
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Tools of HANA SQL Data Warehouse
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
skahle
Discoverer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-05-2021
10:30 AM
Introduction
In my last blog post I gave an overview, which properties characterize the HANA SQL Data Warehouse approach, what it makes special, What characterises the HANA SQL Data Warehouse? | SAP Blogs.
Now with some weeks delay I want to continue and give an overview which tools are necessary or helpful to build a SAP HANA Data Warehouse with in this way.
SAP HANA SQL Data Warehousing offers a high degree of flexibility with regard to the use of different tools. The SQL approach makes it possible to use many well-known (open source) software development tools, especially in the context of the applied DevOps philosophy. But also the SAP HANA platform brings some important own tools for the development of the native SAP HANA SQL Data Warehouse.
1 SAP-HANA-Tools
The SAP HANA platform has various tools for managing and developing the platform. For building the native SAP HANA SQL Data Warehouse, these are of importance accordingly.
1.1 Data Integration
For a data warehouse, the integration of data from different source systems is a core task. After many years of classic extract, transform and load (ETL) dominating this area of data warehousing, the current trend is to transfer data only virtually into the data warehouse. In addition, new NoSQL database technologies and Big Data are playing a larger role and need to interact with an enterprise data warehouse solution. The SAP HANA platform as the basis of SAP HANA SQL Data Warehousing, which is native in this sense, has many solutions that enable on-demand and scalable data integration. For simple loading processes, the SAP Web IDE development environment (see 1 SAP HANA Tools below) is already sufficient, with which tables from source systems can be filled graphically on the basis of SQL commands. For more complex scenarios, the Enterprise Information Management (EIM) package solution and the SAP HANA Smart Data Access (SDA) service are available for integrating data.
1.1.1 Enterprise Information Management
For some years now, Enterprise Information Management has been a separate branch of information technology that deals with the consolidation and the management of structured and unstructured information in the corporate context. SAP has combined specific solutions for data management and data integration under this name. For data integration, these are the tools SAP HANA Smart Data Integration (SDI) and SAP HANA Smart Data Quality (SDQ). SDQ is an extension of SDI that cannot be used on its own. SDI is the universal ETL tool of the SAP HANA platform that can be used to connect a wide range of data sources and load data into the SAP HANA database, after transformation if necessary. Standard connectors include:
- ABAP
- SAP Business Warehouse (SAP BW)
- Database management systems (including IBM DB2, Oracle, Microsoft SQL Server, Teradata)
- SOAP and OData
- JDBC
- Appache Hive
- Microsoft Office
- Files (e.g. Microsoft Excel)
- Facebook and Twitter
SDI is fully integrated into the SAP HANA platform and can be managed through the SAP HANA Cockpit. To use it, all that is required is to install a Data Provisioning Agent on the source system and connect it with the corresponding adapter (Figure 1.1). The SAP Web IDE can then be used to create so-called flow graphs for data replication tasks, for example. SDQ helps in this process with data cleansing. In this way, data formats can be defined in a simple manner, duplicates can be identified and further specific regulations can be made to improve data quality.

Data Provisioning mit Enterprise Information Management
1.1.1 Smart Data Access
SAP HANA Smart Data Access (SDA) is the tool that enables data virtualization and makes persistent replications on the SAP HANA database obsolete. In the context of SDA, SAP therefore also speaks of a data federation technology, since the data remains in the source systems and a distributed data landscape with central access can thus be set up. SDA is essentially based on the ODBC (Open Database Connectivity) database standard, which means that all databases that support this standard can be used for SDA connections. In addition to all common database management systems, these currently include Google BigQuery, Apache Hadoop and Apache Spark. Once a connection has been created in this way, the data can be retrieved in the SAP Web IDE development environment in virtual tables that adopt the metadata of the source tables. This provides the same functionality as persistent tables, with the possibility of creating synonyms, functions and procedures.
1.2 SAP HANA XSA
SAP HANA Extended Application Services Advanced Model - XSA for short - is the integrated application server of the SAP HANA platform that provides both the development and runtime environment for HANA applications. As the name suggests, it is an evolution of the original variant, SAP HANA XS, which was added to the product just two years after the SAP HANA database was released and began the transformation to a platform. The basic idea has not changed since then. On the SAP HANA platform, the XSA application server and the SAP HANA database are located directly next to each other. This not only creates a development environment, but also brings data processing closer to the data in this architecture. This avoids the mass transfer of data between the database and application layers, which could result in speed disadvantages. In this respect, the SAP HANA platform represents a paradigm shift from the prevailing three-layer architecture to a two-layer architecture in which even complex calculations are taken over by the database layer, thereby increasing performance and efficiency. SAP HANA XSA is therefore of crucial importance for the tools described below, since the structural prerequisites of the tool functions are created with the application server. Compared to its predecessor, SAP HANA XS, the key difference is that XSA has seamless integration with SAP Cloud Platform's Cloud Foundry architecture. This makes it possible to develop on-premise and immediately run the developments in the cloud.
1.3 SAP Web IDE
SAP Web IDE is a browser-based development environment with which applications can be created full-stack, i.e. including user interface (UI), application logic and database artifacts. In this end-to-end development process, the entire lifecycle of an application can be accompanied with the SAP Web IDE. In addition to the ability to develop, the environment also supports the debugging, delivery and testing of software. SAP Web IDE runs on-premise on the SAP HANA XSA application server or is part of SAP Cloud Platform. Therefore, no additional installations are required to use it. For building the SAP HANA SQL Data Warehouse, SAP Web IDE is the central tool for developing the database artifacts. The development environment includes a number of graphical editors that can be used to easily prepare models, data logics and data streams, such as the SAP HANA-typical Calculation Views (Figure 1.2), Flowgraphs or Core Data Services. In addition to the graphical preparation, there is also the option of direct coding in the SAP HANA database language SQLScript.
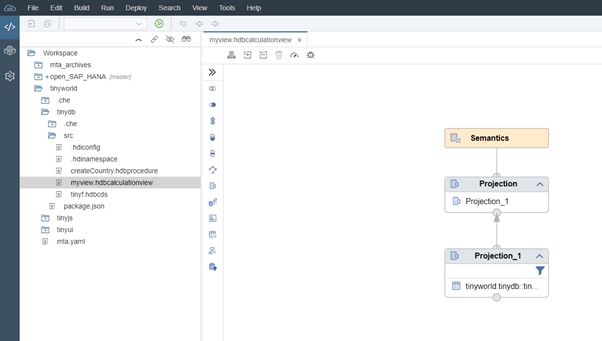
SAP Web IDE with Calculation View
1.1 SAP HANA Cockpit
SAP HANA Cockpit is the web-based administration tool for the SAP HANA platform, which can be used to perform classic administration tasks for the SAP HANA platform. Among other things, the entire SAP HANA system landscape as well as individual systems such as Tenant databases or HDI containers can be configured and monitored. System configuration includes the management of resources, services and performance. Another important aspect is the management of security measures. Settings for encryption, system maintenance and backups can be made via the SAP HANA Cockpit. In addition, a sophisticated role and user management is available.
1.2 SAP HANA Database Explorer
The SAP HANA Database Explorer links elements that are of interest from a developer and administrator perspective. It is therefore integrated into both the SAP HANA Cockpit and the SAP Web IDE. The Explorer contains the database catalog in the form of a tree structure through which the contents of the various schema or HDI containers on the database can be explored and contents can be imported and exported (Figure 1.3). In addition, an SQL Console is available for making data queries and there are options for debugging and checking log files.

SAP HANA Database Explorer
SAP PowerDesigner
SAP PowerDesigner is a tool from the field of computer-aided software engineering (CASE), in which IT-supported tools are used to design software applications and implement them as automatically as possible. SAP Powerdesigner creates solutions for the graphical analysis and modeling of business processes and their conversion into various data models. SAP HANA SQL Data Warehousing relies heavily on corresponding modeling processes and places them at the center of the construction of data warehouse structures. SAP PowerDesigner is therefore an important tool in the context of model-driven SAP HANA SQL data warehousing, although it is not part of the scope of the SAP HANA platform and must be licensed separately. The functional scope of SAP PowerDesigner is basically divided into data architecture, information architecture and enterprise architecture. However, for the SAP HANA SQL DWH, the area of data architecture with various data modeling techniques, such as conceptual, logical and physical data modeling, is particularly relevant (Figure 2.1). Of particular importance is that different models and model types can be fully integrated by the so-called link-and-synch technology. This feature, which is summarized under the keyword data lineage, makes it possible to perform impact assessments of changes across the different models and to make the entire data modeling process transparent. Updates to the database architecture are thus directly reflected in the corresponding upstream data models and vice versa. Accordingly, both a forward-looking development process, leading from conceptual considerations to the physical data model of the database, and a backward-looking process are possible.
SAP PowerDesigner ist ein Werkzeug aus dem Bereich computer-aided-software-engineering (CASE), in dem es darum geht durch den Einsatz IT-gestützter Werkzeuge Softwareanwendungen zu entwerfen und möglichst automatisiert zu implementieren. SAP Powerdesigner schafft hier Lösungen für die graphische Analyse und Modellierung von Geschäftsprozessen und ihre Umsetzung in verschiedene Datenmodelle. Das SAP HANA SQL Data Warehousing setzt stark auf entsprechende Modellierungsprozesse und stellt sie in den Mittelpunkt des Aufbaus der Data-Warehouse-Strukturen. SAP PowerDesigner ist daher ein wichtiges Tool im Rahmen des modellgetriebenen SAP HANA SQL Data Warehousing, obwohl es nicht zum Umfang der SAP-HANA-Plattform gehört und separat lizensiert werden muss. Der Funktionsumfang des SAP PowerDesigners teilt sich grundsätzlich in die Bereiche Daten-, Informations- und Unternehmensarchitektur. Für das SAP HANA SQL DWH ist jedoch vor allem der Bereich der Datenarchitektur mit verschiedenen Datenmodellierungstechniken, wie konzeptionelle, logische und physische Datenmodellierung relevant (Abbildung 2.1). Von besonderer Bedeutung ist dabei, dass sich verschiedene Modelle und Modelltypen durch die sogenannte Link-and-Synch-Technologie voll integrieren lassen. Diese Eigenschaft, die unter dem Stichwort Data-Lineage zusammengefasst wird, macht es möglich, Folgenabschätzungen von Veränderungen über die verschiedenen Modelle hinweg durchzuführen und den gesamten Prozess der Datenmodellierung transparent zu machen. Aktualisierung der Datenbankarchitektur spiegeln sich so unmittelbar in den entsprechend vorgelagerten Datenmodellen wider und andersherum. Dementsprechend ist sowohl ein vorwärts gerichtetes Entwickeln, das von konzeptionellen Erwägungen hin zum physischen Datenmodell der Datenbank führt, als auch ein rückwärts gerichteter Ablauf möglich.

Conceptional Model SAP PowerDesigner
DevOps-Tools
SAP HANA SQL Data Warehousing relies on DevOps in terms of processes and makes the advantages of this philosophy available for the development of the data warehouse. Figure 3.1 shows the typical phases of a DevOps cycle with the connection of the areas Development/Designtime and Operation/Runtime, as well as the higher-level continuity processes. These work in particular toward the highest possible degree of automation of the processes. This is supported by specific DevOps tools, which we present to you in an overview specifically for SAP HANA SQL Data Warehousing.

DevOps-Tools SAP HANA SQL Data Warehousing
1.1 Git
Git is a distributed version control system that can be regarded today in the field of agile software development as an industry standard for the joint management of source code by development teams. Such a repository is also of central importance for the DevOps philosophy with the processes of Continuous Integration, Continuous Testing and Continuous Delivery. Git technology is offered by various commercial providers, such as GitHub, GitLab or BitBucket. All these variants are very easy to integrate into the SAP Web IDE and can be used to build the SAP HANA SQL Data Warehouse. Pure cloud but also on-premise solutions are possible.
1.2 CI/CT/CD
Continuous integration, continuous testing and continuous delivery (CI/CT/CD) are among the core processes of the DevOps philosophy, which merge seamlessly into one another. In the DevOps cosmos, there are a number of tools for these processes that support the development of software, or in our case a data warehouse, on the way to a higher degree of automation. These mostly interact strongly with the already mentioned Git repository. The availability of Git in combination with the universal SQL standard of the SAP HANA platform lead to the fact that there is basically no restriction regarding the selection of specific tools. In our projects, we have had good experience with common tools such as Jenkins or Bamboo when setting up an automated deployment pipeline.
1.3 Issue Tracking
Another category that provides tools for the successful practice of DevOps is issue tracking. Appropriate tools are used to track issues in the software development lifecycle. An issue or problem can be anything of relevance, such as bugs, errors or even specific functions and features that are not yet fully developed. With the issue tracking tools, these problems can be recorded, evaluated and assigned to persons. In some cases, this is even possible automatically in conjunction with the tools in the CI/CT/CD area. In DevOps, this work takes on a high priority under the keyword Con-tinuous Feedback. User feedback in particular must be incorporated into the development lifecycle again and again and processed cleanly. Here, too, there are a number of tools that come into question. And here, too, there is basically no restriction.
2 Conclusion
In this blog, i have provided you with an overview of the essential SAP HANA SQL Data Warehousing tools. In addition to some native tools of the SAP HANA platform, there is a selection of other third-party tools available. And this is one of the great strengths of SAP HANA. With this platform we can integration non-SAP tools, e.g. open source tools like Git and Jenkins. Especially for the support of DevOps processes, the list of helpers and automation promises is long and initially a liitle bit confusing, especially for users who, due to their previous work in the data warehouse environment, have not yet had much contact with DevOps and methods of agile software development.
And one last thing: All tools and methods work in combination with HANA Cloud, except XSA. On HANA Cloud the integrated application server is Cloud Foundry, which is absolutly compatible with XSA. So using these tools and methods we are Cloud-ready.
I will give soon more info blog posts on the topic of HANA SQL Data Warehousing. I hope, you enjoyed this blog and it was a little bit helpful.
- SAP Managed Tags:
- SAP Datasphere,
- SAP HANA Cloud,
- DevOps,
- SAP HANA,
- SAP PowerDesigner,
- BW SAP HANA Data Warehousing
2 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
3 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
abapGit
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
Advanced formula
1 -
AEM
1 -
AI
8 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
3 -
API Call
2 -
API security
1 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
AS Java
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authentication
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
2 -
Azure AI Studio
1 -
Azure API Center
1 -
Azure API Management
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backpropagation
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
Bank Communication Management
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
BI
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
13 -
BTP AI Launchpad
1 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
2 -
Business Data Fabric
3 -
Business Fabric
1 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
BW4HANA
1 -
CA
1 -
calculation view
1 -
CAP
4 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation Extension for SAP Analytics Cloud
2 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
4 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
Database and Data Management
1 -
database tables
1 -
Databricks
1 -
Dataframe
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Defender
1 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Disaster Recovery
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
Entra
1 -
ESLint
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
15 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
first-guidance
1 -
Flask
2 -
FTC
1 -
Full Stack
8 -
Funds Management
1 -
gCTS
1 -
GenAI hub
1 -
General
2 -
Generative AI
1 -
Getting Started
1 -
GitHub
9 -
Google cloud
1 -
Grants Management
1 -
groovy
1 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
Hana Vector Engine
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
Infuse AI
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
9 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
4 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
MLFlow
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MTA
1 -
Multi-factor-authentication
1 -
Multi-Record Scenarios
1 -
Multilayer Perceptron
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
Neural Networks
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
3 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
Partner Built Foundation Model
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Prettier
1 -
Process Automation
2 -
Product Updates
6 -
PSM
1 -
Public Cloud
1 -
Python
5 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
rolandkramer
2 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
4 -
S4HANA Cloud
1 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
9 -
SAP AI Launchpad
8 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
4 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP API Management
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BTP
23 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
7 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Generative AI
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP BTPEA
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HANA PAL
1 -
SAP HANA Vector
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
9 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
2 -
SAP PAL
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP Router
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
2 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapfirstguidance
3 -
SAPHANAService
1 -
SAPIQ
2 -
sapmentors
1 -
saponaws
2 -
saprouter
1 -
SAPRouter installation
1 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
service
1 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
soap
1 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
15 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Testing
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
3 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Vectorization
1 -
Visual Studio Code
1 -
VSCode
2 -
VSCode extenions
1 -
Vulnerabilities
1 -
Web SDK
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- What’s New in SAP Analytics Cloud Q2 2024 in Technology Blogs by SAP
- How to generate a wrapper for function modules (BAPIs) in tier 2 in Technology Blogs by SAP
- DevOps with SAP BTP in Technology Blogs by SAP
- SAP CAP Java hybrid development in BAS in Technology Q&A
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 7 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 7 | |
| 6 | |
| 5 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 2 | |
| 2 |