Image)
With Rule Bindings, we have the rule associated with our dataset GV_RKI_COVDATA. By mapping the parameter with the corresponding column RS, we can apply the rule to the record and the corresponding column.

Rule Binding in Data Intelligence (Image Source: Own Image)
The rule helped us to constantly check the quality of our data, so that we could make valid statements, for example about the number of COVID infected people.

Results after the rules have been executed (Image Source: Own Image)
We also created a dashboard for our rules that shows whether the dataset has passed the rules or not.

Rulebook (Image Source: Own Image)
7. Conclusion
As shown in this blog post, SAP Data Intelligence offers very powerful possibilities to integrate and manage data from various sources (SAP sources like SAP Data Warehouse Cloud, but also external data like APIs). By developing own operators using Python, JavaScript, Go or R, very broad scenarios can be implemented. Through the OpenAPI Servlow operator, an API can be provided without much effort, which can offer data from multiple sources (in our case Data Warehouse Cloud).
The data governance capabilities of Data Intelligence are also very extensive and have only been glimpsed by us. The machine learning capabilities offered by Data Intelligence were not considered in our use case but would certainly be an exciting addition.
Thank you for reading! We hope you find this post helpful and will also read the following posts in our blogpost series. For any questions or feedback just leave a comment below this post.
Best wishes,
Tim & Sebastian

Find more information and related blog posts on the topic page for SAP Data Intelligence.
If you have questions about SAP Data Intelligence you can submit them in the Q&A area for SAP Data Intelligence in the SAP Community.
- SAP Managed Tags:
- SAP Data Intelligence,
- SAP Datasphere,
- Python,
- SAP Business Technology Platform
Labels:
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
92 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
66 -
Expert
1 -
Expert Insights
177 -
Expert Insights
298 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
344 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
421 -
Workload Fluctuations
1
Related Content
- Up Net Working Capital, Up Inventory and Down Efficiency. What to do? in Technology Blogs by SAP
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 38 | |
| 25 | |
| 17 | |
| 13 | |
| 7 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |