
- SAP Community
- Products and Technology
- Financial Management
- Financial Management Blogs by SAP
- Helpful Hints for Data Sourcing Alternatives in SA...
Financial Management Blogs by SAP
Get financial management insights from blog posts by SAP experts. Find and share tips on how to increase efficiency, reduce risk, and optimize working capital.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Associate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-07-2021
11:54 AM
The story of every project experience, presales or testing activity, starts with consuming and understanding the data. Besides volume and dimensionality, the sources are a topic of interest for the whole team, from the solution architect to the technical support. In order to reduce the time needed to replicate the data from the external databases, SAP Profitability and Performance Management proudly represents a new generation of applications that do not require their own data model but can use and integrate existing data and information models from other SAP and non-SAP applications, in the cloud or on-premise.
My name is Vladan, and I am SAP Profitability and Performance Management Consultant with 4 years of experience in that field. The purpose of this blog is not to show “how” but “why”. I would like to casually discuss some pros and cons for each of the sourcing functions, so you could have a better overview and go through some decision-making process a bit faster in the future.
Let’s sketch all possible options to integrate the data from external sources or to manipulate them directly in SAP Profitability and Performance Management, as shown in the table below:
| Function Type | Model Table | Model BW | Model View | File Adapter | Model RDL |
| Available Sources | - DDIC Table - Environment - HANA Table - SDA | - Business Warehouse - Environment | - DDIC Table - DDIC View - HANA Table - HANA View - SDA - CDS View | Files available in the whitelist path on the Server (.csv, .txt) | SAP S/4 HANA optimized results data types of the Financial Products subledger data model |
| Unique Benefit | - Manual data enhancements - Time saving - Excel friendly | Leverage existing BW sources from the clients’ ERP | Connecting to the views from DDIC, HANA or CDS | Huge data volumes imported with .csv | Reading tables from a specific Result Data Layer from FPSL |
| Update data from SAP Profitability and Performance Management | Yes | Yes | No | No | No |
| Master Data & Hierarchies | Yes, locally created or imported from Excel | Yes, pulled from BW InfoObject | No | No | No |
1. Model Table
Model Table has 4 possible options for the data source, as shown in the screenshot below:

Environment is the simplest sourcing option, because it allows the creation or input of excel based file. We experienced a lot of benefits while using Environment as a source not solely because of the time saved with uploading Excel tables, but directly editing the sources in Editable Query functions on top of them. This type is more than a temporary table, used to build the modeling logic, but once logic is complete it is then advisable to use the remaining options you have below like HANA, SDA, DDIC and so on.
The possible drawbacks for using the Environment type could be :
- Manual creation of the fields before their configuration inside the model tables - if the clients have a lot of dimensions, the field creation could be time consuming activity
- The modeling user should take care of the data type while inserting the data or uploading it from Excel file - the system will throw errors if the type is not matching
If you choose Data Dictionary, HANA or SDA source, the system automatically reads the selected table and makes field proposals in the Sync Model Fields dialog when you choose Synchronize. The field state denotes whether the fields are already available or new fields are added to the environment. Very nice feature is the possibility to change the name of mapped fields and make them unique. You can also exclude certain fields from read access.

2. Model BW
Model BW as a sourcing function offers consumption of the tables that already exist in SAP ERP, besides Environment based source.

The helpful tip here would be to check so if the chosen BW InfoProvider has external HANA view set in the background. The SAP Profitability and Performance Management throws an error if you try to consume InfoProvider that does not contain it.

Other sourcing capability in this function is called Environment, intentionally! You can create a model BW from SAP Profitability and Performance Management using some standard BW InfoObjects, and activation of that newly created Model BW function will trigger creation of new BW InfoProvider in the background. The example for that is shown on the screenshot below, where the model BW with the technical function ID 05810 from SAP Profitability and Performance Management caused the creation of InfoProvider YD1010681, with the same structure. This is visible in Data Warehousing Workbench transactions, e.g. rsa1.

One of the most common usages of Model BW created from the environment is usually during SAP Profitability and Performance Management trainings, with idea to keep original data sources stable and play around the editable model BWs in order to simulate the data. The simple process for distinguishing between model tables and model BW that could be editable could be presented in this way:

The flaw of this configuration is data replication that happens into 2 functions. If you are doing the testing or proof-of-concept activities, it is way easier to create and populate Model tables with Environment fields instead of BW InfoObjects, and manipulate them directly in the editable queries.
3. Model View
Maybe the most powerful engine to integrate your model with the external data sources so far. It is very important to acknowledge that model views don’t hold any data, but just refer to an existing data source.

I guess that if you have already tried it, you have seen that HANA or SDA connection requires authorization schema. In SAP S/4 HANA system, schema is used to group logical objects tables, stored procedures, and database views. Generally speaking, not just for SAP S/4 HANA but for any other database, a schema is technically the path used for accessing database views for created objects in content development system. Let’s just say you are developing some objects in development system and schema used is Simple_schema that contains all the required tables. Simple_schema represents the authoring schema that needs to be called from your SAP Profitability and Performance Management model.
Connections from Model View are allowed for DDIC Table, DDIC View, CDS View, HANA Table, HANA View, SDA. If you don’t know by heart what are the available connections with your environment, you can check them in Connection Management application, accessible with T-code: /N/NXI/P1_CONM. Upon choosing the connection source, additional fields will be available in the connection details on the right side.
Connection Management - SAP Help Portal
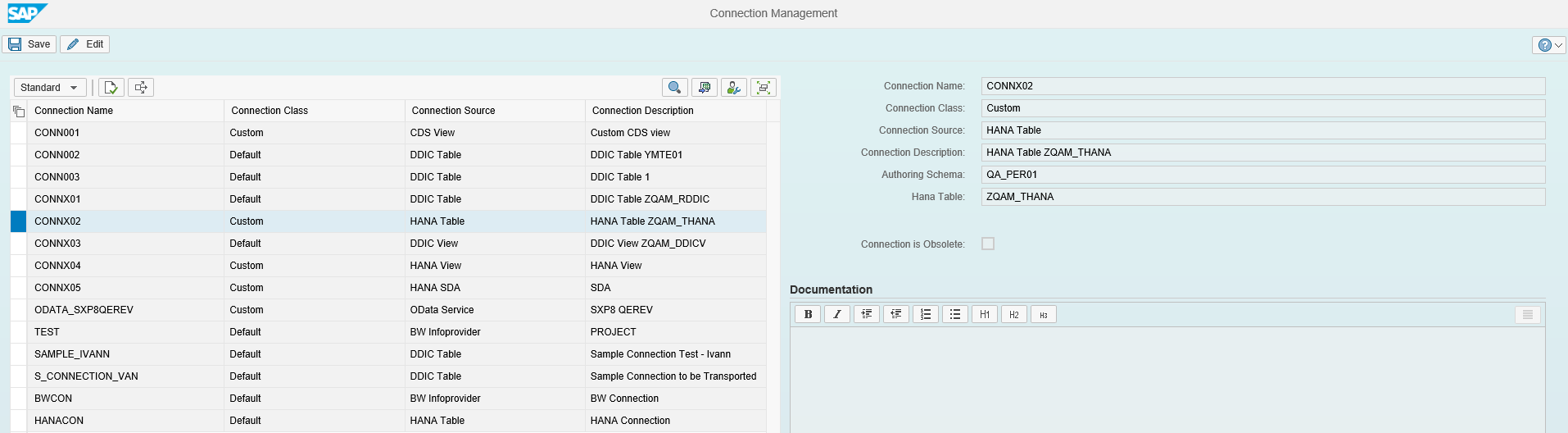
Please have in mind that not all HANA views could be consumed nicely in SAP Profitability and Performance Management, depending on their structure in the background. If HANA view is created as Composite Infoprovider, then it is possible to pull the data in SAP Profitability and Performance Management, but if it is Virtual Infoprovider of BEx Query it is not possible to consume the data. For detailed information about recommendations and restrictions regarding using these specific types of Infoproviders please take a look at these SAP notes:
- 2185212 - ADSO: Recommendations and restrictions regarding reporting - SAP ONE Support Launchpad
- 2921584 – FS-PER Rel 3.0 – Recommendations and Restrictions regarding Model BW
Important note: It is completely similar if you consume DDIC / HANA table inside of the Model View or Model Table function, as shown in the screenshots, because they are all referring to the same source in the background.


Important note: Please have in mind that you could receive this error message after clicking on Maintain Data on any function different than Model Table type Environment:

4. File Adapter:
This function is helpful in case consumption or processing of mass data from CSV or TXT file format is being planned. In case you have large data volumes that are on your local machine or they don’t exist in HANA or SDA table still, there is a way to consume them through File Adapter. A simple example of my custom .csv file that could be imported in SAP Profitability and Performance Management is shown in the screenshots below. This file needs to be uploaded to the local server of your machine, accessible through whitelist path that is set at the environment level.

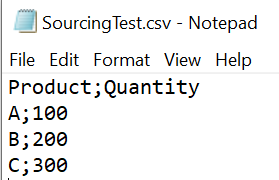


Please refer to a wonderful blog post of my colleague Justine that described this story from the back-end: Fileadapter: Whitelist path configuration for each database-system setup | SAP Blogs.
5. Model RDL
SAP Profitability and Performance Management reads data records from a specific Result Type through active and generated SQL or HANA Views. Automatically the system will consume all data records written in the HANA view.
In order to filter results with fixed selection, you have to create SAP Profitability and Performance Management processing function such as the View or Join function on top of the Model RDL.
Please reference to this official SAP Help link to Model RDL function for more information: Model RDL - SAP Help Portal
Thank you so much for your time. Hope you may find tips mentioned above useful in your everyday work, and you are now able to easily decide which alternative to use for data consumption.
If you have any questions, please use Q&A section and we will look forward to help you.
Until next time!
- SAP Managed Tags:
- SAP Profitability and Performance Management,
- SAP S/4HANA
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
Related Content
- SAP Sustainability for Financial Services - Portfolio and Solutions in Financial Management Blogs by SAP
- SAP PaPM Cloud Universal Model: Deploy your environment via Manage Containers in Financial Management Blogs by SAP
- SAP ECC Conversion to S/4HANA - Focus in CO-PA Costing-Based to Margin Analysis in Financial Management Blogs by SAP
- SAP PaPM Cloud: What’s New as of 2024-04-02? in Financial Management Blogs by SAP
- SAP PaPM Cloud: What’s New as of 2024-02-05? in Financial Management Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 3 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |