
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Services and SAP Data Intelligence: Optim...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
shibajee_dutta_
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-08-2021
6:35 PM
The Hybrid context
The hybrid data management provides the data integration users, best of the on premise and cloud world with a fully integrated solution meeting the needs of classic ETL, data quality and intelligent data management and while also enabling the use of technologies indigenously in a mutually exclusive method. SAP’s hybrid data management solution enables the existing SAP Data Management user base with the following:
- Continue to use the existing SAP Data Services contents and assets in SAP Data Intelligence Cloud.
- Huge value addition by bridging the unique capabilities of both SAP Data Services and SAP Data Intelligence Cloud. Take advantage of common functionalities in a distributed processing architecture
- Improved user experience for the existing SAP Data Services users with the usability extended into SAP Data Intelligence Cloud.
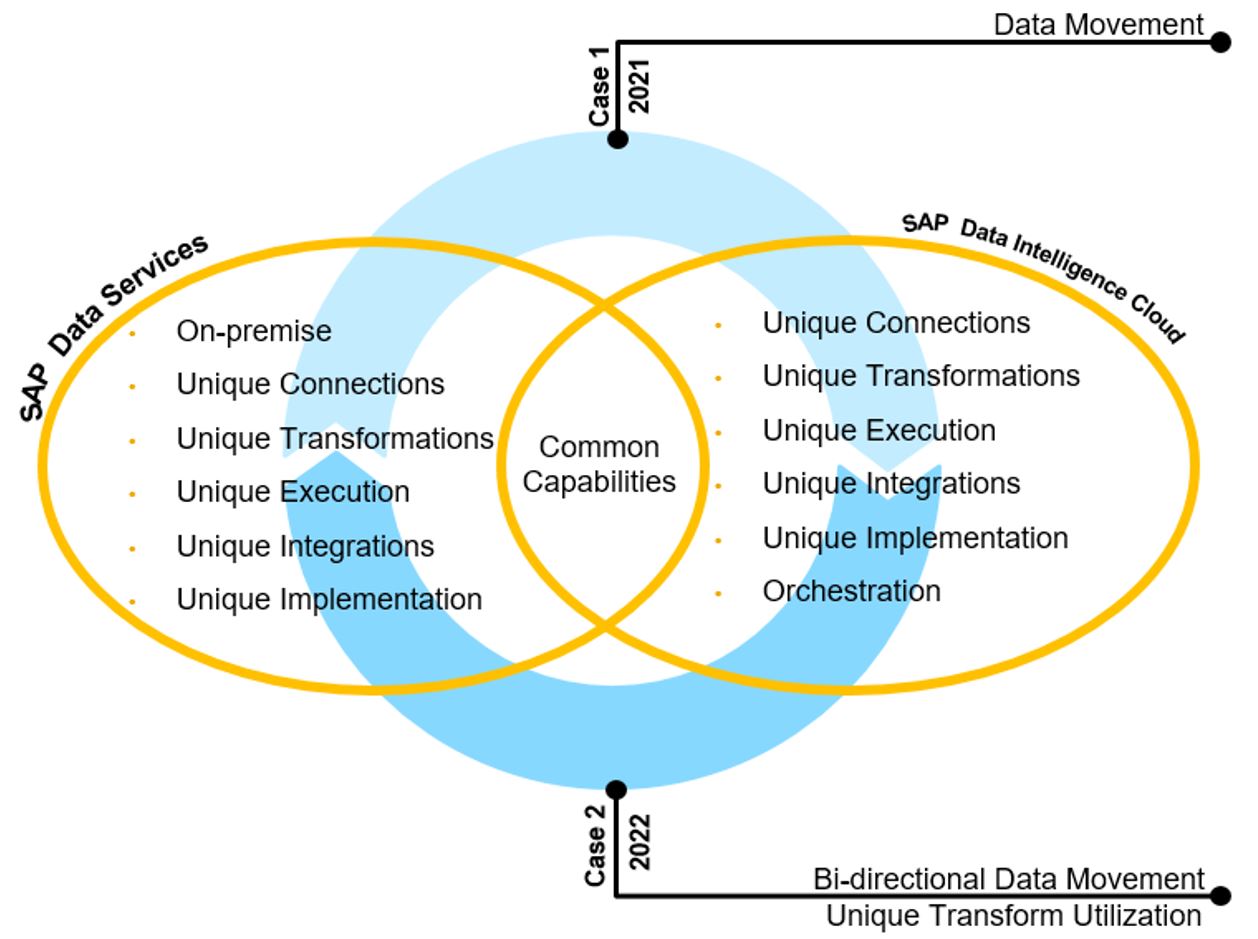
Fig 1.0
Scope of the SAP Data Services and SAP Data Intelligence Cloud hybrid solution
- Orchestration of SAP Data Services jobs as a part of the Data Intelligence Cloud data pipelines (currently available).
- Move enriched and transformed legacy and enterprise, table type data directly from the SAP Data Services datastores (SAP Data Services Connection Object) and consume in SAP Data Intelligence Cloud. (Planned for 2021. Supports unique targets found in SAP Data Intelligence Cloud only).
- Bi-directional data movement between SAP Data Intelligence Cloud and SAP Data Services to utilize unique data transformation and data enrichment in SAP Data Services. Our plans are to fully utilize other unique transforms from SAP Data Intelligence Cloud and SAP Data Services (Planned for 2022).
Use Case 1 – Scenario
- Move enriched and transformed data, by SAP Data Services with its supported RDBMS based legacy and enterprise analytical data system into cloud-based SAP Data Intelligence Cloud supported connection.
- Modelling and configuration is performed in SAP Data Intelligence Cloud. In SAP Data Intelligence Cloud there is a new operator Data Services Transform. This operator accepts user inputs for generating SAP Data Services executable code and pushes it to the existing on-premise SAP Data Services infrastructure and procures the data to be consumed in SAP Data Intelligence Cloud. Note: There is zero configuration required in the existing SAP Data Services infrastructure.
- Source and Target:
- Source is on premise. In this case we are using an SAP Data Services datastore, which is pre-configured and being used by existing SAP Data Services batch dataflows to populate, enriched, and transformed data. This datastore is the source connection, which in turn is pointing to an Oracle database. Note: From SAP Data Intelligence perspective SAP Data Services datastore is the source and not the underlying database connection. Please refer to fig 2.0
- Target is in cloud. In this case we will be using SAP Data Intelligence Cloud connection pointing to Kafka. Kafka connectivity is unique in SAP Data Intelligence Cloud. Note: There is a relational type data to message type data conversion occurs seamlessly in the background based on SAP Data Intelligence Cloud smart design.
Functional architecture and requirements

Fig 2.0
Requirements:
- SAP Data Services 4.2 SP 14 Patch 13 or above
- SAP Data Intelligence Cloud 2107
- Configure and identify the SAP Data Services connection in SAP Data Intelligence Cloud
- Identify the SAP Data Services repository and required datastore to be used as source
- Identify the SAP Data Intelligence Cloud connection to be used as target
- As per Fig 3.0 below SAP Cloud Connector installation is required in the SAP Data Services environment
Graph design and execution:
Step 1: In SAP Data Intelligence Cloud modelling tool, build a graph using SAP Data Services Transform
Step 2: Execute graph. The system will generate the required code, push it down to SAP Data Services and execute the code within the SAP Data Services engine
Step 3: SAP Data Services will produce the output dataset and move it to SAP Data Intelligence Cloud
Step 4: SAP Data Intelligence Cloud will execute its processing sub engine to write the data into the SAP Data Intelligence Cloud connection
Technical architecture
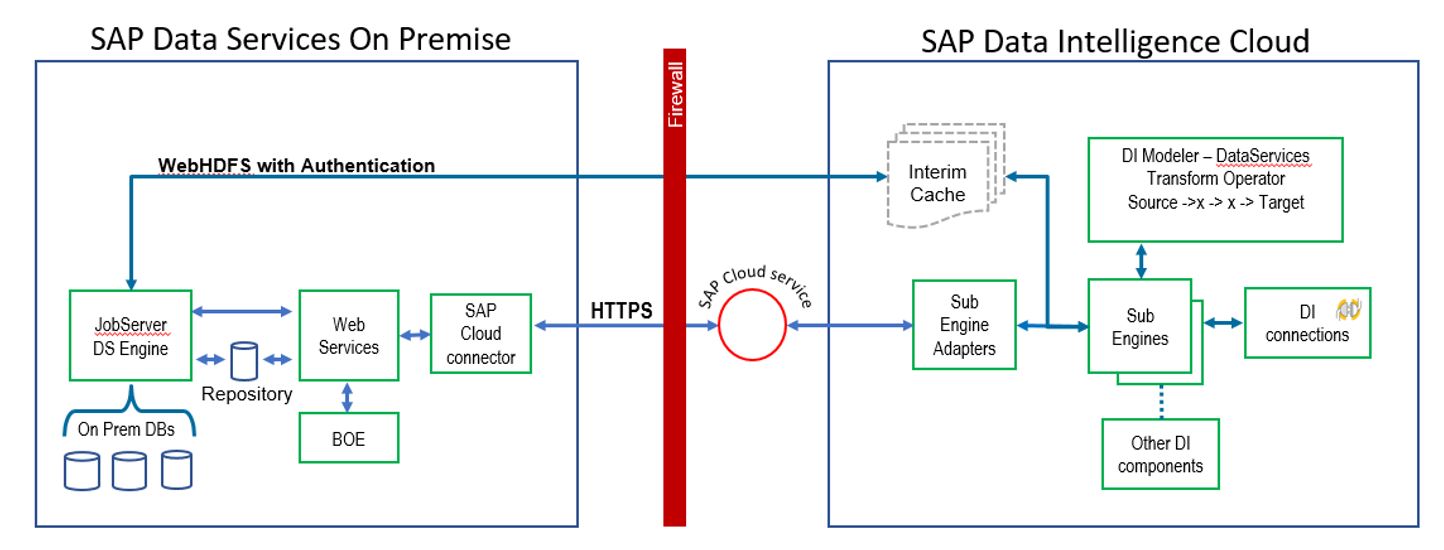
Fig 3.0
Benefits of this hybrid data management solution
- The assets built on and around SAP Data Services can be efficiently reused by the cloud, so that user does not have to rebuild any existing assets.
- This solution bridges the gap between the unique capabilities supported between the on-premises and cloud solution
- Cloud based user experience expands the on-premises tested and trusted capabilities.
- SAP Data Intelligence Cloud supports orchestration of SAP Data Services jobs, which helps in remotely invoking an existing job and producing the output. This hybrid approach minimizes complete execution of SAP Data Services jobs each time and helps consume the required data slice.
- The paradigm shift is within the information consumption method. In the on-premises solution, user goes to the information repository to get their required slice for decision making. With this hybrid use case, the required (subscribed) slice of information can potentially go to the user.
- The SAP Data Services on-premises implementation has no configuration change, thus allowing the ongoing SAP Data Services assets to run as is. This means zero disruption in running the business yet expanding the data outreach
- Enables expanded and distributed processing power and opens the scope of handling a wide range of data formats and data transformation between on-premises and cloud applications.
- Existing skill set has a very low learning curve. This also helps gradual skill sharpening with the rapid evolution of SAP Data Intelligence Cloud
- With the adoption of SAP Data Intelligence Cloud, the hybrid data management solution allows to future-proof user projects, relying on SAP’s strategic solution for cloud data management.
The evolution roadmap of the SAP data management platform and SAP Data Intelligence Cloud
Please refer to the corresponding blog here: https://blogs.sap.com/2021/08/03/sap-data-services-sap-information-steward-and-sap-data-intelligence...
Is there a user story or video or both available?
Please follow this link for a demonstration video of the SAP Data Services and SAP Data Intelligence Hybrid Data Management
- SAP Managed Tags:
- SAP Data Intelligence,
- SAP Data Services,
- Partnership,
- SAP Business Technology Platform
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,661 -
Business Trends
87 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
64 -
Expert
1 -
Expert Insights
178 -
Expert Insights
275 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
Kafka
1 -
Life at SAP
784 -
Life at SAP
11 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
329 -
Replication Flow
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,886 -
Technology Updates
407 -
Workload Fluctuations
1
Related Content
- Unify your process and task mining insights: How SAP UEM by Knoa integrates with SAP Signavio in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 4 Interview in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Top Picks: Innovations Highlights from SAP Business Technology Platform (Q1/2024) in Technology Blogs by SAP
- Unlocking Full-Stack Potential using SAP build code - Part 1 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 13 | |
| 10 | |
| 10 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |